 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathlibLemma: Folklore Lemma Generation and Benchmark for Formal Mathematics
Jan 30, 2026While the ecosystem of Lean and Mathlib has enjoyed celebrated success in formal mathematical reasoning with the help of large language models (LLMs), the absence of many folklore lemmas in Mathlib remains a persistent barrier that limits Lean's usability as an everyday tool for mathematicians like LaTeX or Maple. To address this, we introduce MathlibLemma, the first LLM-based multi-agent system to automate the discovery and formalization of mathematical folklore lemmas. This framework constitutes our primary contribution, proactively mining the missing connective tissue of mathematics. Its efficacy is demonstrated by the production of a verified library of folklore lemmas, a subset of which has already been formally merged into the latest build of Mathlib, thereby validating the system's real-world utility and alignment with expert standards. Leveraging this pipeline, we further construct the MathlibLemma benchmark, a suite of 4,028 type-checked Lean statements spanning a broad range of mathematical domains. By transforming the role of LLMs from passive consumers to active contributors, this work establishes a constructive methodology for the self-evolution of formal mathematical libraries.
CASL: Concept-Aligned Sparse Latents for Interpreting Diffusion Models
Jan 21, 2026Internal activations of diffusion models encode rich semantic information, but interpreting such representations remains challenging. While Sparse Autoencoders (SAEs) have shown promise in disentangling latent representations, existing SAE-based methods for diffusion model understanding rely on unsupervised approaches that fail to align sparse features with human-understandable concepts. This limits their ability to provide reliable semantic control over generated images. We introduce CASL (Concept-Aligned Sparse Latents), a supervised framework that aligns sparse latent dimensions of diffusion models with semantic concepts. CASL first trains an SAE on frozen U-Net activations to obtain disentangled latent representations, and then learns a lightweight linear mapping that associates each concept with a small set of relevant latent dimensions. To validate the semantic meaning of these aligned directions, we propose CASL-Steer, a controlled latent intervention that shifts activations along the learned concept axis. Unlike editing methods, CASL-Steer is used solely as a causal probe to reveal how concept-aligned latents influence generated content. We further introduce the Editing Precision Ratio (EPR), a metric that jointly measures concept specificity and the preservation of unrelated attributes. Experiments show that our method achieves superior editing precision and interpretability compared to existing approaches. To the best of our knowledge, this is the first work to achieve supervised alignment between latent representations and semantic concepts in diffusion models.
Reasoning Beyond Chain-of-Thought: A Latent Computational Mode in Large Language Models
Jan 12, 2026Chain-of-Thought (CoT) prompting has improved the reasoning performance of large language models (LLMs), but it remains unclear why it works and whether it is the unique mechanism for triggering reasoning in large language models. In this work, we study this question by directly analyzing and intervening on the internal representations of LLMs with Sparse Autoencoders (SAEs), identifying a small set of latent features that are causally associated with LLM reasoning behavior. Across multiple model families and reasoning benchmarks, we find that steering a single reasoning-related latent feature can substantially improve accuracy without explicit CoT prompting. For large models, latent steering achieves performance comparable to standard CoT prompting while producing more efficient outputs. We further observe that this reasoning-oriented internal state is triggered early in generation and can override prompt-level instructions that discourage explicit reasoning. Overall, our results suggest that multi-step reasoning in LLMs is supported by latent internal activations that can be externally activated, while CoT prompting is one effective, but not unique, way of activating this mechanism rather than its necessary cause.
Toward Faithful Retrieval-Augmented Generation with Sparse Autoencoders
Dec 09, 2025



Retrieval-Augmented Generation (RAG) improves the factuality of large language models (LLMs) by grounding outputs in retrieved evidence, but faithfulness failures, where generations contradict or extend beyond the provided sources, remain a critical challenge. Existing hallucination detection methods for RAG often rely either on large-scale detector training, which requires substantial annotated data, or on querying external LLM judges, which leads to high inference costs. Although some approaches attempt to leverage internal representations of LLMs for hallucination detection, their accuracy remains limited. Motivated by recent advances in mechanistic interpretability, we employ sparse autoencoders (SAEs) to disentangle internal activations, successfully identifying features that are specifically triggered during RAG hallucinations. Building on a systematic pipeline of information-based feature selection and additive feature modeling, we introduce RAGLens, a lightweight hallucination detector that accurately flags unfaithful RAG outputs using LLM internal representations. RAGLens not only achieves superior detection performance compared to existing methods, but also provides interpretable rationales for its decisions, enabling effective post-hoc mitigation of unfaithful RAG. Finally, we justify our design choices and reveal new insights into the distribution of hallucination-related signals within LLMs. The code is available at https://github.com/Teddy-XiongGZ/RAGLens.
SAGE: Spuriousness-Aware Guided Prompt Exploration for Mitigating Multimodal Bias
Nov 17, 2025Large vision-language models, such as CLIP, have shown strong zero-shot classification performance by aligning images and text in a shared embedding space. However, CLIP models often develop multimodal spurious biases, which is the undesirable tendency to rely on spurious features. For example, CLIP may infer object types in images based on frequently co-occurring backgrounds rather than the object's core features. This bias significantly impairs the robustness of pre-trained CLIP models on out-of-distribution data, where such cross-modal associations no longer hold. Existing methods for mitigating multimodal spurious bias typically require fine-tuning on downstream data or prior knowledge of the bias, which undermines the out-of-the-box usability of CLIP. In this paper, we first theoretically analyze the impact of multimodal spurious bias in zero-shot classification. Based on this insight, we propose Spuriousness-Aware Guided Exploration (SAGE), a simple and effective method that mitigates spurious bias through guided prompt selection. SAGE requires no training, fine-tuning, or external annotations. It explores a space of prompt templates and selects the prompts that induce the largest semantic separation between classes, thereby improving worst-group robustness. Extensive experiments on four real-world benchmark datasets and five popular backbone models demonstrate that SAGE consistently improves zero-shot performance and generalization, outperforming previous zero-shot approaches without any external knowledge or model updates.
Concept-RuleNet: Grounded Multi-Agent Neurosymbolic Reasoning in Vision Language Models
Nov 13, 2025Modern vision-language models (VLMs) deliver impressive predictive accuracy yet offer little insight into 'why' a decision is reached, frequently hallucinating facts, particularly when encountering out-of-distribution data. Neurosymbolic frameworks address this by pairing black-box perception with interpretable symbolic reasoning, but current methods extract their symbols solely from task labels, leaving them weakly grounded in the underlying visual data. In this paper, we introduce a multi-agent system - Concept-RuleNet that reinstates visual grounding while retaining transparent reasoning. Specifically, a multimodal concept generator first mines discriminative visual concepts directly from a representative subset of training images. Next, these visual concepts are utilized to condition symbol discovery, anchoring the generations in real image statistics and mitigating label bias. Subsequently, symbols are composed into executable first-order rules by a large language model reasoner agent - yielding interpretable neurosymbolic rules. Finally, during inference, a vision verifier agent quantifies the degree of presence of each symbol and triggers rule execution in tandem with outputs of black-box neural models, predictions with explicit reasoning pathways. Experiments on five benchmarks, including two challenging medical-imaging tasks and three underrepresented natural-image datasets, show that our system augments state-of-the-art neurosymbolic baselines by an average of 5% while also reducing the occurrence of hallucinated symbols in rules by up to 50%.
SlideBot: A Multi-Agent Framework for Generating Informative, Reliable, Multi-Modal Presentations
Nov 12, 2025Large Language Models (LLMs) have shown immense potential in education, automating tasks like quiz generation and content summarization. However, generating effective presentation slides introduces unique challenges due to the complexity of multimodal content creation and the need for precise, domain-specific information. Existing LLM-based solutions often fail to produce reliable and informative outputs, limiting their educational value. To address these limitations, we introduce SlideBot - a modular, multi-agent slide generation framework that integrates LLMs with retrieval, structured planning, and code generation. SlideBot is organized around three pillars: informativeness, ensuring deep and contextually grounded content; reliability, achieved by incorporating external sources through retrieval; and practicality, which enables customization and iterative feedback through instructor collaboration. It incorporates evidence-based instructional design principles from Cognitive Load Theory (CLT) and the Cognitive Theory of Multimedia Learning (CTML), using structured planning to manage intrinsic load and consistent visual macros to reduce extraneous load and enhance dual-channel learning. Within the system, specialized agents collaboratively retrieve information, summarize content, generate figures, and format slides using LaTeX, aligning outputs with instructor preferences through interactive refinement. Evaluations from domain experts and students in AI and biomedical education show that SlideBot consistently enhances conceptual accuracy, clarity, and instructional value. These findings demonstrate SlideBot's potential to streamline slide preparation while ensuring accuracy, relevance, and adaptability in higher education.
Rectifying Shortcut Behaviors in Preference-based Reward Learning
Oct 21, 2025In reinforcement learning from human feedback, preference-based reward models play a central role in aligning large language models to human-aligned behavior. However, recent studies show that these models are prone to reward hacking and often fail to generalize well due to over-optimization. They achieve high reward scores by exploiting shortcuts, that is, exploiting spurious features (e.g., response verbosity, agreeable tone, or sycophancy) that correlate with human preference labels in the training data rather than genuinely reflecting the intended objectives. In this paper, instead of probing these issues one at a time, we take a broader view of the reward hacking problem as shortcut behaviors and introduce a principled yet flexible approach to mitigate shortcut behaviors in preference-based reward learning. Inspired by the invariant theory in the kernel perspective, we propose Preference-based Reward Invariance for Shortcut Mitigation (PRISM), which learns group-invariant kernels with feature maps in a closed-form learning objective. Experimental results in several benchmarks show that our method consistently improves the accuracy of the reward model on diverse out-of-distribution tasks and reduces the dependency on shortcuts in downstream policy models, establishing a robust framework for preference-based alignment.
GCAV: A Global Concept Activation Vector Framework for Cross-Layer Consistency in Interpretability
Aug 28, 2025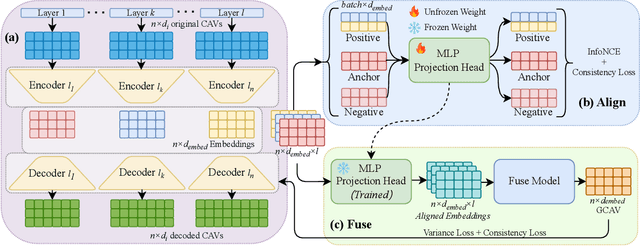
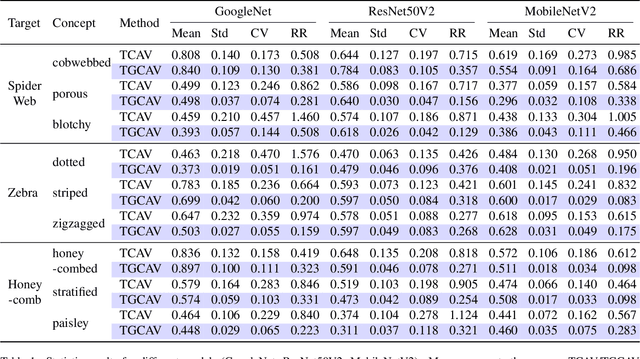
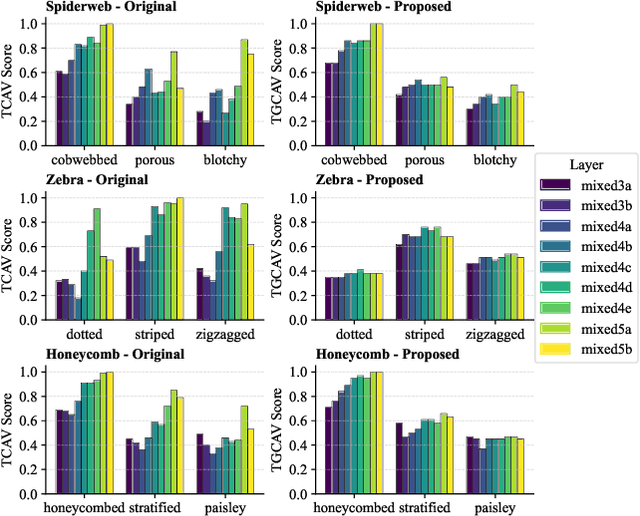

Concept Activation Vectors (CAVs) provide a powerful approach for interpreting deep neural networks by quantifying their sensitivity to human-defined concepts. However, when computed independently at different layers, CAVs often exhibit inconsistencies, making cross-layer comparisons unreliable. To address this issue, we propose the Global Concept Activation Vector (GCAV), a novel framework that unifies CAVs into a single, semantically consistent representation. Our method leverages contrastive learning to align concept representations across layers and employs an attention-based fusion mechanism to construct a globally integrated CAV. By doing so, our method significantly reduces the variance in TCAV scores while preserving concept relevance, ensuring more stable and reliable concept attributions. To evaluate the effectiveness of GCAV, we introduce Testing with Global Concept Activation Vectors (TGCAV) as a method to apply TCAV to GCAV-based representations. We conduct extensive experiments on multiple deep neural networks, demonstrating that our method effectively mitigates concept inconsistency across layers, enhances concept localization, and improves robustness against adversarial perturbations. By integrating cross-layer information into a coherent framework, our method offers a more comprehensive and interpretable understanding of how deep learning models encode human-defined concepts. Code and models are available at https://github.com/Zhenghao-He/GCAV.
MedCite: Can Language Models Generate Verifiable Text for Medicine?
Jun 07, 2025Existing LLM-based medical question-answering systems lack citation generation and evaluation capabilities, raising concerns about their adoption in practice. In this work, we introduce \name, the first end-to-end framework that facilitates the design and evaluation of citation generation with LLMs for medical tasks. Meanwhile, we introduce a novel multi-pass retrieval-citation method that generates high-quality citations. Our evaluation highlights the challenges and opportunities of citation generation for medical tasks, while identifying important design choices that have a significant impact on the final citation quality. Our proposed method achieves superior citation precision and recall improvements compared to strong baseline methods, and we show that evaluation results correlate well with annotation results from professional experts.