 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2RU: Memristive Minion Recurrent Unit for On-Chip Continual Learning at the Edge
Dec 26, 2025Continual learning on edge platforms remains challenging because recurrent networks depend on energy-intensive training procedures and frequent data movement that are impractical for embedded deployments. This work introduces M2RU, a mixed-signal architecture that implements the minion recurrent unit for efficient temporal processing with on-chip continual learning. The architecture integrates weighted-bit streaming, which enables multi-bit digital inputs to be processed in crossbars without high-resolution conversion, and an experience replay mechanism that stabilizes learning under domain shifts. M2RU achieves 15 GOPS at 48.62 mW, corresponding to 312 GOPS per watt, and maintains accuracy within 5 percent of software baselines on sequential MNIST and CIFAR-10 tasks. Compared with a CMOS digital design, the accelerator provides 29X improvement in energy efficiency. Device-aware analysis shows an expected operational lifetime of 12.2 years under continual learning workloads. These results establish M2RU as a scalable and energy-efficient platform for real-time adaptation in edge-level temporal intelligence.
M2RU: Memristive Minion Recurrent Unit for Continual Learning at the Edge
Dec 19, 2025Continual learning on edge platforms remains challenging because recurrent networks depend on energy-intensive training procedures and frequent data movement that are impractical for embedded deployments. This work introduces M2RU, a mixed-signal architecture that implements the minion recurrent unit for efficient temporal processing with on-chip continual learning. The architecture integrates weighted-bit streaming, which enables multi-bit digital inputs to be processed in crossbars without high-resolution conversion, and an experience replay mechanism that stabilizes learning under domain shifts. M2RU achieves 15 GOPS at 48.62 mW, corresponding to 312 GOPS per watt, and maintains accuracy within 5 percent of software baselines on sequential MNIST and CIFAR-10 tasks. Compared with a CMOS digital design, the accelerator provides 29X improvement in energy efficiency. Device-aware analysis shows an expected operational lifetime of 12.2 years under continual learning workloads. These results establish M2RU as a scalable and energy-efficient platform for real-time adaptation in edge-level temporal intelligence.
Minion Gated Recurrent Unit for Continual Learning
Mar 08, 2025The increasing demand for continual learning in sequential data processing has led to progressively complex training methodologies and larger recurrent network architectures. Consequently, this has widened the knowledge gap between continual learning with recurrent neural networks (RNNs) and their ability to operate on devices with limited memory and compute. To address this challenge, we investigate the effectiveness of simplifying RNN architectures, particularly gated recurrent unit (GRU), and its impact on both single-task and multitask sequential learning. We propose a new variant of GRU, namely the minion recurrent unit (MiRU). MiRU replaces conventional gating mechanisms with scaling coefficients to regulate dynamic updates of hidden states and historical context, reducing computational costs and memory requirements. Despite its simplified architecture, MiRU maintains performance comparable to the standard GRU while achieving 2.90x faster training and reducing parameter usage by 2.88x, as demonstrated through evaluations on sequential image classification and natural language processing benchmarks. The impact of model simplification on its learning capacity is also investigated by performing continual learning tasks with a rehearsal-based strategy and global inhibition. We find that MiRU demonstrates stable performance in multitask learning even when using only rehearsal, unlike the standard GRU and its variants. These features position MiRU as a promising candidate for edge-device applications.
Time-Series Forecasting and Sequence Learning Using Memristor-based Reservoir System
May 22, 2024Pushing the frontiers of time-series information processing in ever-growing edge devices with stringent resources has been impeded by the system's ability to process information and learn locally on the device. Local processing and learning typically demand intensive computations and massive storage as the process involves retrieving information and tuning hundreds of parameters back in time. In this work, we developed a memristor-based echo state network accelerator that features efficient temporal data processing and in-situ online learning. The proposed design is benchmarked using various datasets involving real-world tasks, such as forecasting the load energy consumption and weather conditions. The experimental results illustrate that the hardware model experiences a marginal degradation (~4.8%) in performance as compared to the software model. This is mainly attributed to the limited precision and dynamic range of network parameters when emulated using memristor devices. The proposed system is evaluated for lifespan, robustness, and energy-delay product. It is observed that the system demonstrates a reasonable robustness for device failure below 10%, which may occur due to stuck-at faults. Furthermore, 246X reduction in energy consumption is achieved when compared to a custom CMOS digital design implemented at the same technology node.
Design Principles for Lifelong Learning AI Accelerators
Oct 05, 2023Lifelong learning - an agent's ability to learn throughout its lifetime - is a hallmark of biological learning systems and a central challenge for artificial intelligence (AI). The development of lifelong learning algorithms could lead to a range of novel AI applications, but this will also require the development of appropriate hardware accelerators, particularly if the models are to be deployed on edge platforms, which have strict size, weight, and power constraints. Here, we explore the design of lifelong learning AI accelerators that are intended for deployment in untethered environments. We identify key desirable capabilities for lifelong learning accelerators and highlight metrics to evaluate such accelerators. We then discuss current edge AI accelerators and explore the future design of lifelong learning accelerators, considering the role that different emerging technologies could play.
End-to-End Memristive HTM System for Pattern Recognition and Sequence Prediction
Jun 22, 2020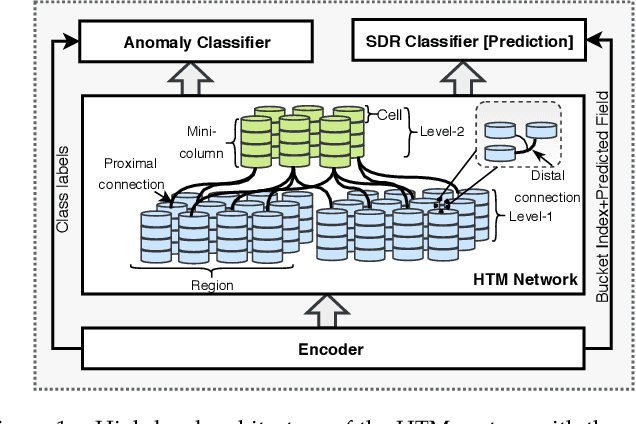
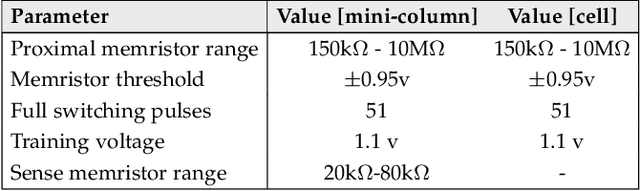
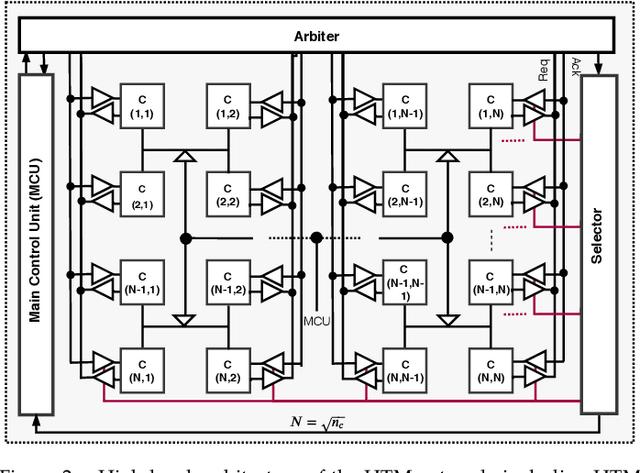
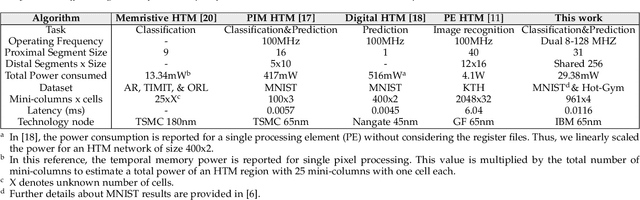
Neuromorphic systems that learn and predict from streaming inputs hold significant promise in pervasive edge computing and its applications. In this paper, a neuromorphic system that processes spatio-temporal information on the edge is proposed. Algorithmically, the system is based on hierarchical temporal memory that inherently offers online learning, resiliency, and fault tolerance. Architecturally, it is a full custom mixed-signal design with an underlying digital communication scheme and analog computational modules. Therefore, the proposed system features reconfigurability, real-time processing, low power consumption, and low-latency processing. The proposed architecture is benchmarked to predict on real-world streaming data. The network's mean absolute percentage error on the mixed-signal system is 1.129X lower compared to its baseline algorithm model. This reduction can be attributed to device non-idealities and probabilistic formation of synaptic connections. We demonstrate that the combined effect of Hebbian learning and network sparsity also plays a major role in extending the overall network lifespan. We also illustrate that the system offers 3.46X reduction in latency and 77.02X reduction in power consumption when compared to a custom CMOS digital design implemented at the same technology node. By employing specific low power techniques, such as clock gating, we observe 161.37X reduction in power consumption.
Metaplasticity in Multistate Memristor Synaptic Networks
Feb 26, 2020

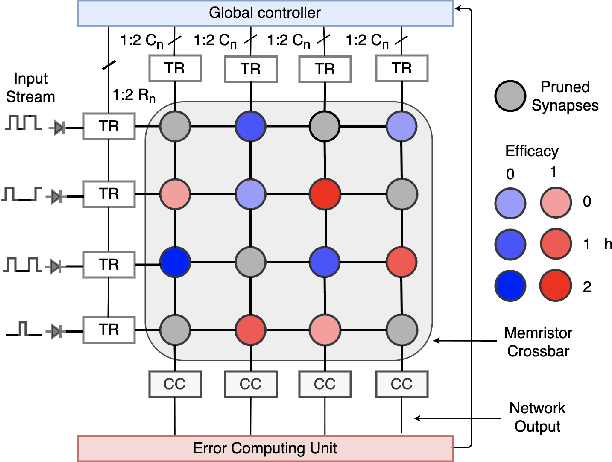
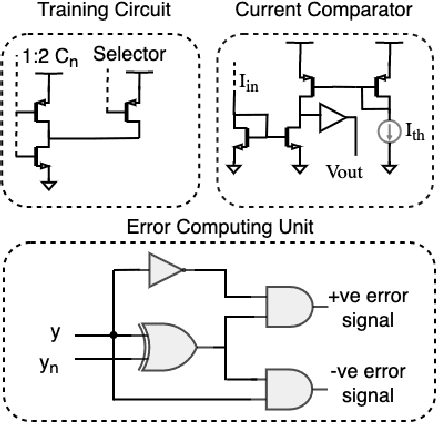
Recent studies have shown that metaplastic synapses can retain information longer than simple binary synapses and are beneficial for continual learning. In this paper, we explore the multistate metaplastic synapse characteristics in the context of high retention and reception of information. Inherent behavior of a memristor emulating the multistate synapse is employed to capture the metaplastic behavior. An integrated neural network study for learning and memory retention is performed by integrating the synapse in a $5\times3$ crossbar at the circuit level and $128\times128$ network at the architectural level. An on-device training circuitry ensures the dynamic learning in the network. In the $128\times128$ network, it is observed that the number of input patterns the multistate synapse can classify is $\simeq$ 2.1x that of a simple binary synapse model, at a mean accuracy of $\geq$ 75% .
Neuromemrisitive Architecture of HTM with On-Device Learning and Neurogenesis
Dec 27, 2018


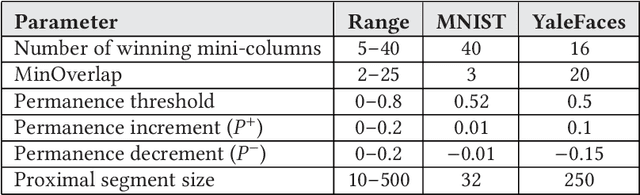
Hierarchical temporal memory (HTM) is a biomimetic sequence memory algorithm that holds promise for invariant representations of spatial and spatiotemporal inputs. This paper presents a comprehensive neuromemristive crossbar architecture for the spatial pooler (SP) and the sparse distributed representation classifier, which are fundamental to the algorithm. There are several unique features in the proposed architecture that tightly link with the HTM algorithm. A memristor that is suitable for emulating the HTM synapses is identified and a new Z-window function is proposed. The architecture exploits the concept of synthetic synapses to enable potential synapses in the HTM. The crossbar for the SP avoids dark spots caused by unutilized crossbar regions and supports rapid on-chip training within 2 clock cycles. This research also leverages plasticity mechanisms such as neurogenesis and homeostatic intrinsic plasticity to strengthen the robustness and performance of the SP. The proposed design is benchmarked for image recognition tasks using MNIST and Yale faces datasets, and is evaluated using different metrics including entropy, sparseness, and noise robustness. Detailed power analysis at different stages of the SP operations is performed to demonstrate the suitability for mobile platforms.
Neuromorphic Architecture for the Hierarchical Temporal Memory
Aug 17, 2018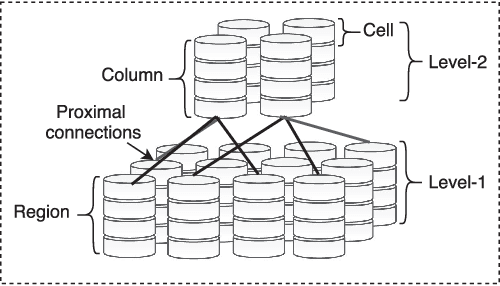



A biomimetic machine intelligence algorithm, that holds promise in creating invariant representations of spatiotemporal input streams is the hierarchical temporal memory (HTM). This unsupervised online algorithm has been demonstrated on several machine-learning tasks, including anomaly detection. Significant effort has been made in formalizing and applying the HTM algorithm to different classes of problems. There are few early explorations of the HTM hardware architecture, especially for the earlier version of the spatial pooler of HTM algorithm. In this article, we present a full-scale HTM architecture for both spatial pooler and temporal memory. Synthetic synapse design is proposed to address the potential and dynamic interconnections occurring during learning. The architecture is interweaved with parallel cells and columns that enable high processing speed for the HTM. The proposed architecture is verified for two different datasets: MNIST and the European number plate font (EUNF), with and without the presence of noise. The spatial pooler architecture is synthesized on Xilinx ZYNQ-7, with 91.16% classification accuracy for MNIST and 90\% accuracy for EUNF, with noise. For the temporal memory sequence prediction, first and second order predictions are observed for a 5-number long sequence generated from EUNF dataset and 95% accuracy is obtained. Moreover, the proposed hardware architecture offers 1364X speedup over the software realization. These results indicate that the proposed architecture can serve as a digital core to build the HTM in hardware and eventually as a standalone self-learning system.