Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral policy mapping: online continual reinforcement learning inspired on the insect brain
Paper and Code


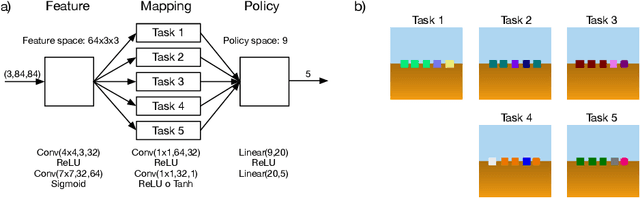

We have developed a model for online continual or lifelong reinforcement learning (RL) inspired on the insect brain. Our model leverages the offline training of a feature extraction and a common general policy layer to enable the convergence of RL algorithms in online settings. Sharing a common policy layer across tasks leads to positive backward transfer, where the agent continuously improved in older tasks sharing the same underlying general policy. Biologically inspired restrictions to the agent's network are key for the convergence of RL algorithms. This provides a pathway towards efficient online RL in resource-constrained scenarios.
View paper on
 OpenReview
OpenReview