 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperInfer: SLO-Aware Rotary Scheduling and Memory Management for LLM Inference on Superchips
Jan 28, 2026Large Language Model (LLM) serving faces a fundamental tension between stringent latency Service Level Objectives (SLOs) and limited GPU memory capacity. When high request rates exhaust the KV cache budget, existing LLM inference systems often suffer severe head-of-line (HOL) blocking. While prior work explored PCIe-based offloading, these approaches cannot sustain responsiveness under high request rates, often failing to meet tight Time-To-First-Token (TTFT) and Time-Between-Tokens (TBT) SLOs. We present SuperInfer, a high-performance LLM inference system designed for emerging Superchips (e.g., NVIDIA GH200) with tightly coupled GPU-CPU architecture via NVLink-C2C. SuperInfer introduces RotaSched, the first proactive, SLO-aware rotary scheduler that rotates requests to maintain responsiveness on Superchips, and DuplexKV, an optimized rotation engine that enables full-duplex transfer over NVLink-C2C. Evaluations on GH200 using various models and datasets show that SuperInfer improves TTFT SLO attainment rates by up to 74.7% while maintaining comparable TBT and throughput compared to state-of-the-art systems, demonstrating that SLO-aware scheduling and memory co-design unlocks the full potential of Superchips for responsive LLM serving.
Hidden States as Early Signals: Step-level Trace Evaluation and Pruning for Efficient Test-Time Scaling
Jan 14, 2026Large Language Models (LLMs) can enhance reasoning capabilities through test-time scaling by generating multiple traces. However, the combination of lengthy reasoning traces with multiple sampling introduces substantial computation and high end-to-end latency. Prior work on accelerating this process has relied on similarity-based or confidence-based pruning, but these signals do not reliably indicate trace quality. To address these limitations, we propose STEP: Step-level Trace Evaluation and Pruning, a novel pruning framework that evaluates reasoning steps using hidden states and dynamically prunes unpromising traces during generation. We train a lightweight step scorer to estimate trace quality, and design a GPU memory-aware pruning strategy that triggers pruning as the GPU memory is saturated by KV cache to reduce end-to-end latency. Experiments across challenging reasoning benchmarks demonstrate that STEP reduces end-to-end inference latency by 45%-70% on average compared to self-consistency while also improving reasoning accuracy. Our code is released at: https://github.com/Supercomputing-System-AI-Lab/STEP
FaithLens: Detecting and Explaining Faithfulness Hallucination
Dec 23, 2025
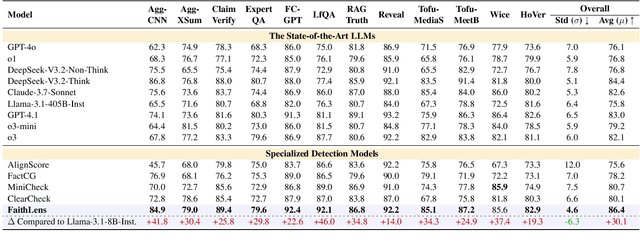
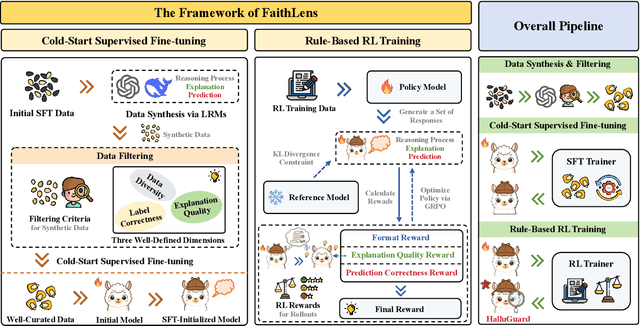
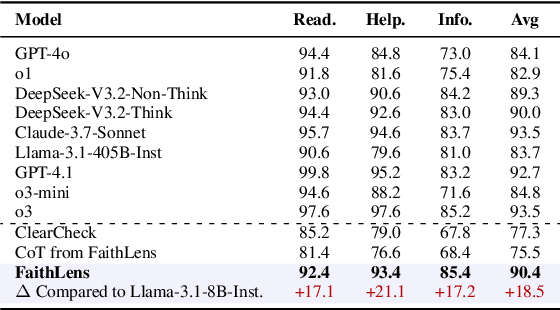
Recognizing whether outputs from large language models (LLMs) contain faithfulness hallucination is crucial for real-world applications, e.g., retrieval-augmented generation and summarization. In this paper, we introduce FaithLens, a cost-efficient and effective faithfulness hallucination detection model that can jointly provide binary predictions and corresponding explanations to improve trustworthiness. To achieve this, we first synthesize training data with explanations via advanced LLMs and apply a well-defined data filtering strategy to ensure label correctness, explanation quality, and data diversity. Subsequently, we fine-tune the model on these well-curated training data as a cold start and further optimize it with rule-based reinforcement learning, using rewards for both prediction correctness and explanation quality. Results on 12 diverse tasks show that the 8B-parameter FaithLens outperforms advanced models such as GPT-4.1 and o3. Also, FaithLens can produce high-quality explanations, delivering a distinctive balance of trustworthiness, efficiency, and effectiveness.
MMGR: Multi-Modal Generative Reasoning
Dec 17, 2025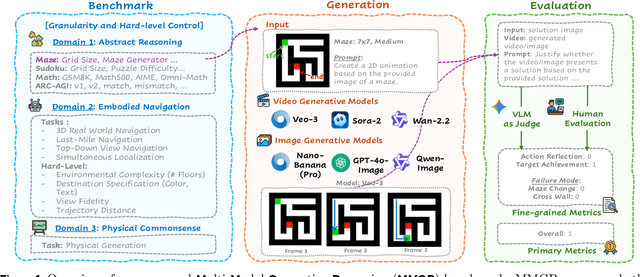
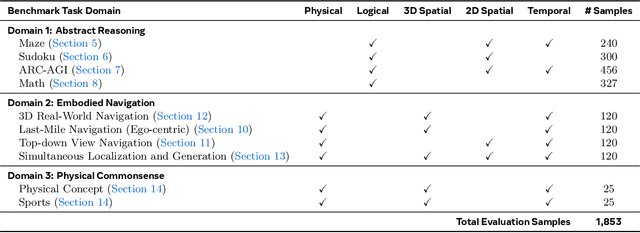

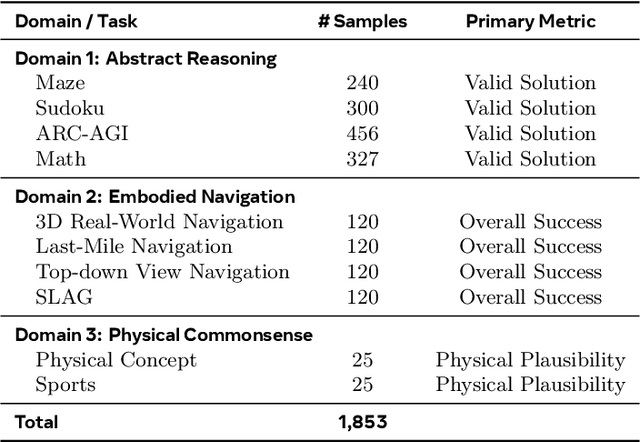
Video foundation models generate visually realistic and temporally coherent content, but their reliability as world simulators depends on whether they capture physical, logical, and spatial constraints. Existing metrics such as Frechet Video Distance (FVD) emphasize perceptual quality and overlook reasoning failures, including violations of causality, physics, and global consistency. We introduce MMGR (Multi-Modal Generative Reasoning Evaluation and Benchmark), a principled evaluation framework based on five reasoning abilities: Physical, Logical, 3D Spatial, 2D Spatial, and Temporal. MMGR evaluates generative reasoning across three domains: Abstract Reasoning (ARC-AGI, Sudoku), Embodied Navigation (real-world 3D navigation and localization), and Physical Commonsense (sports and compositional interactions). MMGR applies fine-grained metrics that require holistic correctness across both video and image generation. We benchmark leading video models (Veo-3, Sora-2, Wan-2.2) and image models (Nano-banana, Nano-banana Pro, GPT-4o-image, Qwen-image), revealing strong performance gaps across domains. Models show moderate success on Physical Commonsense tasks but perform poorly on Abstract Reasoning (below 10 percent accuracy on ARC-AGI) and struggle with long-horizon spatial planning in embodied settings. Our analysis highlights key limitations in current models, including overreliance on perceptual data, weak global state consistency, and objectives that reward visual plausibility over causal correctness. MMGR offers a unified diagnostic benchmark and a path toward reasoning-aware generative world models.
PuzzleMoE: Efficient Compression of Large Mixture-of-Experts Models via Sparse Expert Merging and Bit-packed inference
Nov 06, 2025



Mixture-of-Experts (MoE) models have shown strong potential in scaling language models efficiently by activating only a small subset of experts per input. However, their widespread deployment remains limited due to the high memory overhead associated with storing all expert parameters, particularly as the number of experts increases. To address this challenge, prior works have explored expert dropping and merging strategies, yet they often suffer from performance drop at high compression ratios. In this paper, we introduce PuzzleMoE, a training-free MoE compression method that achieves both high accuracy and efficient inference through two key innovations: First, PuzzleMoE performs sparse expert merging by identifying element-wise weight redundancy and specialization. It uses a dual-mask to capture both shared and expert-specific parameters. Second, to avoid the overhead of storing binary masks and signs, PuzzleMoE introduces a bit-packed encoding scheme that reuses underutilized exponent bits, enabling efficient MoE inference on GPUs. Extensive experiments demonstrate that PuzzleMoE can compress MoE models by up to 50% while maintaining accuracy across various tasks. Specifically, it outperforms prior MoE compression methods by up to 16.7% on MMLU at 50% compression ratio, and achieves up to 1.28\times inference speedup.
FlexGaussian: Flexible and Cost-Effective Training-Free Compression for 3D Gaussian Splatting
Jul 09, 20253D Gaussian splatting has become a prominent technique for representing and rendering complex 3D scenes, due to its high fidelity and speed advantages. However, the growing demand for large-scale models calls for effective compression to reduce memory and computation costs, especially on mobile and edge devices with limited resources. Existing compression methods effectively reduce 3D Gaussian parameters but often require extensive retraining or fine-tuning, lacking flexibility under varying compression constraints. In this paper, we introduce FlexGaussian, a flexible and cost-effective method that combines mixed-precision quantization with attribute-discriminative pruning for training-free 3D Gaussian compression. FlexGaussian eliminates the need for retraining and adapts easily to diverse compression targets. Evaluation results show that FlexGaussian achieves up to 96.4% compression while maintaining high rendering quality (<1 dB drop in PSNR), and is deployable on mobile devices. FlexGaussian delivers high compression ratios within seconds, being 1.7-2.1x faster than state-of-the-art training-free methods and 10-100x faster than training-involved approaches. The code is being prepared and will be released soon at: https://github.com/Supercomputing-System-AI-Lab/FlexGaussian
MedCite: Can Language Models Generate Verifiable Text for Medicine?
Jun 07, 2025Existing LLM-based medical question-answering systems lack citation generation and evaluation capabilities, raising concerns about their adoption in practice. In this work, we introduce \name, the first end-to-end framework that facilitates the design and evaluation of citation generation with LLMs for medical tasks. Meanwhile, we introduce a novel multi-pass retrieval-citation method that generates high-quality citations. Our evaluation highlights the challenges and opportunities of citation generation for medical tasks, while identifying important design choices that have a significant impact on the final citation quality. Our proposed method achieves superior citation precision and recall improvements compared to strong baseline methods, and we show that evaluation results correlate well with annotation results from professional experts.
VTool-R1: VLMs Learn to Think with Images via Reinforcement Learning on Multimodal Tool Use
May 25, 2025Reinforcement Learning Finetuning (RFT) has significantly advanced the reasoning capabilities of large language models (LLMs) by enabling long chains of thought, self-correction, and effective tool use. While recent works attempt to extend RFT to vision-language models (VLMs), these efforts largely produce text-only reasoning conditioned on static image inputs, falling short of true multimodal reasoning in the response. In contrast, test-time methods like Visual Sketchpad incorporate visual steps but lack training mechanisms. We introduce VTool-R1, the first framework that trains VLMs to generate multimodal chains of thought by interleaving text and intermediate visual reasoning steps. VTool-R1 integrates Python-based visual editing tools into the RFT process, enabling VLMs to learn when and how to generate visual reasoning steps that benefit final reasoning. Trained with outcome-based rewards tied to task accuracy, our approach elicits strategic visual tool use for reasoning without relying on process-based supervision. Experiments on structured visual question answering over charts and tables show that VTool-R1 enhances reasoning performance by teaching VLMs to "think with images" and generate multimodal chain of thoughts with tools.
Teaching Large Language Models to Maintain Contextual Faithfulness via Synthetic Tasks and Reinforcement Learning
May 22, 2025Teaching large language models (LLMs) to be faithful in the provided context is crucial for building reliable information-seeking systems. Therefore, we propose a systematic framework, CANOE, to improve the faithfulness of LLMs in both short-form and long-form generation tasks without human annotations. Specifically, we first synthesize short-form question-answering (QA) data with four diverse tasks to construct high-quality and easily verifiable training data without human annotation. Also, we propose Dual-GRPO, a rule-based reinforcement learning method that includes three tailored rule-based rewards derived from synthesized short-form QA data, while simultaneously optimizing both short-form and long-form response generation. Notably, Dual-GRPO eliminates the need to manually label preference data to train reward models and avoids over-optimizing short-form generation when relying only on the synthesized short-form QA data. Experimental results show that CANOE greatly improves the faithfulness of LLMs across 11 different downstream tasks, even outperforming the most advanced LLMs, e.g., GPT-4o and OpenAI o1.
MiLo: Efficient Quantized MoE Inference with Mixture of Low-Rank Compensators
Apr 03, 2025A critical approach for efficiently deploying Mixture-of-Experts (MoE) models with massive parameters is quantization. However, state-of-the-art MoE models suffer from non-negligible accuracy loss with extreme quantization, such as under 4 bits. To address this, we introduce MiLo, a novel method that augments highly quantized MoEs with a mixture of low-rank compensators. These compensators consume only a small amount of additional memory but significantly recover accuracy loss from extreme quantization. MiLo also identifies that MoEmodels exhibit distinctive characteristics across weights due to their hybrid dense-sparse architectures, and employs adaptive rank selection policies along with iterative optimizations to close the accuracy gap. MiLo does not rely on calibration data, allowing it to generalize to different MoE models and datasets without overfitting to a calibration set. To avoid the hardware inefficiencies of extreme quantization, such as 3-bit, MiLo develops Tensor Core-friendly 3-bit kernels, enabling measured latency speedups on 3-bit quantized MoE models. Our evaluation shows that MiLo outperforms existing methods on SoTA MoE models across various tasks.