 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdeaBench: Benchmarking Large Language Models for Research Idea Generation
Oct 31, 2024



Large Language Models (LLMs) have transformed how people interact with artificial intelligence (AI) systems, achieving state-of-the-art results in various tasks, including scientific discovery and hypothesis generation. However, the lack of a comprehensive and systematic evaluation framework for generating research ideas using LLMs poses a significant obstacle to understanding and assessing their generative capabilities in scientific discovery. To address this gap, we propose IdeaBench, a benchmark system that includes a comprehensive dataset and an evaluation framework for standardizing the assessment of research idea generation using LLMs. Our dataset comprises titles and abstracts from a diverse range of influential papers, along with their referenced works. To emulate the human process of generating research ideas, we profile LLMs as domain-specific researchers and ground them in the same context considered by human researchers. This maximizes the utilization of the LLMs' parametric knowledge to dynamically generate new research ideas. We also introduce an evaluation framework for assessing the quality of generated research ideas. Our evaluation framework is a two-stage process: first, using GPT-4o to rank ideas based on user-specified quality indicators such as novelty and feasibility, enabling scalable personalization; and second, calculating relative ranking based "Insight Score" to quantify the chosen quality indicator. The proposed benchmark system will be a valuable asset for the community to measure and compare different LLMs, ultimately advancing the automation of the scientific discovery process.
'Tis but Thy Name: Semantic Question Answering Evaluation with 11M Names for 1M Entities
Feb 28, 2022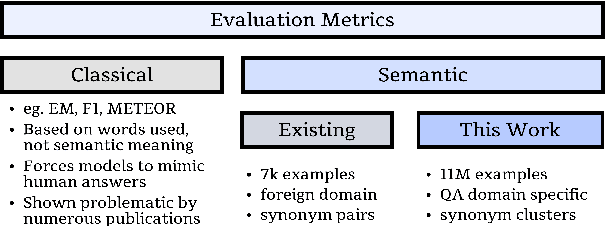
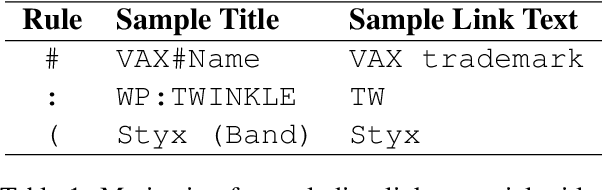
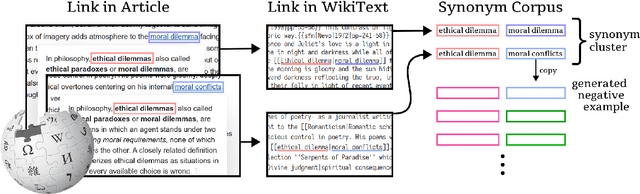

Classic lexical-matching-based QA metrics are slowly being phased out because they punish succinct or informative outputs just because those answers were not provided as ground truth. Recently proposed neural metrics can evaluate semantic similarity but were trained on small textual similarity datasets grafted from foreign domains. We introduce the Wiki Entity Similarity (WES) dataset, an 11M example, domain targeted, semantic entity similarity dataset that is generated from link texts in Wikipedia. WES is tailored to QA evaluation: the examples are entities and phrases and grouped into semantic clusters to simulate multiple ground-truth labels. Human annotators consistently agree with WES labels, and a basic cross encoder metric is better than four classic metrics at predicting human judgments of correctness.
Generalized Grounding Graphs: A Probabilistic Framework for Understanding Grounded Commands
Nov 29, 2017
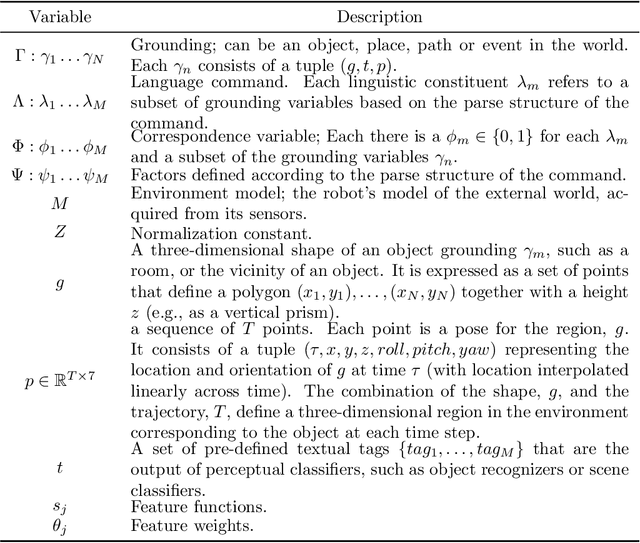
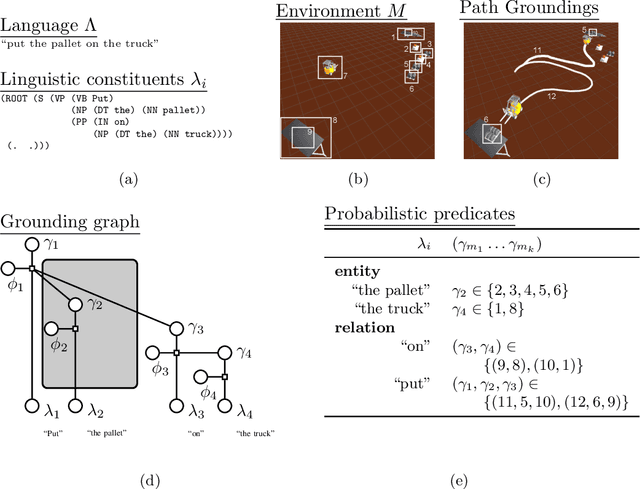
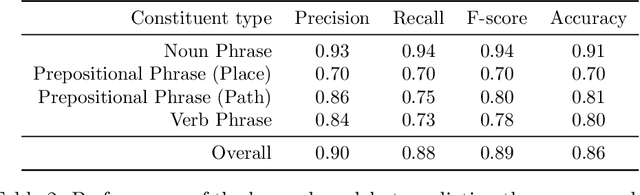
Many task domains require robots to interpret and act upon natural language commands which are given by people and which refer to the robot's physical surroundings. Such interpretation is known variously as the symbol grounding problem, grounded semantics and grounded language acquisition. This problem is challenging because people employ diverse vocabulary and grammar, and because robots have substantial uncertainty about the nature and contents of their surroundings, making it difficult to associate the constitutive language elements (principally noun phrases and spatial relations) of the command text to elements of those surroundings. Symbolic models capture linguistic structure but have not scaled successfully to handle the diverse language produced by untrained users. Existing statistical approaches can better handle diversity, but have not to date modeled complex linguistic structure, limiting achievable accuracy. Recent hybrid approaches have addressed limitations in scaling and complexity, but have not effectively associated linguistic and perceptual features. Our framework, called Generalized Grounding Graphs (G^3), addresses these issues by defining a probabilistic graphical model dynamically according to the linguistic parse structure of a natural language command. This approach scales effectively, handles linguistic diversity, and enables the system to associate parts of a command with the specific objects, places, and events in the external world to which they refer. We show that robots can learn word meanings and use those learned meanings to robustly follow natural language commands produced by untrained users. We demonstrate our approach for both mobility commands and mobile manipulation commands involving a variety of semi-autonomous robotic platforms, including a wheelchair, a micro-air vehicle, a forklift, and the Willow Garage PR2.