 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Grounding Graphs: A Probabilistic Framework for Understanding Grounded Commands
Paper and Code
Nov 29, 2017
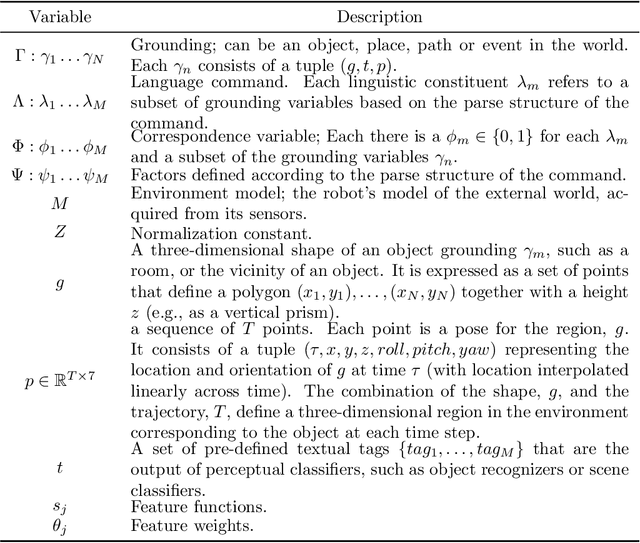
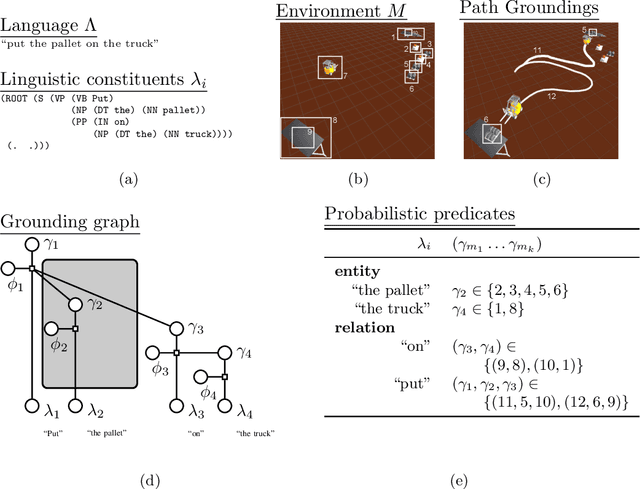
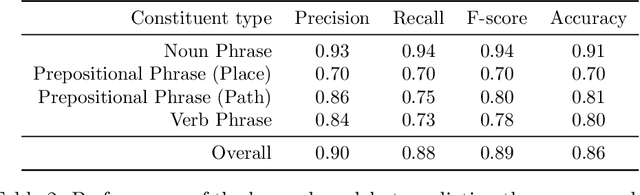
Many task domains require robots to interpret and act upon natural language commands which are given by people and which refer to the robot's physical surroundings. Such interpretation is known variously as the symbol grounding problem, grounded semantics and grounded language acquisition. This problem is challenging because people employ diverse vocabulary and grammar, and because robots have substantial uncertainty about the nature and contents of their surroundings, making it difficult to associate the constitutive language elements (principally noun phrases and spatial relations) of the command text to elements of those surroundings. Symbolic models capture linguistic structure but have not scaled successfully to handle the diverse language produced by untrained users. Existing statistical approaches can better handle diversity, but have not to date modeled complex linguistic structure, limiting achievable accuracy. Recent hybrid approaches have addressed limitations in scaling and complexity, but have not effectively associated linguistic and perceptual features. Our framework, called Generalized Grounding Graphs (G^3), addresses these issues by defining a probabilistic graphical model dynamically according to the linguistic parse structure of a natural language command. This approach scales effectively, handles linguistic diversity, and enables the system to associate parts of a command with the specific objects, places, and events in the external world to which they refer. We show that robots can learn word meanings and use those learned meanings to robustly follow natural language commands produced by untrained users. We demonstrate our approach for both mobility commands and mobile manipulation commands involving a variety of semi-autonomous robotic platforms, including a wheelchair, a micro-air vehicle, a forklift, and the Willow Garage PR2.