 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetrically Scaled Monocular Depth Estimation through Sparse Priors for Underwater Robots
Oct 25, 2023



In this work, we address the problem of real-time dense depth estimation from monocular images for mobile underwater vehicles. We formulate a deep learning model that fuses sparse depth measurements from triangulated features to improve the depth predictions and solve the problem of scale ambiguity. To allow prior inputs of arbitrary sparsity, we apply a dense parameterization method. Our model extends recent state-of-the-art approaches to monocular image based depth estimation, using an efficient encoder-decoder backbone and modern lightweight transformer optimization stage to encode global context. The network is trained in a supervised fashion on the forward-looking underwater dataset, FLSea. Evaluation results on this dataset demonstrate significant improvement in depth prediction accuracy by the fusion of the sparse feature priors. In addition, without any retraining, our method achieves similar depth prediction accuracy on a downward looking dataset we collected with a diver operated camera rig, conducting a survey of a coral reef. The method achieves real-time performance, running at 160 FPS on a laptop GPU and 7 FPS on a single CPU core and is suitable for direct deployment on embedded systems. The implementation of this work is made publicly available at https://github.com/ebnerluca/uw_depth.
Enhancing scientific exploration of the deep sea through shared autonomy in remote manipulation
Sep 15, 2023Shared autonomy enables novice remote users to conduct deep-ocean science operations with robotic manipulators.
Towards Automated Sample Collection and Return in Extreme Underwater Environments
Dec 30, 2021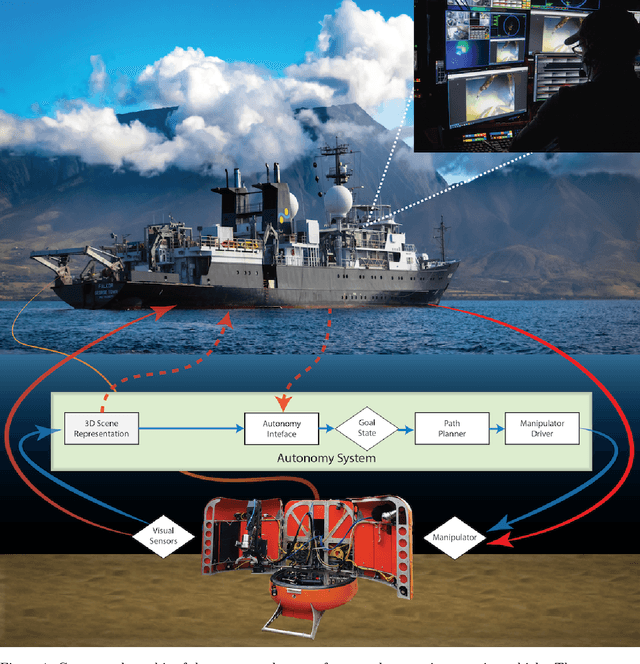



In this report, we present the system design, operational strategy, and results of coordinated multi-vehicle field demonstrations of autonomous marine robotic technologies in search-for-life missions within the Pacific shelf margin of Costa Rica and the Santorini-Kolumbo caldera complex, which serve as analogs to environments that may exist in oceans beyond Earth. This report focuses on the automation of ROV manipulator operations for targeted biological sample-collection-and-return from the seafloor. In the context of future extraterrestrial exploration missions to ocean worlds, an ROV is an analog to a planetary lander, which must be capable of high-level autonomy. Our field trials involve two underwater vehicles, the SuBastian ROV and the Nereid Under Ice (NUI) hybrid ROV for mixed initiative (i.e., teleoperated or autonomous) missions, both equipped 7-DoF hydraulic manipulators. We describe an adaptable, hardware-independent computer vision architecture that enables high-level automated manipulation. The vision system provides a 3D understanding of the workspace to inform manipulator motion planning in complex unstructured environments. We demonstrate the effectiveness of the vision system and control framework through field trials in increasingly challenging environments, including the automated collection and return of biological samples from within the active undersea volcano, Kolumbo. Based on our experiences in the field, we discuss the performance of our system and identify promising directions for future research.
Hybrid Visual SLAM for Underwater Vehicle Manipulator Systems
Dec 07, 2021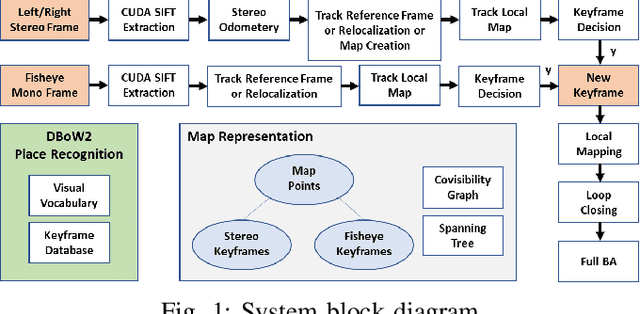



This paper presents a novel visual scene mapping method for underwater vehicle manipulator systems (UVMSs), with specific emphasis on robust mapping in natural seafloor environments. Prior methods for underwater scene mapping typically process the data offline, while existing underwater SLAM methods that run in real-time are generally focused on localization and not mapping. Our method uses GPU accelerated SIFT features in a graph optimization framework to build a feature map. The map scale is constrained by features from a vehicle mounted stereo camera, and we exploit the dynamic positioning capability of the manipulator system by fusing features from a wrist mounted fisheye camera into the map to extend it beyond the limited viewpoint of the vehicle mounted cameras. Our hybrid SLAM method is evaluated on challenging image sequences collected with a UVMS in natural deep seafloor environments of the Costa Rican continental shelf margin, and we also evaluate the stereo only mode on a shallow reef survey dataset. Results on these datasets demonstrate the high accuracy of our system and suitability for operating in diverse and natural seafloor environments.
Parametric Design of Underwater Optical Systems
Apr 14, 2020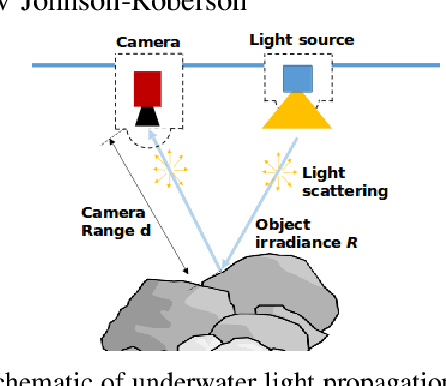



The design of optical systems for underwater vehicles is a complex process where the selection of cameras, lenses, housings, and operational parameters greatly influence the performance of the complete system. Determining the correct combination of components and parameters for a given set of operational requirements is currently a process based on trial and error as well as the specialized knowledge and experience of the designer. In this paper, we introduce an open-source tool for the parametric exploration of the design space of underwater optical systems and review the most significant underwater light effects with the corresponding models to estimate the response and performance of the complete imaging system.
SilhoNet-Fisheye: Adaptation of A ROI Based Object Pose Estimation Network to Monocular Fisheye Images
Feb 27, 2020



There has been much recent interest in deep learning methods for monocular image based object pose estimation. While object pose estimation is an important problem for autonomous robot interaction with the physical world, and the application space for monocular-based methods is expansive, there has been little work on applying these methods with fisheye imaging systems. Also, little exists in the way of annotated fisheye image datasets on which these methods can be developed and tested. The research landscape is even more sparse for object detection methods applied in the underwater domain, fisheye image based or otherwise. In this work, we present a novel framework for adapting a ROI-based 6D object pose estimation method to work on full fisheye images. The method incorporates the gnomic projection of regions of interest from an intermediate spherical image representation to correct for the fisheye distortions. Further, we contribute a fisheye image dataset, called UWHandles, collected in natural underwater environments, with 6D object pose and 2D bounding box annotations.
SilhoNet: An RGB Method for 6D Object Pose Estimation
Mar 06, 2019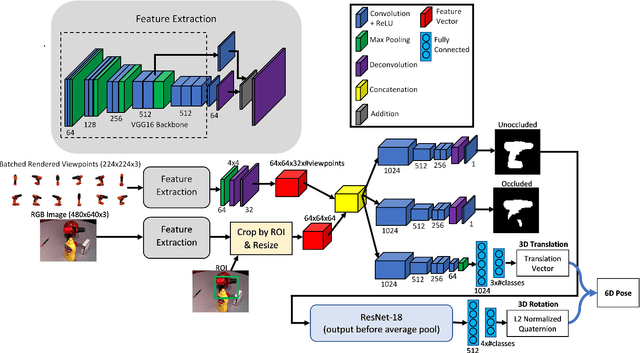
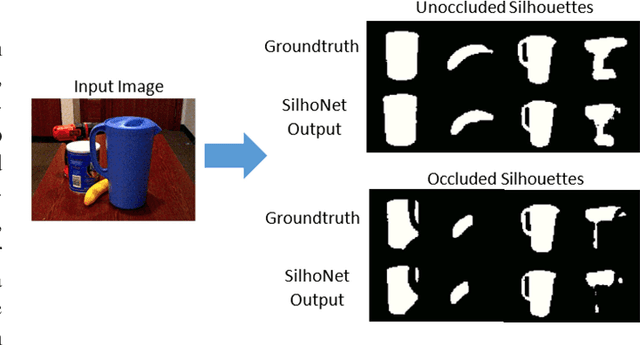
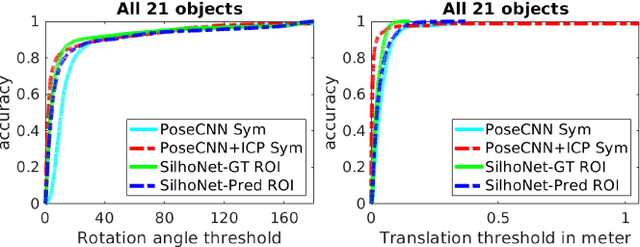

Autonomous robot manipulation involves estimating the pose of the object to be manipulated. Methods using RGB-D data have shown great success in solving this problem. However, there are situations where cost constraints or the working environment may limit the use of RGB-D sensors. When limited to monocular camera data only, the problem of object pose estimation is very challenging. In this work, we introduce a novel method called SilhoNet that predicts 6D object pose from monocular images. We use a Convolutional Neural Network (CNN) pipeline that takes in region of interest proposals to simultaneously predict an intermediate silhouette representation for objects with an associated occlusion mask and a 3D translation vector. The 3D orientation is then regressed from the predicted silhouettes. We show that our method achieves better overall performance than the state-of-the art PoseCNN network for 6D pose estimation.