 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance of AI agents based on reasoning language models on ALD process optimization tasks
Jan 15, 2026In this work we explore the performance and behavior of reasoning large language models to autonomously optimize atomic layer deposition (ALD) processes. In the ALD process optimization task, an agent built on top of a reasoning LLM has to find optimal dose times for an ALD precursor and a coreactant without any prior knowledge on the process, including whether it is actually self-limited. The agent is meant to interact iteratively with an ALD reactor in a fully unsupervised way. We evaluate this agent using a simple model of an ALD tool that incorporates ALD processes with different self-limited surface reaction pathways as well as a non self-limited component. Our results show that agents based on reasoning models like OpenAI's o3 and GPT5 consistently succeeded at completing this optimization task. However, we observed significant run-to-run variability due to the non deterministic nature of the model's response. In order to understand the logic followed by the reasoning model, the agent uses a two step process in which the model first generates an open response detailing the reasoning process. This response is then transformed into a structured output. An analysis of these reasoning traces showed that the logic of the model was sound and that its reasoning was based on the notions of self-limited process and saturation expected in the case of ALD. However, the agent can sometimes be misled by its own prior choices when exploring the optimization space.
Surrogate models to optimize plasma assisted atomic layer deposition in high aspect ratio features
Jun 11, 2025In this work we explore surrogate models to optimize plasma enhanced atomic layer deposition (PEALD) in high aspect ratio features. In plasma-based processes such as PEALD and atomic layer etching, surface recombination can dominate the reactivity of plasma species with the surface, which can lead to unfeasibly long exposure times to achieve full conformality inside nanostructures like high aspect ratio vias. Using a synthetic dataset based on simulations of PEALD, we train artificial neural networks to predict saturation times based on cross section thickness data obtained for partially coated conditions. The results obtained show that just two experiments in undersaturated conditions contain enough information to predict saturation times within 10% of the ground truth. A surrogate model trained to determine whether surface recombination dominates the plasma-surface interactions in a PEALD process achieves 99% accuracy. This demonstrates that machine learning can provide a new pathway to accelerate the optimization of PEALD processes in areas such as microelectronics. Our approach can be easily extended to atomic layer etching and more complex structures.
EAIRA: Establishing a Methodology for Evaluating AI Models as Scientific Research Assistants
Feb 27, 2025Recent advancements have positioned AI, and particularly Large Language Models (LLMs), as transformative tools for scientific research, capable of addressing complex tasks that require reasoning, problem-solving, and decision-making. Their exceptional capabilities suggest their potential as scientific research assistants but also highlight the need for holistic, rigorous, and domain-specific evaluation to assess effectiveness in real-world scientific applications. This paper describes a multifaceted methodology for Evaluating AI models as scientific Research Assistants (EAIRA) developed at Argonne National Laboratory. This methodology incorporates four primary classes of evaluations. 1) Multiple Choice Questions to assess factual recall; 2) Open Response to evaluate advanced reasoning and problem-solving skills; 3) Lab-Style Experiments involving detailed analysis of capabilities as research assistants in controlled environments; and 4) Field-Style Experiments to capture researcher-LLM interactions at scale in a wide range of scientific domains and applications. These complementary methods enable a comprehensive analysis of LLM strengths and weaknesses with respect to their scientific knowledge, reasoning abilities, and adaptability. Recognizing the rapid pace of LLM advancements, we designed the methodology to evolve and adapt so as to ensure its continued relevance and applicability. This paper describes the methodology state at the end of February 2025. Although developed within a subset of scientific domains, the methodology is designed to be generalizable to a wide range of scientific domains.
Design Principles for Lifelong Learning AI Accelerators
Oct 05, 2023Lifelong learning - an agent's ability to learn throughout its lifetime - is a hallmark of biological learning systems and a central challenge for artificial intelligence (AI). The development of lifelong learning algorithms could lead to a range of novel AI applications, but this will also require the development of appropriate hardware accelerators, particularly if the models are to be deployed on edge platforms, which have strict size, weight, and power constraints. Here, we explore the design of lifelong learning AI accelerators that are intended for deployment in untethered environments. We identify key desirable capabilities for lifelong learning accelerators and highlight metrics to evaluate such accelerators. We then discuss current edge AI accelerators and explore the future design of lifelong learning accelerators, considering the role that different emerging technologies could play.
Improving Performance in Continual Learning Tasks using Bio-Inspired Architectures
Aug 08, 2023The ability to learn continuously from an incoming data stream without catastrophic forgetting is critical to designing intelligent systems. Many approaches to continual learning rely on stochastic gradient descent and its variants that employ global error updates, and hence need to adopt strategies such as memory buffers or replay to circumvent its stability, greed, and short-term memory limitations. To address this limitation, we have developed a biologically inspired lightweight neural network architecture that incorporates synaptic plasticity mechanisms and neuromodulation and hence learns through local error signals to enable online continual learning without stochastic gradient descent. Our approach leads to superior online continual learning performance on Split-MNIST, Split-CIFAR-10, and Split-CIFAR-100 datasets compared to other memory-constrained learning approaches and matches that of the state-of-the-art memory-intensive replay-based approaches. We further demonstrate the effectiveness of our approach by integrating key design concepts into other backpropagation-based continual learning algorithms, significantly improving their accuracy. Our results provide compelling evidence for the importance of incorporating biological principles into machine learning models and offer insights into how we can leverage them to design more efficient and robust systems for online continual learning.
AutoML for neuromorphic computing and application-driven co-design: asynchronous, massively parallel optimization of spiking architectures
Feb 26, 2023In this work we have extended AutoML inspired approaches to the exploration and optimization of neuromorphic architectures. Through the integration of a parallel asynchronous model-based search approach with a simulation framework to simulate spiking architectures, we are able to efficiently explore the configuration space of neuromorphic architectures and identify the subset of conditions leading to the highest performance in a targeted application. We have demonstrated this approach on an exemplar case of real time, on-chip learning application. Our results indicate that we can effectively use optimization approaches to optimize complex architectures, therefore providing a viable pathway towards application-driven codesign.
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023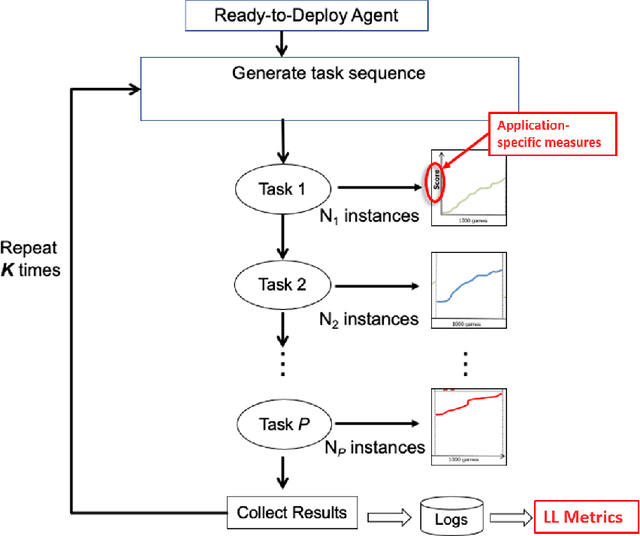
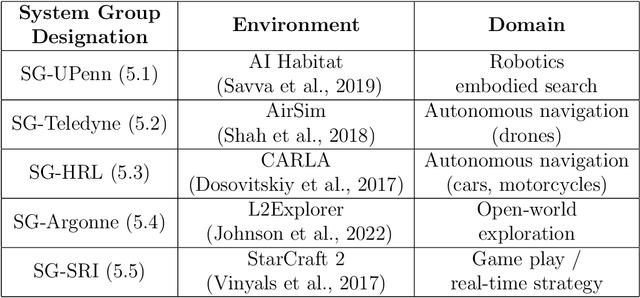


Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
General policy mapping: online continual reinforcement learning inspired on the insect brain
Nov 30, 2022

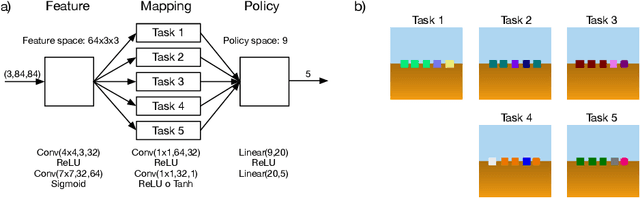

We have developed a model for online continual or lifelong reinforcement learning (RL) inspired on the insect brain. Our model leverages the offline training of a feature extraction and a common general policy layer to enable the convergence of RL algorithms in online settings. Sharing a common policy layer across tasks leads to positive backward transfer, where the agent continuously improved in older tasks sharing the same underlying general policy. Biologically inspired restrictions to the agent's network are key for the convergence of RL algorithms. This provides a pathway towards efficient online RL in resource-constrained scenarios.
Machine learning and atomic layer deposition: predicting saturation times from reactor growth profiles using artificial neural networks
May 10, 2022

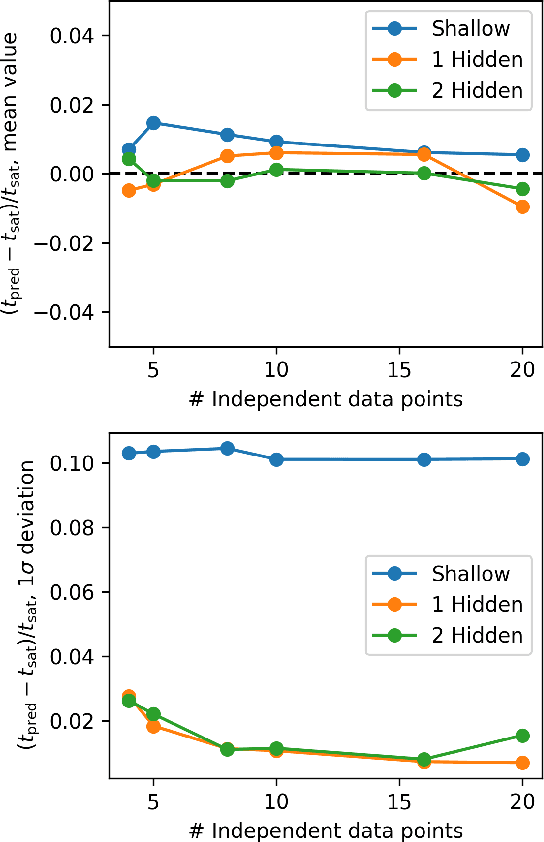

In this work we explore the application of deep neural networks to the optimization of atomic layer deposition processes based on thickness values obtained at different points of an ALD reactor. We introduce a dataset designed to train neural networks to predict saturation times based on the dose time and thickness values measured at different points of the reactor for a single experimental condition. We then explore different artificial neural network configurations, including depth (number of hidden layers) and size (number of neurons in each layers) to better understand the size and complexity that neural networks should have to achieve high predictive accuracy. The results obtained show that trained neural networks can accurately predict saturation times without requiring any prior information on the surface kinetics. This provides a viable approach to minimize the number of experiments required to optimize new ALD processes in a known reactor. However, the datasets and training procedure depend on the reactor geometry.
Fast, Smart Neuromorphic Sensors Based on Heterogeneous Networks and Mixed Encodings
Apr 09, 2021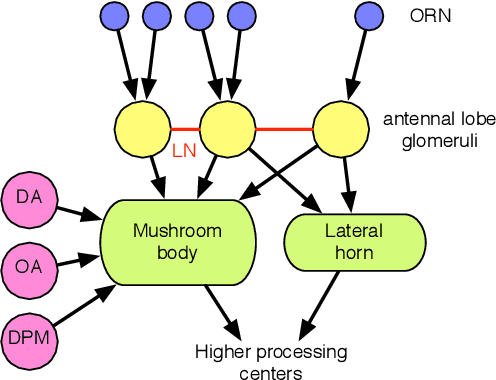
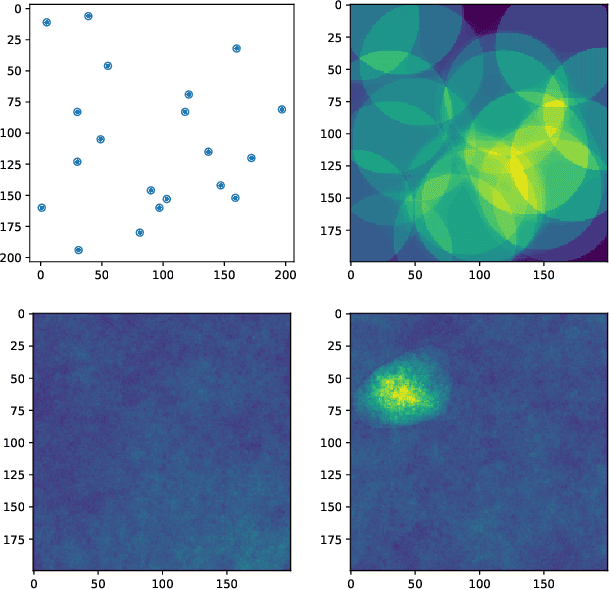

Neuromorphic architectures are ideally suited for the implementation of smart sensors able to react, learn, and respond to a changing environment. Our work uses the insect brain as a model to understand how heterogeneous architectures, incorporating different types of neurons and encodings, can be leveraged to create systems integrating input processing, evaluation, and response. Here we show how the combination of time and rate encodings can lead to fast sensors that are able to generate a hypothesis on the input in only a few cycles and then use that hypothesis as secondary input for more detailed analysis.