 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Curves for Drug Response Prediction in Cancer Cell Lines
Nov 25, 2020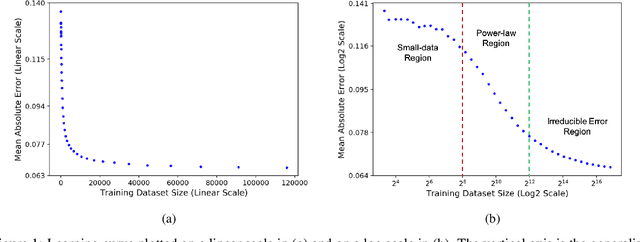
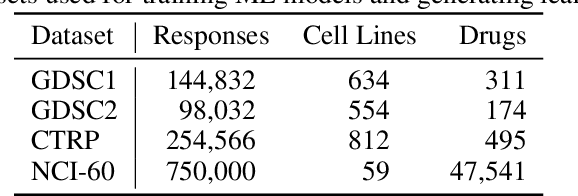
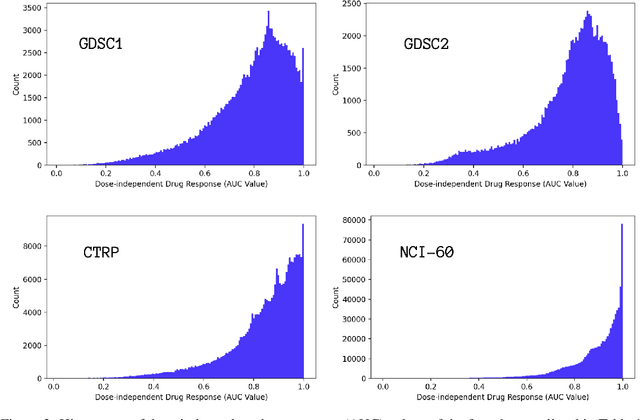
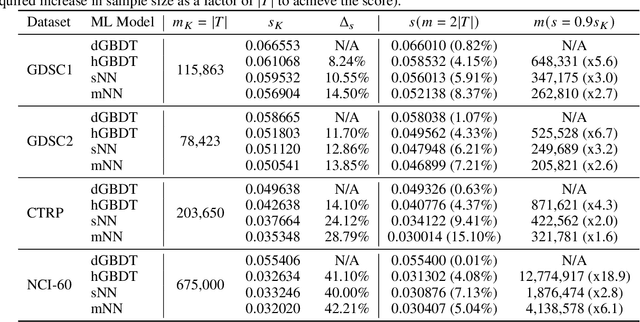
Motivated by the size of cell line drug sensitivity data, researchers have been developing machine learning (ML) models for predicting drug response to advance cancer treatment. As drug sensitivity studies continue generating data, a common question is whether the proposed predictors can further improve the generalization performance with more training data. We utilize empirical learning curves for evaluating and comparing the data scaling properties of two neural networks (NNs) and two gradient boosting decision tree (GBDT) models trained on four drug screening datasets. The learning curves are accurately fitted to a power law model, providing a framework for assessing the data scaling behavior of these predictors. The curves demonstrate that no single model dominates in terms of prediction performance across all datasets and training sizes, suggesting that the shape of these curves depends on the unique model-dataset pair. The multi-input NN (mNN), in which gene expressions and molecular drug descriptors are input into separate subnetworks, outperforms a single-input NN (sNN), where the cell and drug features are concatenated for the input layer. In contrast, a GBDT with hyperparameter tuning exhibits superior performance as compared with both NNs at the lower range of training sizes for two of the datasets, whereas the mNN performs better at the higher range of training sizes. Moreover, the trajectory of the curves suggests that increasing the sample size is expected to further improve prediction scores of both NNs. These observations demonstrate the benefit of using learning curves to evaluate predictors, providing a broader perspective on the overall data scaling characteristics. The fitted power law curves provide a forward-looking performance metric and can serve as a co-design tool to guide experimental biologists and computational scientists in the design of future experiments.