 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Agentic Reasoning for Designing Biologics Targeting Intrinsically Disordered Proteins
Dec 17, 2025Intrinsically disordered proteins (IDPs) represent crucial therapeutic targets due to their significant role in disease -- approximately 80\% of cancer-related proteins contain long disordered regions -- but their lack of stable secondary/tertiary structures makes them "undruggable". While recent computational advances, such as diffusion models, can design high-affinity IDP binders, translating these to practical drug discovery requires autonomous systems capable of reasoning across complex conformational ensembles and orchestrating diverse computational tools at scale.To address this challenge, we designed and implemented StructBioReasoner, a scalable multi-agent system for designing biologics that can be used to target IDPs. StructBioReasoner employs a novel tournament-based reasoning framework where specialized agents compete to generate and refine therapeutic hypotheses, naturally distributing computational load for efficient exploration of the vast design space. Agents integrate domain knowledge with access to literature synthesis, AI-structure prediction, molecular simulations, and stability analysis, coordinating their execution on HPC infrastructure via an extensible federated agentic middleware, Academy. We benchmark StructBioReasoner across Der f 21 and NMNAT-2 and demonstrate that over 50\% of 787 designed and validated candidates for Der f 21 outperformed the human-designed reference binders from literature, in terms of improved binding free energy. For the more challenging NMNAT-2 protein, we identified three binding modes from 97,066 binders, including the well-studied NMNAT2:p53 interface. Thus, StructBioReasoner lays the groundwork for agentic reasoning systems for IDP therapeutic discovery on Exascale platforms.
HiPerRAG: High-Performance Retrieval Augmented Generation for Scientific Insights
May 07, 2025The volume of scientific literature is growing exponentially, leading to underutilized discoveries, duplicated efforts, and limited cross-disciplinary collaboration. Retrieval Augmented Generation (RAG) offers a way to assist scientists by improving the factuality of Large Language Models (LLMs) in processing this influx of information. However, scaling RAG to handle millions of articles introduces significant challenges, including the high computational costs associated with parsing documents and embedding scientific knowledge, as well as the algorithmic complexity of aligning these representations with the nuanced semantics of scientific content. To address these issues, we introduce HiPerRAG, a RAG workflow powered by high performance computing (HPC) to index and retrieve knowledge from more than 3.6 million scientific articles. At its core are Oreo, a high-throughput model for multimodal document parsing, and ColTrast, a query-aware encoder fine-tuning algorithm that enhances retrieval accuracy by using contrastive learning and late-interaction techniques. HiPerRAG delivers robust performance on existing scientific question answering benchmarks and two new benchmarks introduced in this work, achieving 90% accuracy on SciQ and 76% on PubMedQA-outperforming both domain-specific models like PubMedGPT and commercial LLMs such as GPT-4. Scaling to thousands of GPUs on the Polaris, Sunspot, and Frontier supercomputers, HiPerRAG delivers million document-scale RAG workflows for unifying scientific knowledge and fostering interdisciplinary innovation.
DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
Oct 11, 2023



In the upcoming decade, deep learning may revolutionize the natural sciences, enhancing our capacity to model and predict natural occurrences. This could herald a new era of scientific exploration, bringing significant advancements across sectors from drug development to renewable energy. To answer this call, we present DeepSpeed4Science initiative (deepspeed4science.ai) which aims to build unique capabilities through AI system technology innovations to help domain experts to unlock today's biggest science mysteries. By leveraging DeepSpeed's current technology pillars (training, inference and compression) as base technology enablers, DeepSpeed4Science will create a new set of AI system technologies tailored for accelerating scientific discoveries by addressing their unique complexity beyond the common technical approaches used for accelerating generic large language models (LLMs). In this paper, we showcase the early progress we made with DeepSpeed4Science in addressing two of the critical system challenges in structural biology research.
CrossedWires: A Dataset of Syntactically Equivalent but Semantically Disparate Deep Learning Models
Aug 29, 2021

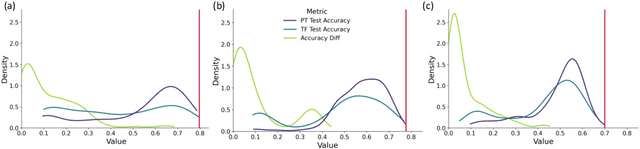

The training of neural networks using different deep learning frameworks may lead to drastically differing accuracy levels despite the use of the same neural network architecture and identical training hyperparameters such as learning rate and choice of optimization algorithms. Currently, our ability to build standardized deep learning models is limited by the availability of a suite of neural network and corresponding training hyperparameter benchmarks that expose differences between existing deep learning frameworks. In this paper, we present a living dataset of models and hyperparameters, called CrossedWires, that exposes semantic differences between two popular deep learning frameworks: PyTorch and Tensorflow. The CrossedWires dataset currently consists of models trained on CIFAR10 images using three different computer vision architectures: VGG16, ResNet50 and DenseNet121 across a large hyperparameter space. Using hyperparameter optimization, each of the three models was trained on 400 sets of hyperparameters suggested by the HyperSpace search algorithm. The CrossedWires dataset includes PyTorch and Tensforflow models with test accuracies as different as 0.681 on syntactically equivalent models and identical hyperparameter choices. The 340 GB dataset and benchmarks presented here include the performance statistics, training curves, and model weights for all 1200 hyperparameter choices, resulting in 2400 total models. The CrossedWires dataset provides an opportunity to study semantic differences between syntactically equivalent models across popular deep learning frameworks. Further, the insights obtained from this study can enable the development of algorithms and tools that improve reliability and reproducibility of deep learning frameworks. The dataset is freely available at https://github.com/maxzvyagin/crossedwires through a Python API and direct download link.
Protein-Ligand Docking Surrogate Models: A SARS-CoV-2 Benchmark for Deep Learning Accelerated Virtual Screening
Jun 30, 2021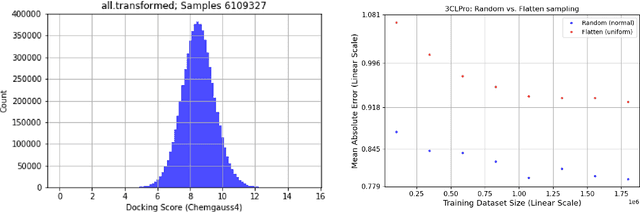

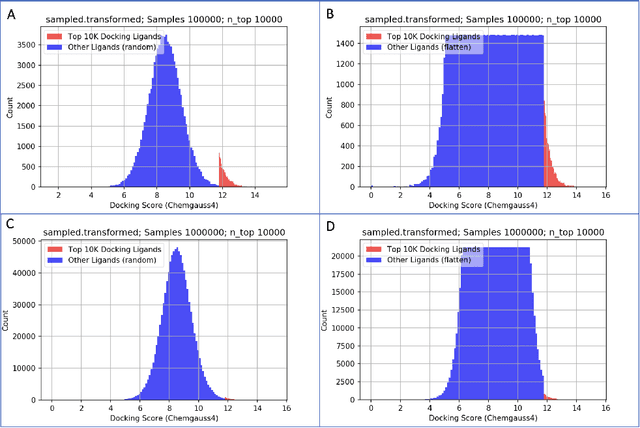
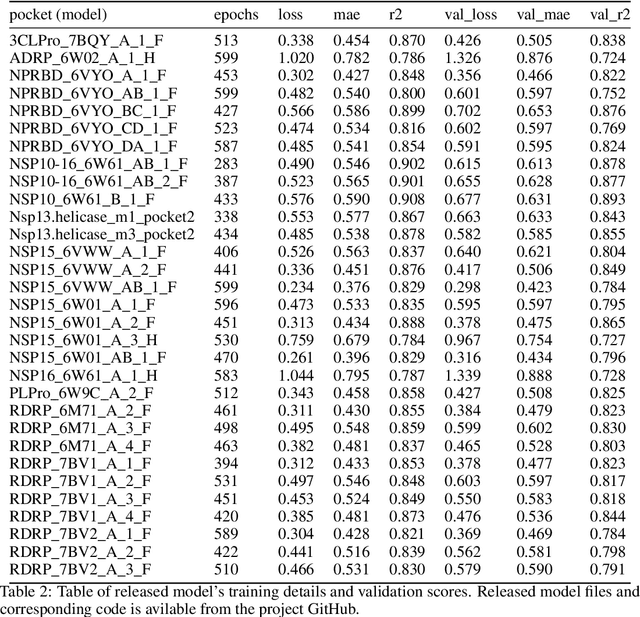
We propose a benchmark to study surrogate model accuracy for protein-ligand docking. We share a dataset consisting of 200 million 3D complex structures and 2D structure scores across a consistent set of 13 million "in-stock" molecules over 15 receptors, or binding sites, across the SARS-CoV-2 proteome. Our work shows surrogate docking models have six orders of magnitude more throughput than standard docking protocols on the same supercomputer node types. We demonstrate the power of high-speed surrogate models by running each target against 1 billion molecules in under a day (50k predictions per GPU seconds). We showcase a workflow for docking utilizing surrogate ML models as a pre-filter. Our workflow is ten times faster at screening a library of compounds than the standard technique, with an error rate less than 0.01\% of detecting the underlying best scoring 0.1\% of compounds. Our analysis of the speedup explains that to screen more molecules under a docking paradigm, another order of magnitude speedup must come from model accuracy rather than computing speed (which, if increased, will not anymore alter our throughput to screen molecules). We believe this is strong evidence for the community to begin focusing on improving the accuracy of surrogate models to improve the ability to screen massive compound libraries 100x or even 1000x faster than current techniques.
Learning Curves for Drug Response Prediction in Cancer Cell Lines
Nov 25, 2020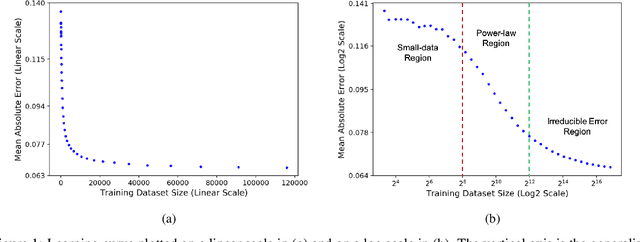
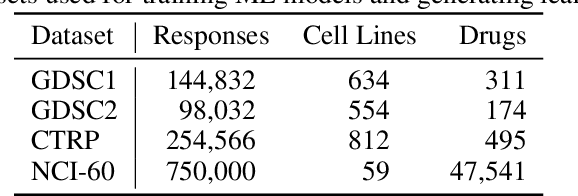
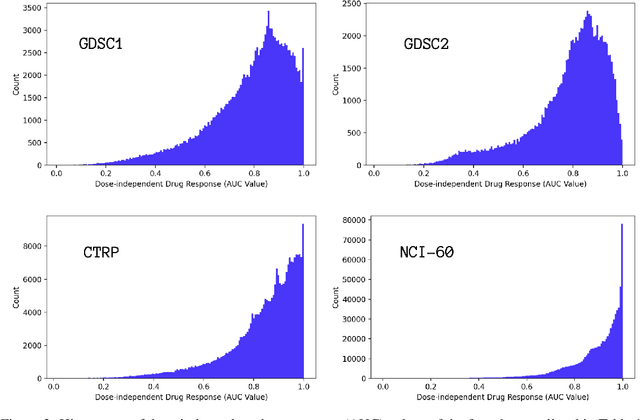
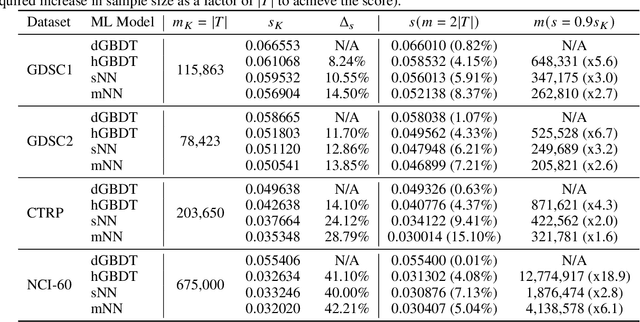
Motivated by the size of cell line drug sensitivity data, researchers have been developing machine learning (ML) models for predicting drug response to advance cancer treatment. As drug sensitivity studies continue generating data, a common question is whether the proposed predictors can further improve the generalization performance with more training data. We utilize empirical learning curves for evaluating and comparing the data scaling properties of two neural networks (NNs) and two gradient boosting decision tree (GBDT) models trained on four drug screening datasets. The learning curves are accurately fitted to a power law model, providing a framework for assessing the data scaling behavior of these predictors. The curves demonstrate that no single model dominates in terms of prediction performance across all datasets and training sizes, suggesting that the shape of these curves depends on the unique model-dataset pair. The multi-input NN (mNN), in which gene expressions and molecular drug descriptors are input into separate subnetworks, outperforms a single-input NN (sNN), where the cell and drug features are concatenated for the input layer. In contrast, a GBDT with hyperparameter tuning exhibits superior performance as compared with both NNs at the lower range of training sizes for two of the datasets, whereas the mNN performs better at the higher range of training sizes. Moreover, the trajectory of the curves suggests that increasing the sample size is expected to further improve prediction scores of both NNs. These observations demonstrate the benefit of using learning curves to evaluate predictors, providing a broader perspective on the overall data scaling characteristics. The fitted power law curves provide a forward-looking performance metric and can serve as a co-design tool to guide experimental biologists and computational scientists in the design of future experiments.
Ensemble Transfer Learning for the Prediction of Anti-Cancer Drug Response
May 13, 2020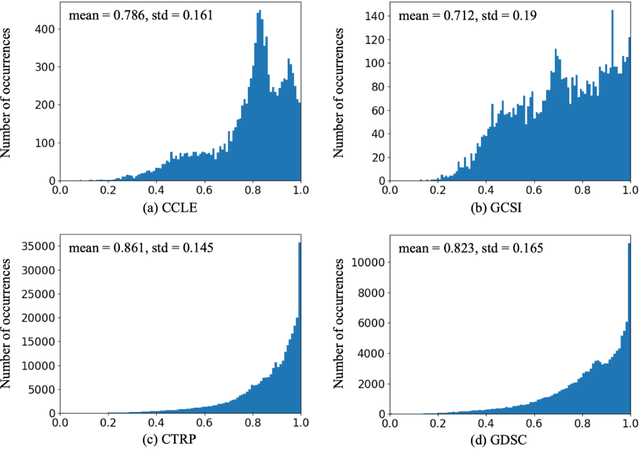
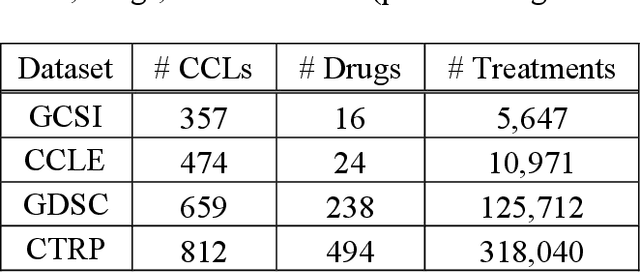
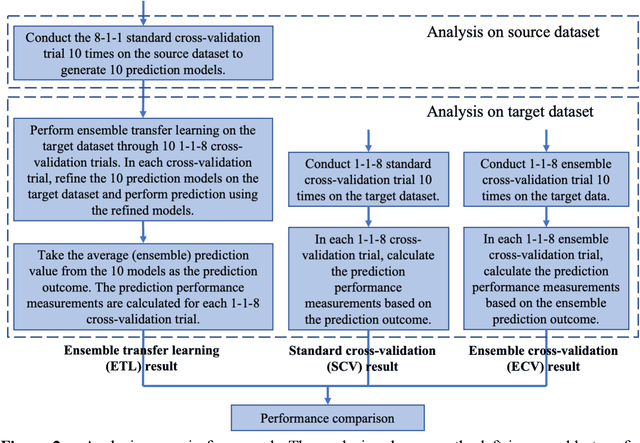
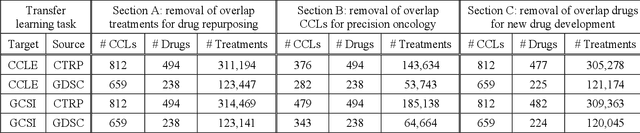
Transfer learning has been shown to be effective in many applications in which training data for the target problem are limited but data for a related (source) problem are abundant. In this paper, we apply transfer learning to the prediction of anti-cancer drug response. Previous transfer learning studies for drug response prediction focused on building models that predict the response of tumor cells to a specific drug treatment. We target the more challenging task of building general prediction models that can make predictions for both new tumor cells and new drugs. We apply the classic transfer learning framework that trains a prediction model on the source dataset and refines it on the target dataset, and extends the framework through ensemble. The ensemble transfer learning pipeline is implemented using LightGBM and two deep neural network (DNN) models with different architectures. Uniquely, we investigate its power for three application settings including drug repurposing, precision oncology, and new drug development, through different data partition schemes in cross-validation. We test the proposed ensemble transfer learning on benchmark in vitro drug screening datasets, taking one dataset as the source domain and another dataset as the target domain. The analysis results demonstrate the benefit of applying ensemble transfer learning for predicting anti-cancer drug response in all three applications with both LightGBM and DNN models. Compared between the different prediction models, a DNN model with two subnetworks for the inputs of tumor features and drug features separately outperforms LightGBM and the other DNN model that concatenates tumor features and drug features for input in the drug repurposing and precision oncology applications. In the more challenging application of new drug development, LightGBM performs better than the other two DNN models.
Deep Medical Image Analysis with Representation Learning and Neuromorphic Computing
May 11, 2020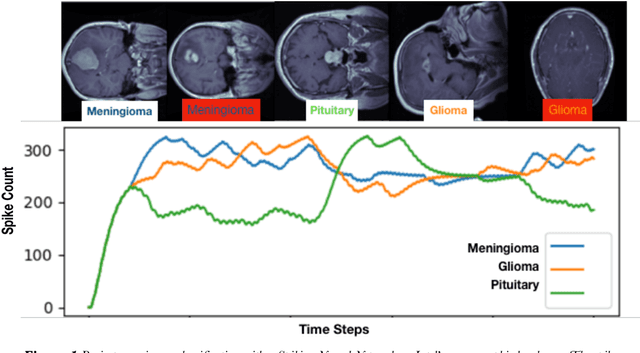
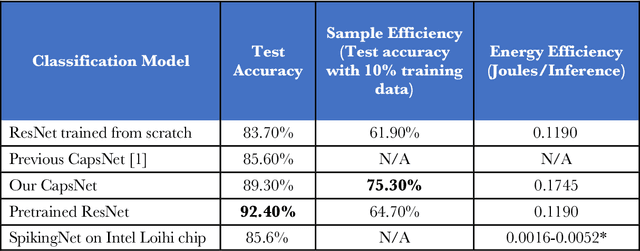

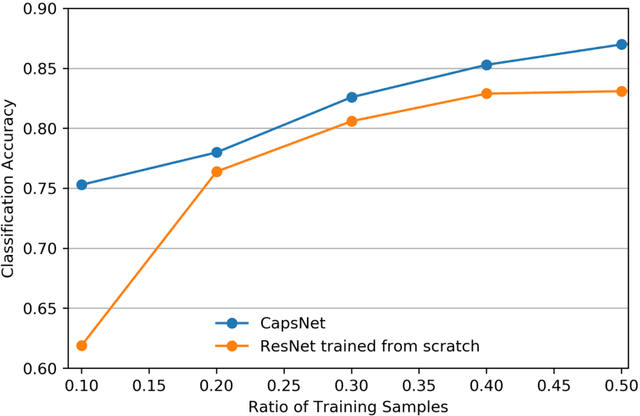
We explore three representative lines of research and demonstrate the utility of our methods on a classification benchmark of brain cancer MRI data. First, we present a capsule network that explicitly learns a representation robust to rotation and affine transformation. This model requires less training data and outperforms both the original convolutional baseline and a previous capsule network implementation. Second, we leverage the latest domain adaptation techniques to achieve a new state-of-the-art accuracy. Our experiments show that non-medical images can be used to improve model performance. Finally, we design a spiking neural network trained on the Intel Loihi neuromorphic chip (Fig. 1 shows an inference snapshot). This model consumes much lower power while achieving reasonable accuracy given model reduction. We posit that more research in this direction combining hardware and learning advancements will power future medical imaging (on-device AI, few-shot prediction, adaptive scanning).