 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Are We Actually Benchmarking in Robot Manipulation?
Jun 02, 2026A robotics benchmark score measures success under one fixed evaluation setup, yet is routinely treated as evidence of general manipulation capability. We identify four failure modes, each of which weakens or invalidates a benchmark's role as a valid proxy for that capability: shortcut solvability, lack of statistical significance, creeping overfitting, and data-source dependence. We propose one diagnostic per failure mode. We audit LIBERO, CALVIN, SimplerEnv, RoboCasa, and RoboTwin 2.0 under these diagnostics. LIBERO and CALVIN fail multiple diagnostics. RoboCasa and RoboTwin 2.0 fail fewer, despite appearing far less often in recent progress claims. On LIBERO, a 0.09B probe with no language encoder scores at or near reported SOTA, and most reported gains are not provably statistically significant. On CALVIN, randomizing block poses within the training range drops performance for every tested policy. We release the four diagnostics with reference implementations for authors and reviewers to apply before treating a benchmark score as evidence of progress. Code and artifacts are available at https://ripl.github.io/manipulation_benchmark_audit/.
PAC Learning with Improvements
Mar 05, 2025One of the most basic lower bounds in machine learning is that in nearly any nontrivial setting, it takes $\textit{at least}$ $1/\epsilon$ samples to learn to error $\epsilon$ (and more, if the classifier being learned is complex). However, suppose that data points are agents who have the ability to improve by a small amount if doing so will allow them to receive a (desired) positive classification. In that case, we may actually be able to achieve $\textit{zero}$ error by just being "close enough". For example, imagine a hiring test used to measure an agent's skill at some job such that for some threshold $\theta$, agents who score above $\theta$ will be successful and those who score below $\theta$ will not (i.e., learning a threshold on the line). Suppose also that by putting in effort, agents can improve their skill level by some small amount $r$. In that case, if we learn an approximation $\hat{\theta}$ of $\theta$ such that $\theta \leq \hat{\theta} \leq \theta + r$ and use it for hiring, we can actually achieve error zero, in the sense that (a) any agent classified as positive is truly qualified, and (b) any agent who truly is qualified can be classified as positive by putting in effort. Thus, the ability for agents to improve has the potential to allow for a goal one could not hope to achieve in standard models, namely zero error. In this paper, we explore this phenomenon more broadly, giving general results and examining under what conditions the ability of agents to improve can allow for a reduction in the sample complexity of learning, or alternatively, can make learning harder. We also examine both theoretically and empirically what kinds of improvement-aware algorithms can take into account agents who have the ability to improve to a limited extent when it is in their interest to do so.
Cold Diffusion on the Replay Buffer: Learning to Plan from Known Good States
Oct 21, 2023



Learning from demonstrations (LfD) has successfully trained robots to exhibit remarkable generalization capabilities. However, many powerful imitation techniques do not prioritize the feasibility of the robot behaviors they generate. In this work, we explore the feasibility of plans produced by LfD. As in prior work, we employ a temporal diffusion model with fixed start and goal states to facilitate imitation through in-painting. Unlike previous studies, we apply cold diffusion to ensure the optimization process is directed through the agent's replay buffer of previously visited states. This routing approach increases the likelihood that the final trajectories will predominantly occupy the feasible region of the robot's state space. We test this method in simulated robotic environments with obstacles and observe a significant improvement in the agent's ability to avoid these obstacles during planning.
Subwords as Skills: Tokenization for Sparse-Reward Reinforcement Learning
Sep 08, 2023Exploration in sparse-reward reinforcement learning is difficult due to the requirement of long, coordinated sequences of actions in order to achieve any reward. Moreover, in continuous action spaces there are an infinite number of possible actions, which only increases the difficulty of exploration. One class of methods designed to address these issues forms temporally extended actions, often called skills, from interaction data collected in the same domain, and optimizes a policy on top of this new action space. Typically such methods require a lengthy pretraining phase, especially in continuous action spaces, in order to form the skills before reinforcement learning can begin. Given prior evidence that the full range of the continuous action space is not required in such tasks, we propose a novel approach to skill-generation with two components. First we discretize the action space through clustering, and second we leverage a tokenization technique borrowed from natural language processing to generate temporally extended actions. Such a method outperforms baselines for skill-generation in several challenging sparse-reward domains, and requires orders-of-magnitude less computation in skill-generation and online rollouts.
To the Noise and Back: Diffusion for Shared Autonomy
Feb 24, 2023



Shared autonomy is an operational concept in which a user and an autonomous agent collaboratively control a robotic system. It provides a number of advantages over the extremes of full-teleoperation and full-autonomy in many settings. Traditional approaches to shared autonomy rely on knowledge of the environment dynamics, a discrete space of user goals that is known a priori, or knowledge of the user's policy -- assumptions that are unrealistic in many domains. Recent works relax some of these assumptions by formulating shared autonomy with model-free deep reinforcement learning (RL). In particular, they no longer need knowledge of the goal space (e.g., that the goals are discrete or constrained) or environment dynamics. However, they need knowledge of a task-specific reward function to train the policy. Unfortunately, such reward specification can be a difficult and brittle process. On top of that, the formulations inherently rely on human-in-the-loop training, and that necessitates them to prepare a policy that mimics users' behavior. In this paper, we present a new approach to shared autonomy that employs a modulation of the forward and reverse diffusion process of diffusion models. Our approach does not assume known environment dynamics or the space of user goals, and in contrast to previous work, it does not require any reward feedback, nor does it require access to the user's policy during training. Instead, our framework learns a distribution over a space of desired behaviors. It then employs a diffusion model to translate the user's actions to a sample from this distribution. Crucially, we show that it is possible to carry out this process in a manner that preserves the user's control authority. We evaluate our framework on a series of challenging continuous control tasks, and analyze its ability to effectively correct user actions while maintaining their autonomy.
Depth Field Networks for Generalizable Multi-view Scene Representation
Jul 28, 2022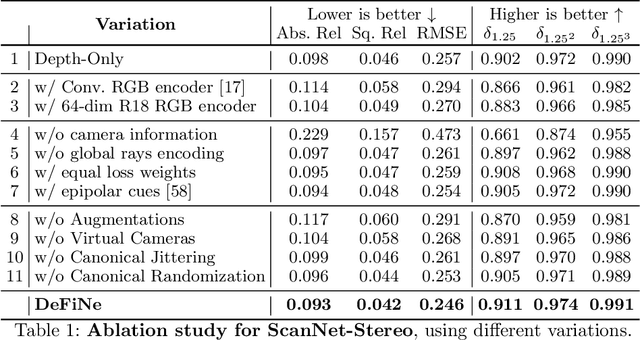
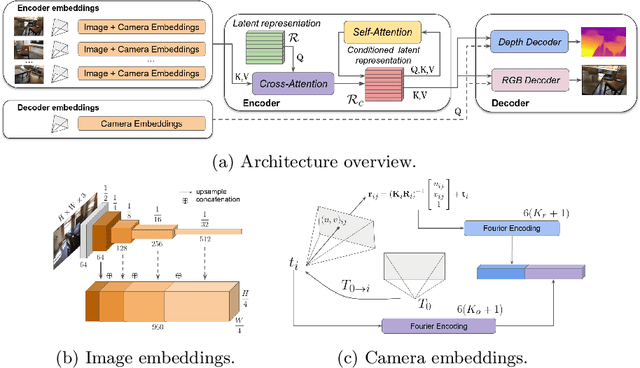
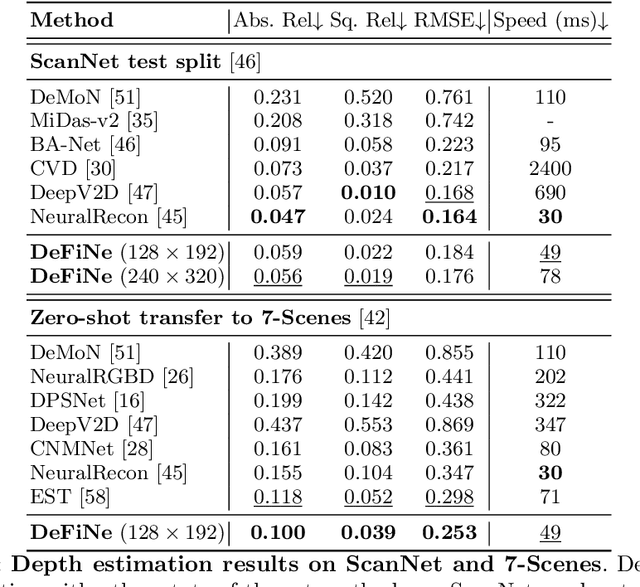
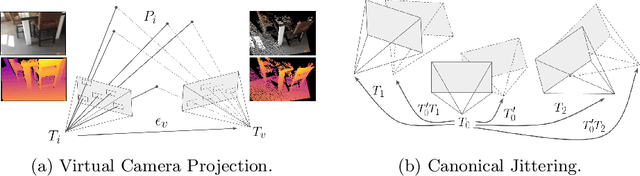
Modern 3D computer vision leverages learning to boost geometric reasoning, mapping image data to classical structures such as cost volumes or epipolar constraints to improve matching. These architectures are specialized according to the particular problem, and thus require significant task-specific tuning, often leading to poor domain generalization performance. Recently, generalist Transformer architectures have achieved impressive results in tasks such as optical flow and depth estimation by encoding geometric priors as inputs rather than as enforced constraints. In this paper, we extend this idea and propose to learn an implicit, multi-view consistent scene representation, introducing a series of 3D data augmentation techniques as a geometric inductive prior to increase view diversity. We also show that introducing view synthesis as an auxiliary task further improves depth estimation. Our Depth Field Networks (DeFiNe) achieve state-of-the-art results in stereo and video depth estimation without explicit geometric constraints, and improve on zero-shot domain generalization by a wide margin.
Towards Automated Sample Collection and Return in Extreme Underwater Environments
Dec 30, 2021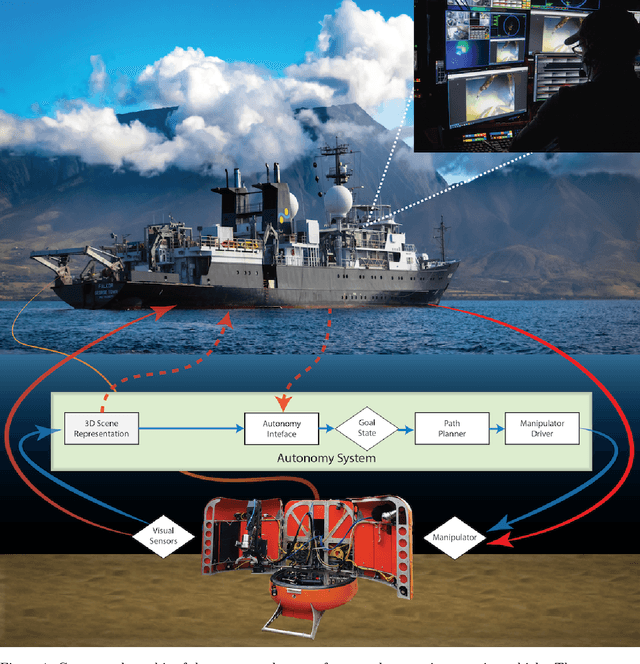



In this report, we present the system design, operational strategy, and results of coordinated multi-vehicle field demonstrations of autonomous marine robotic technologies in search-for-life missions within the Pacific shelf margin of Costa Rica and the Santorini-Kolumbo caldera complex, which serve as analogs to environments that may exist in oceans beyond Earth. This report focuses on the automation of ROV manipulator operations for targeted biological sample-collection-and-return from the seafloor. In the context of future extraterrestrial exploration missions to ocean worlds, an ROV is an analog to a planetary lander, which must be capable of high-level autonomy. Our field trials involve two underwater vehicles, the SuBastian ROV and the Nereid Under Ice (NUI) hybrid ROV for mixed initiative (i.e., teleoperated or autonomous) missions, both equipped 7-DoF hydraulic manipulators. We describe an adaptable, hardware-independent computer vision architecture that enables high-level automated manipulation. The vision system provides a 3D understanding of the workspace to inform manipulator motion planning in complex unstructured environments. We demonstrate the effectiveness of the vision system and control framework through field trials in increasingly challenging environments, including the automated collection and return of biological samples from within the active undersea volcano, Kolumbo. Based on our experiences in the field, we discuss the performance of our system and identify promising directions for future research.
Grasp and Motion Planning for Dexterous Manipulation for the Real Robot Challenge
Jan 08, 2021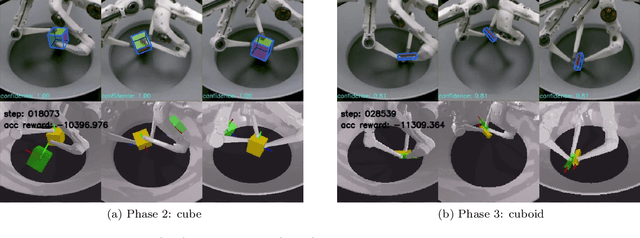

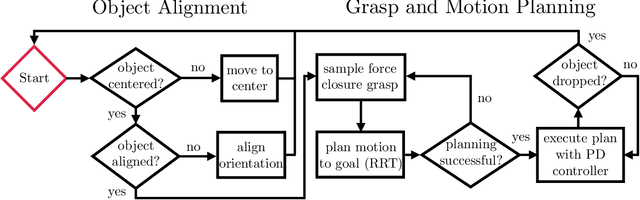
This report describes our winning submission to the Real Robot Challenge (https://real-robot-challenge.com/). The Real Robot Challenge is a three-phase dexterous manipulation competition that involves manipulating various rectangular objects with the TriFinger Platform. Our approach combines motion planning with several motion primitives to manipulate the object. For Phases 1 and 2, we additionally learn a residual policy in simulation that applies corrective actions on top of our controller. Our approach won first place in Phase 2 and Phase 3 of the competition. We were anonymously known as `ardentstork' on the competition leaderboard (https://real-robot-challenge.com/leader-board). Videos and our code can be found at https://github.com/ripl-ttic/real-robot-challenge.
Generalized Grounding Graphs: A Probabilistic Framework for Understanding Grounded Commands
Nov 29, 2017
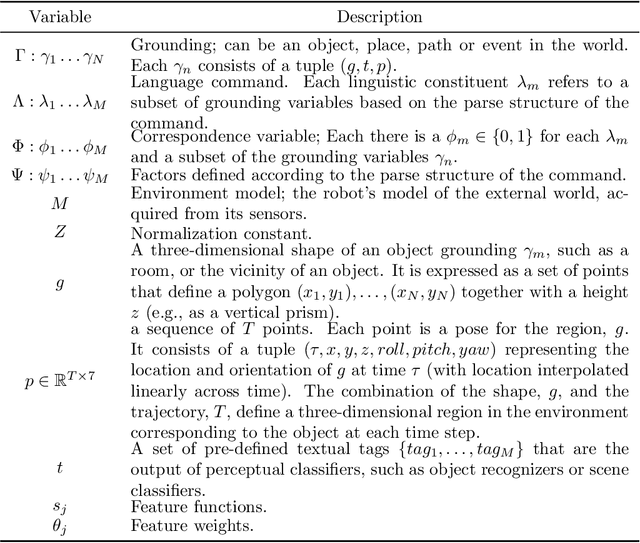
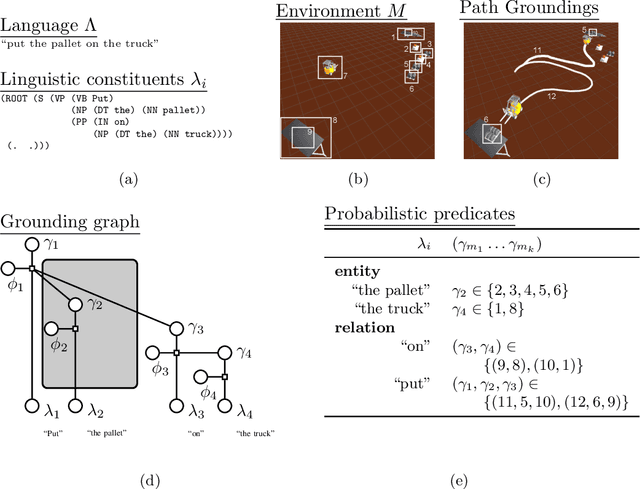
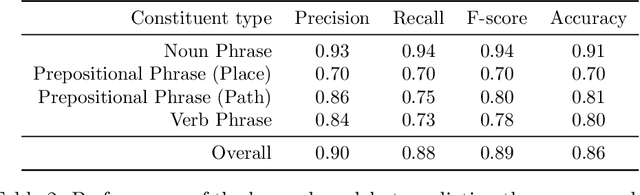
Many task domains require robots to interpret and act upon natural language commands which are given by people and which refer to the robot's physical surroundings. Such interpretation is known variously as the symbol grounding problem, grounded semantics and grounded language acquisition. This problem is challenging because people employ diverse vocabulary and grammar, and because robots have substantial uncertainty about the nature and contents of their surroundings, making it difficult to associate the constitutive language elements (principally noun phrases and spatial relations) of the command text to elements of those surroundings. Symbolic models capture linguistic structure but have not scaled successfully to handle the diverse language produced by untrained users. Existing statistical approaches can better handle diversity, but have not to date modeled complex linguistic structure, limiting achievable accuracy. Recent hybrid approaches have addressed limitations in scaling and complexity, but have not effectively associated linguistic and perceptual features. Our framework, called Generalized Grounding Graphs (G^3), addresses these issues by defining a probabilistic graphical model dynamically according to the linguistic parse structure of a natural language command. This approach scales effectively, handles linguistic diversity, and enables the system to associate parts of a command with the specific objects, places, and events in the external world to which they refer. We show that robots can learn word meanings and use those learned meanings to robustly follow natural language commands produced by untrained users. We demonstrate our approach for both mobility commands and mobile manipulation commands involving a variety of semi-autonomous robotic platforms, including a wheelchair, a micro-air vehicle, a forklift, and the Willow Garage PR2.