 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEAIRA: Establishing a Methodology for Evaluating AI Models as Scientific Research Assistants
Feb 27, 2025Recent advancements have positioned AI, and particularly Large Language Models (LLMs), as transformative tools for scientific research, capable of addressing complex tasks that require reasoning, problem-solving, and decision-making. Their exceptional capabilities suggest their potential as scientific research assistants but also highlight the need for holistic, rigorous, and domain-specific evaluation to assess effectiveness in real-world scientific applications. This paper describes a multifaceted methodology for Evaluating AI models as scientific Research Assistants (EAIRA) developed at Argonne National Laboratory. This methodology incorporates four primary classes of evaluations. 1) Multiple Choice Questions to assess factual recall; 2) Open Response to evaluate advanced reasoning and problem-solving skills; 3) Lab-Style Experiments involving detailed analysis of capabilities as research assistants in controlled environments; and 4) Field-Style Experiments to capture researcher-LLM interactions at scale in a wide range of scientific domains and applications. These complementary methods enable a comprehensive analysis of LLM strengths and weaknesses with respect to their scientific knowledge, reasoning abilities, and adaptability. Recognizing the rapid pace of LLM advancements, we designed the methodology to evolve and adapt so as to ensure its continued relevance and applicability. This paper describes the methodology state at the end of February 2025. Although developed within a subset of scientific domains, the methodology is designed to be generalizable to a wide range of scientific domains.
Scaling Large Vision-Language Models for Enhanced Multimodal Comprehension In Biomedical Image Analysis
Jan 26, 2025Large language models (LLMs) have demonstrated immense capabilities in understanding textual data and are increasingly being adopted to help researchers accelerate scientific discovery through knowledge extraction (information retrieval), knowledge distillation (summarizing key findings and methodologies into concise forms), and knowledge synthesis (aggregating information from multiple scientific sources to address complex queries, generate hypothesis and formulate experimental plans). However, scientific data often exists in both visual and textual modalities. Vision language models (VLMs) address this by incorporating a pretrained vision backbone for processing images and a cross-modal projector that adapts image tokens into the LLM dimensional space, thereby providing richer multimodal comprehension. Nevertheless, off-the-shelf VLMs show limited capabilities in handling domain-specific data and are prone to hallucinations. We developed intelligent assistants finetuned from LLaVA models to enhance multimodal understanding in low-dose radiation therapy (LDRT)-a benign approach used in the treatment of cancer-related illnesses. Using multilingual data from 42,673 articles, we devise complex reasoning and detailed description tasks for visual question answering (VQA) benchmarks. Our assistants, trained on 50,882 image-text pairs, demonstrate superior performance over base models as evaluated using LLM-as-a-judge approach, particularly in reducing hallucination and improving domain-specific comprehension.
Surgical tool classification and localization: results and methods from the MICCAI 2022 SurgToolLoc challenge
May 11, 2023



The ability to automatically detect and track surgical instruments in endoscopic videos can enable transformational interventions. Assessing surgical performance and efficiency, identifying skilled tool use and choreography, and planning operational and logistical aspects of OR resources are just a few of the applications that could benefit. Unfortunately, obtaining the annotations needed to train machine learning models to identify and localize surgical tools is a difficult task. Annotating bounding boxes frame-by-frame is tedious and time-consuming, yet large amounts of data with a wide variety of surgical tools and surgeries must be captured for robust training. Moreover, ongoing annotator training is needed to stay up to date with surgical instrument innovation. In robotic-assisted surgery, however, potentially informative data like timestamps of instrument installation and removal can be programmatically harvested. The ability to rely on tool installation data alone would significantly reduce the workload to train robust tool-tracking models. With this motivation in mind we invited the surgical data science community to participate in the challenge, SurgToolLoc 2022. The goal was to leverage tool presence data as weak labels for machine learning models trained to detect tools and localize them in video frames with bounding boxes. We present the results of this challenge along with many of the team's efforts. We conclude by discussing these results in the broader context of machine learning and surgical data science. The training data used for this challenge consisting of 24,695 video clips with tool presence labels is also being released publicly and can be accessed at https://console.cloud.google.com/storage/browser/isi-surgtoolloc-2022.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
CholecTriplet2021: A benchmark challenge for surgical action triplet recognition
Apr 10, 2022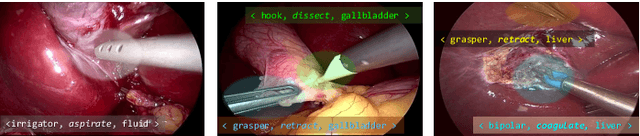

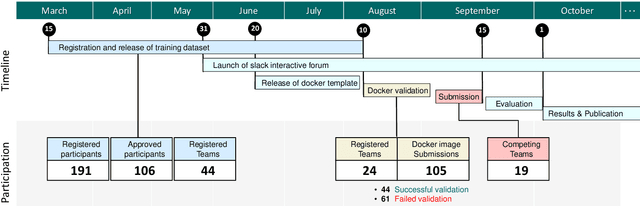
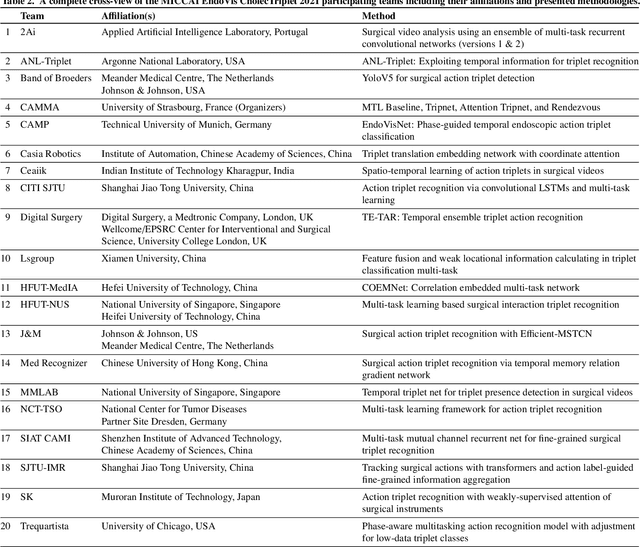
Context-aware decision support in the operating room can foster surgical safety and efficiency by leveraging real-time feedback from surgical workflow analysis. Most existing works recognize surgical activities at a coarse-grained level, such as phases, steps or events, leaving out fine-grained interaction details about the surgical activity; yet those are needed for more helpful AI assistance in the operating room. Recognizing surgical actions as triplets of <instrument, verb, target> combination delivers comprehensive details about the activities taking place in surgical videos. This paper presents CholecTriplet2021: an endoscopic vision challenge organized at MICCAI 2021 for the recognition of surgical action triplets in laparoscopic videos. The challenge granted private access to the large-scale CholecT50 dataset, which is annotated with action triplet information. In this paper, we present the challenge setup and assessment of the state-of-the-art deep learning methods proposed by the participants during the challenge. A total of 4 baseline methods from the challenge organizers and 19 new deep learning algorithms by competing teams are presented to recognize surgical action triplets directly from surgical videos, achieving mean average precision (mAP) ranging from 4.2% to 38.1%. This study also analyzes the significance of the results obtained by the presented approaches, performs a thorough methodological comparison between them, in-depth result analysis, and proposes a novel ensemble method for enhanced recognition. Our analysis shows that surgical workflow analysis is not yet solved, and also highlights interesting directions for future research on fine-grained surgical activity recognition which is of utmost importance for the development of AI in surgery.
Neko: a Library for Exploring Neuromorphic Learning Rules
May 01, 2021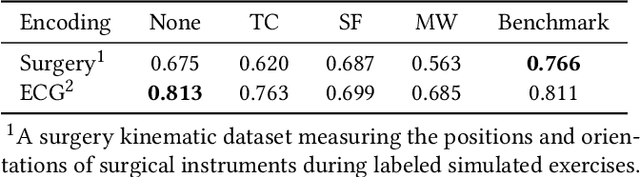
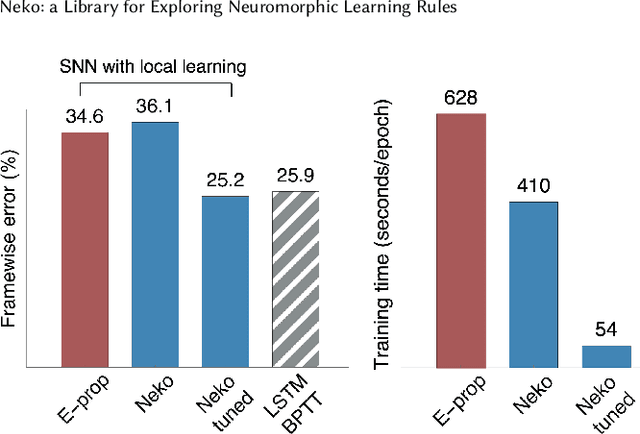
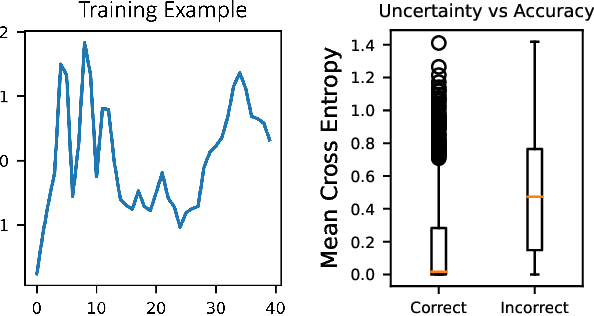
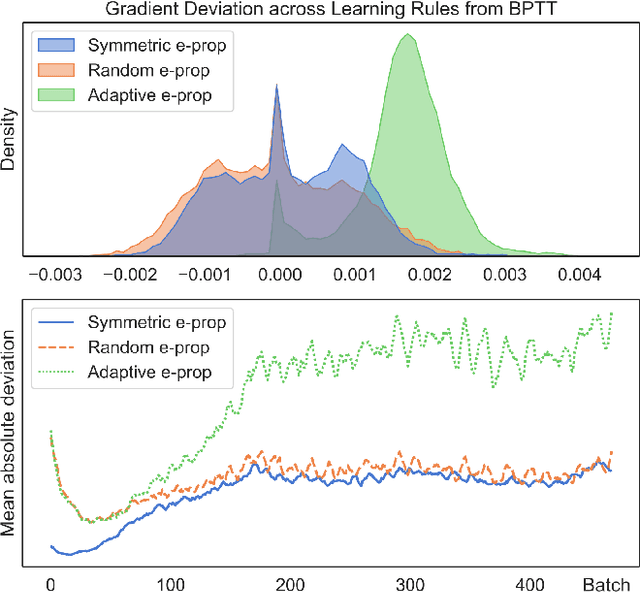
The field of neuromorphic computing is in a period of active exploration. While many tools have been developed to simulate neuronal dynamics or convert deep networks to spiking models, general software libraries for learning rules remain underexplored. This is partly due to the diverse, challenging nature of efforts to design new learning rules, which range from encoding methods to gradient approximations, from population approaches that mimic the Bayesian brain to constrained learning algorithms deployed on memristor crossbars. To address this gap, we present Neko, a modular, extensible library with a focus on aiding the design of new learning algorithms. We demonstrate the utility of Neko in three exemplar cases: online local learning, probabilistic learning, and analog on-device learning. Our results show that Neko can replicate the state-of-the-art algorithms and, in one case, lead to significant outperformance in accuracy and speed. Further, it offers tools including gradient comparison that can help develop new algorithmic variants. Neko is an open source Python library that supports PyTorch and TensorFlow backends.
Recurrent and Spiking Modeling of Sparse Surgical Kinematics
Jun 11, 2020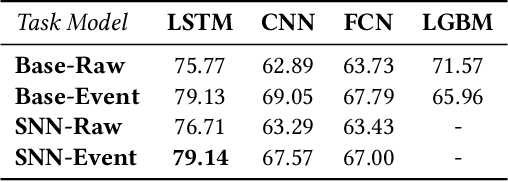
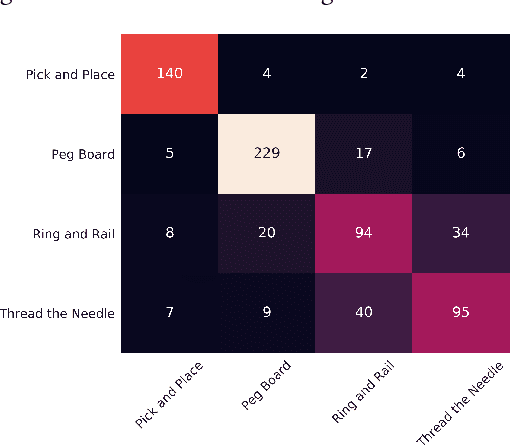
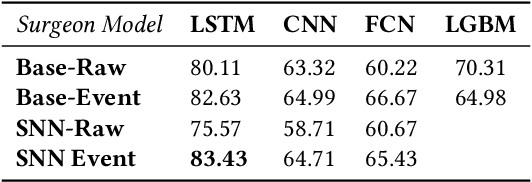
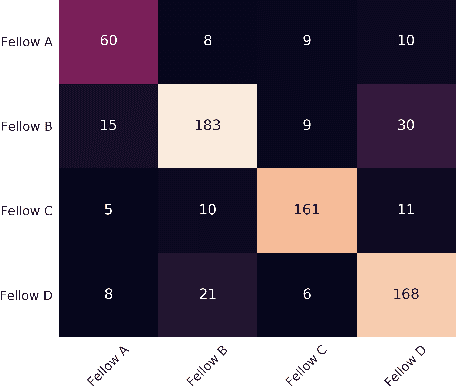
Robot-assisted minimally invasive surgery is improving surgeon performance and patient outcomes. This innovation is also turning what has been a subjective practice into motion sequences that can be precisely measured. A growing number of studies have used machine learning to analyze video and kinematic data captured from surgical robots. In these studies, models are typically trained on benchmark datasets for representative surgical tasks to assess surgeon skill levels. While they have shown that novices and experts can be accurately classified, it is not clear whether machine learning can separate highly proficient surgeons from one another, especially without video data. In this study, we explore the possibility of using only kinematic data to predict surgeons of similar skill levels. We focus on a new dataset created from surgical exercises on a simulation device for skill training. A simple, efficient encoding scheme was devised to encode kinematic sequences so that they were amenable to edge learning. We report that it is possible to identify surgical fellows receiving near perfect scores in the simulation exercises based on their motion characteristics alone. Further, our model could be converted to a spiking neural network to train and infer on the Nengo simulation framework with no loss in accuracy. Overall, this study suggests that building neuromorphic models from sparse motion features may be a potentially useful strategy for identifying surgeons and gestures with chips deployed on robotic systems to offer adaptive assistance during surgery and training with additional latency and privacy benefits.
Deep Medical Image Analysis with Representation Learning and Neuromorphic Computing
May 11, 2020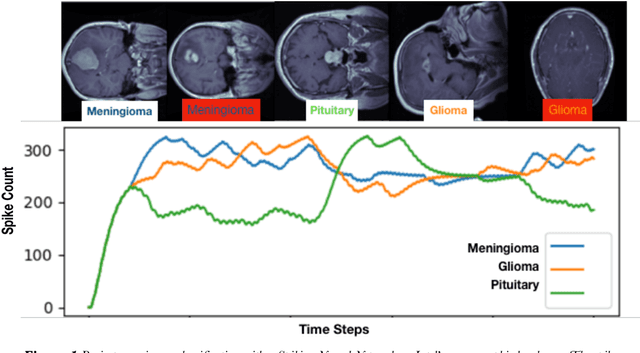
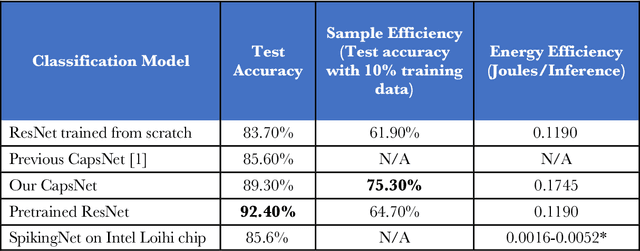

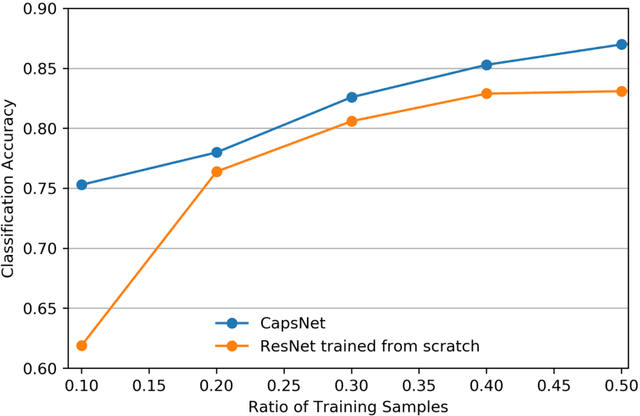
We explore three representative lines of research and demonstrate the utility of our methods on a classification benchmark of brain cancer MRI data. First, we present a capsule network that explicitly learns a representation robust to rotation and affine transformation. This model requires less training data and outperforms both the original convolutional baseline and a previous capsule network implementation. Second, we leverage the latest domain adaptation techniques to achieve a new state-of-the-art accuracy. Our experiments show that non-medical images can be used to improve model performance. Finally, we design a spiking neural network trained on the Intel Loihi neuromorphic chip (Fig. 1 shows an inference snapshot). This model consumes much lower power while achieving reasonable accuracy given model reduction. We posit that more research in this direction combining hardware and learning advancements will power future medical imaging (on-device AI, few-shot prediction, adaptive scanning).