 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBALTIC: A Benchmark and Cross-Domain Strategy for 3D Reconstruction Across Air and Underwater Domains Under Varying Illumination
Apr 21, 2026Robust 3D reconstruction across varying environmental conditions remains a critical challenge for robotic perception, particularly when transitioning between air and water. To address this, we introduce BALTIC, a controlled benchmark designed to systematically evaluate modern 3D reconstruction methods under variations in medium and lighting. The benchmark comprises 13 datasets spanning two media (air and water) and three lighting conditions (ambient, artificial, and mixed), with additional variations in motion type, scanning pattern, and initialization trajectory, resulting in a diverse set of sequences. Our experimental setup features a custom water tank equipped with a monocular camera and an HTC Vive tracker, enabling accurate ground-truth pose estimation. We further investigate cross-domain reconstruction by augmenting underwater image sequences with a small number of in-air views captured under similar lighting conditions. We evaluate Structure-from-Motion reconstruction using COLMAP in terms of both trajectory accuracy and scene geometry, and use these reconstructions as input to Neural Radiance Fields and 3D Gaussian Splatting methods. The resulting models are assessed against ground-truth trajectories and in-air references, while rendered outputs are compared using perceptual and photometric metrics. Additionally, we perform a color restoration analysis to evaluate radiometric consistency across domains. Our results show that under controlled, texture-consistent conditions, Gaussian Splatting with simple preprocessing (e.g., white balance correction) can achieve performance comparable to specialized underwater methods, although its robustness decreases in more complex and heterogeneous real-world environments
Long-Term Visual Localization in Dynamic Benthic Environments: A Dataset, Footprint-Based Ground Truth, and Visual Place Recognition Benchmark
Mar 04, 2026Long-term visual localization has the potential to reduce cost and improve mapping quality in optical benthic monitoring with autonomous underwater vehicles (AUVs). Despite this potential, long-term visual localization in benthic environments remains understudied, primarily due to the lack of curated datasets for benchmarking. Moreover, limited georeferencing accuracy and image footprints necessitate precise geometric information for accurate ground-truthing. In this work, we address these gaps by presenting a curated dataset for long-term visual localization in benthic environments and a novel method to ground-truth visual localization results for near-nadir underwater imagery. Our dataset comprises georeferenced AUV imagery from five benthic reference sites, revisited over periods up to six years, and includes raw and color-corrected stereo imagery, camera calibrations, and sub-decimeter registered camera poses. To our knowledge, this is the first curated underwater dataset for long-term visual localization spanning multiple sites and photic-zone habitats. Our ground-truthing method estimates 3D seafloor image footprints and links camera views with overlapping footprints, ensuring that ground-truth links reflect shared visual content. Building on this dataset and ground truth, we benchmark eight state-of-the-art visual place recognition (VPR) methods and find that Recall@K is significantly lower on our dataset than on established terrestrial and underwater benchmarks. Finally, we compare our footprint-based ground truth to a traditional location-based ground truth and show that distance-threshold ground-truthing can overestimate VPR Recall@K at sites with rugged terrain and altitude variations. Together, the curated dataset, ground-truthing method, and VPR benchmark provide a stepping stone for advancing long-term visual localization in dynamic benthic environments.
Detecting Endangered Marine Species in Autonomous Underwater Vehicle Imagery Using Point Annotations and Few-Shot Learning
Jun 04, 2024
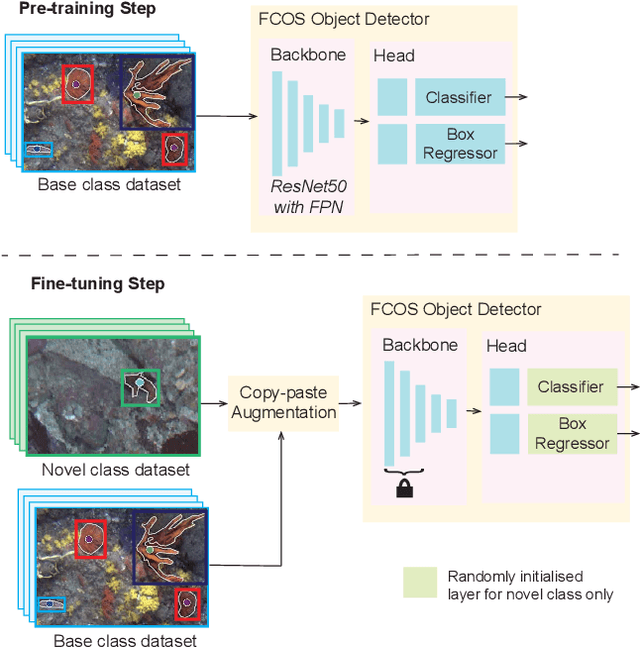


One use of Autonomous Underwater Vehicles (AUVs) is the monitoring of habitats associated with threatened, endangered and protected marine species, such as the handfish of Tasmania, Australia. Seafloor imagery collected by AUVs can be used to identify individuals within their broader habitat context, but the sheer volume of imagery collected can overwhelm efforts to locate rare or cryptic individuals. Machine learning models can be used to identify the presence of a particular species in images using a trained object detector, but the lack of training examples reduces detection performance, particularly for rare species that may only have a small number of examples in the wild. In this paper, inspired by recent work in few-shot learning, images and annotations of common marine species are exploited to enhance the ability of the detector to identify rare and cryptic species. Annotated images of six common marine species are used in two ways. Firstly, the common species are used in a pre-training step to allow the backbone to create rich features for marine species. Secondly, a copy-paste operation is used with the common species images to augment the training data. While annotations for more common marine species are available in public datasets, they are often in point format, which is unsuitable for training an object detector. A popular semantic segmentation model efficiently generates bounding box annotations for training from the available point annotations. Our proposed framework is applied to AUV images of handfish, increasing average precision by up to 48\% compared to baseline object detection training. This approach can be applied to other objects with low numbers of annotations and promises to increase the ability to actively monitor threatened, endangered and protected species.
Feature Alignment: Rethinking Efficient Active Learning via Proxy in the Context of Pre-trained Models
Mar 02, 2024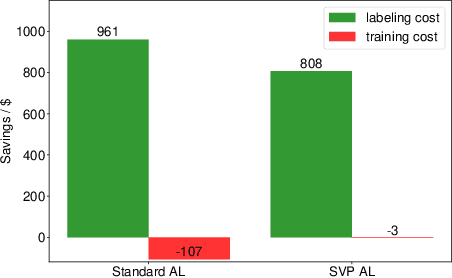
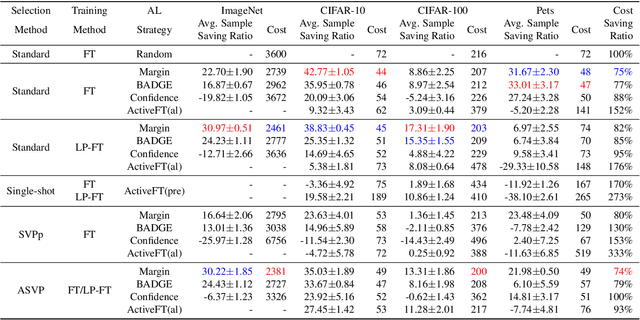
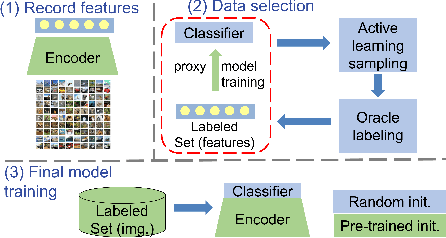
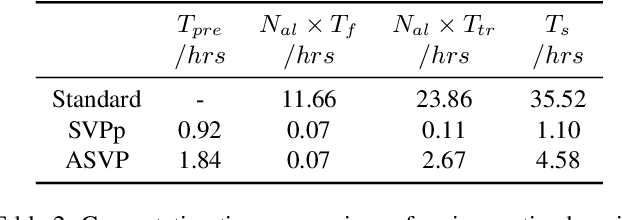
Fine-tuning the pre-trained model with active learning holds promise for reducing annotation costs. However, this combination introduces significant computational costs, particularly with the growing scale of pre-trained models. Recent research has proposed proxy-based active learning, which pre-computes features to reduce computational costs. Yet, this approach often incurs a significant loss in active learning performance, which may even outweigh the computational cost savings. In this paper, we argue the performance drop stems not only from pre-computed features' inability to distinguish between categories of labeled samples, resulting in the selection of redundant samples but also from the tendency to compromise valuable pre-trained information when fine-tuning with samples selected through the proxy model. To address this issue, we propose a novel method called aligned selection via proxy to update pre-computed features while selecting a proper training method to inherit valuable pre-training information. Extensive experiments validate that our method significantly improves the total cost of efficient active learning while maintaining computational efficiency.
A Semi-supervised Object Detection Algorithm for Underwater Imagery
Jun 07, 2023



Detection of artificial objects from underwater imagery gathered by Autonomous Underwater Vehicles (AUVs) is a key requirement for many subsea applications. Real-world AUV image datasets tend to be very large and unlabelled. Furthermore, such datasets are typically imbalanced, containing few instances of objects of interest, particularly when searching for unusual objects in a scene. It is therefore, difficult to fit models capable of reliably detecting these objects. Given these factors, we propose to treat artificial objects as anomalies and detect them through a semi-supervised framework based on Variational Autoencoders (VAEs). We develop a method which clusters image data in a learned low-dimensional latent space and extracts images that are likely to contain anomalous features. We also devise an anomaly score based on extracting poorly reconstructed regions of an image. We demonstrate that by applying both methods on large image datasets, human operators can be shown candidate anomalous samples with a low false positive rate to identify objects of interest. We apply our approach to real seafloor imagery gathered by an AUV and evaluate its sensitivity to the dimensionality of the latent representation used by the VAE. We evaluate the precision-recall tradeoff and demonstrate that by choosing an appropriate latent dimensionality and threshold, we are able to achieve an average precision of 0.64 on unlabelled datasets.
NTKCPL: Active Learning on Top of Self-Supervised Model by Estimating True Coverage
Jun 07, 2023
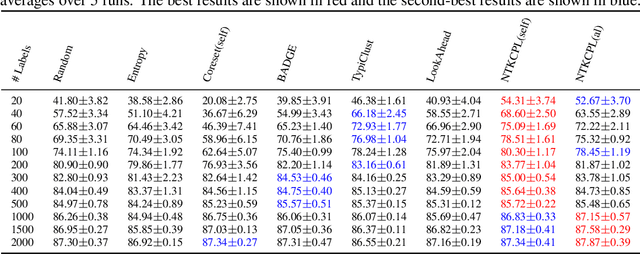
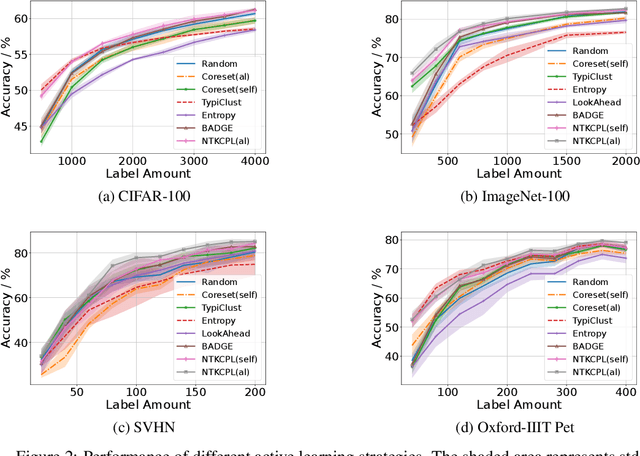
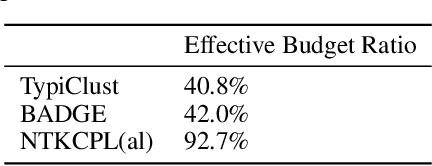
High annotation cost for training machine learning classifiers has driven extensive research in active learning and self-supervised learning. Recent research has shown that in the context of supervised learning different active learning strategies need to be applied at various stages of the training process to ensure improved performance over the random baseline. We refer to the point where the number of available annotations changes the suitable active learning strategy as the phase transition point. In this paper, we establish that when combining active learning with self-supervised models to achieve improved performance, the phase transition point occurs earlier. It becomes challenging to determine which strategy should be used for previously unseen datasets. We argue that existing active learning algorithms are heavily influenced by the phase transition because the empirical risk over the entire active learning pool estimated by these algorithms is inaccurate and influenced by the number of labeled samples. To address this issue, we propose a novel active learning strategy, neural tangent kernel clustering-pseudo-labels (NTKCPL). It estimates empirical risk based on pseudo-labels and the model prediction with NTK approximation. We analyze the factors affecting this approximation error and design a pseudo-label clustering generation method to reduce the approximation error. We validate our method on five datasets, empirically demonstrating that it outperforms the baseline methods in most cases and is valid over a wider range of training budgets.
Improved Benthic Classification using Resolution Scaling and SymmNet Unsupervised Domain Adaptation
Mar 20, 2023



Autonomous Underwater Vehicles (AUVs) conduct regular visual surveys of marine environments to characterise and monitor the composition and diversity of the benthos. The use of machine learning classifiers for this task is limited by the low numbers of annotations available and the many fine-grained classes involved. In addition to these challenges, there are domain shifts between image sets acquired during different AUV surveys due to changes in camera systems, imaging altitude, illumination and water column properties leading to a drop in classification performance for images from a different survey where some or all these elements may have changed. This paper proposes a framework to improve the performance of a benthic morphospecies classifier when used to classify images from a different survey compared to the training data. We adapt the SymmNet state-of-the-art Unsupervised Domain Adaptation method with an efficient bilinear pooling layer and image scaling to normalise spatial resolution, and show improved classification accuracy. We test our approach on two datasets with images from AUV surveys with different imaging payloads and locations. The results show that generic domain adaptation can be enhanced to produce a significant increase in accuracy for images from an AUV survey that differs from the training images.
Active Self-Semi-Supervised Learning for Few Labeled Samples Fast Training
Mar 09, 2022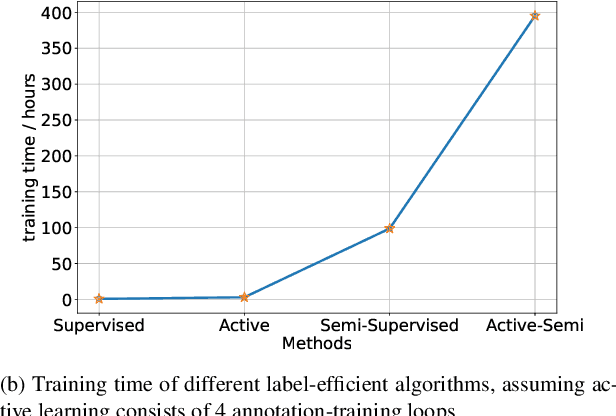
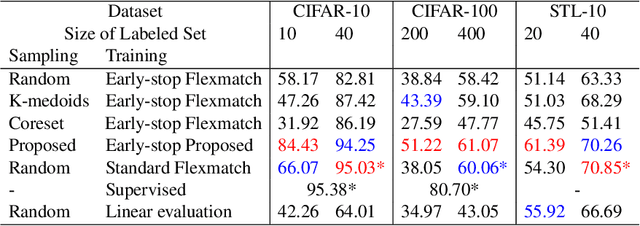


Faster training and fewer annotations are two key issues for applying deep models to various practical domains. Now, semi-supervised learning has achieved great success in training with few annotations. However, low-quality labeled samples produced by random sampling make it difficult to continue to reduce the number of annotations. In this paper we propose an active self-semi-supervised training framework that bootstraps semi-supervised models with good prior pseudo-labels, where the priors are obtained by label propagation over self-supervised features. Because the accuracy of the prior is not only affected by the quality of features, but also by the selection of the labeled samples. We develop active learning and label propagation strategies to obtain better prior pseudo-labels. Consequently, our framework can greatly improve the performance of models with few annotations and greatly reduce the training time. Experiments on three semi-supervised learning benchmarks demonstrate effectiveness. Our method achieves similar accuracy to standard semi-supervised approaches in about 1/3 of the training time, and even outperform them when fewer annotations are available (84.10\% in CIFAR-10 with 10 labels).
Maximising Wrenches for Kinematically Redundant Systems with Experiments on UVMS
Feb 28, 2022


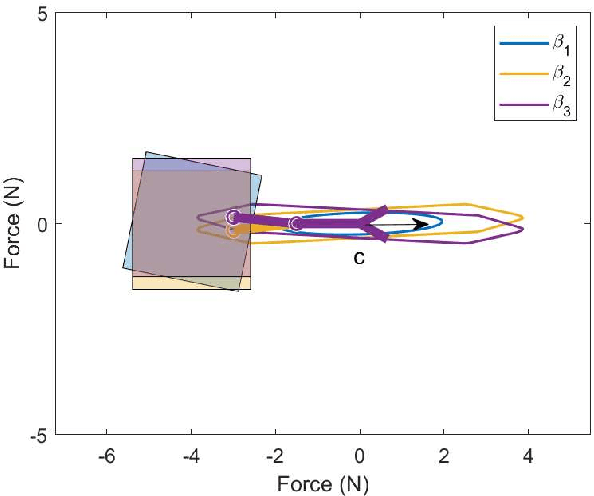
This paper presents methods for finding optimal configurations and actuator forces/torques to maximise contact wrenches in a desired direction for Underwater Vehicles Manipulator Systems (UVMS). The wrench maximisation problem is formulated as a linear programming problem, and the optimal configuration is solved as a bi-level optimisation in the parameterised redundancy space. We additionally consider the cases of one or more manipulators with multiple contact forces, maximising wrench capability while tracking a trajectory, and generating large wrench impulses using dynamic motions. We look at the specific cases of maximising force to lift a heavy load, and maximising torque during a valve turning operation. Extensive experimental results are presented using an underwater robotic platform equipped with a 4DOF manipulator, and show significant increases in wrench capability compared to existing methods for UVMS.
Towards Automated Sample Collection and Return in Extreme Underwater Environments
Dec 30, 2021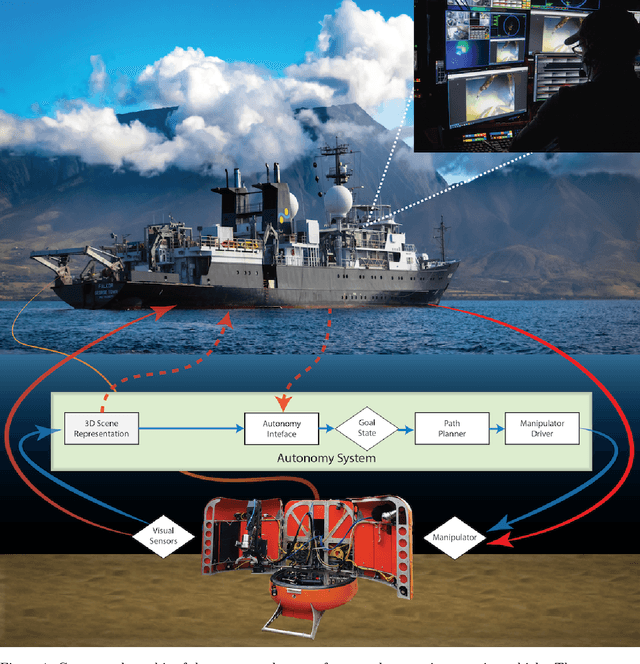



In this report, we present the system design, operational strategy, and results of coordinated multi-vehicle field demonstrations of autonomous marine robotic technologies in search-for-life missions within the Pacific shelf margin of Costa Rica and the Santorini-Kolumbo caldera complex, which serve as analogs to environments that may exist in oceans beyond Earth. This report focuses on the automation of ROV manipulator operations for targeted biological sample-collection-and-return from the seafloor. In the context of future extraterrestrial exploration missions to ocean worlds, an ROV is an analog to a planetary lander, which must be capable of high-level autonomy. Our field trials involve two underwater vehicles, the SuBastian ROV and the Nereid Under Ice (NUI) hybrid ROV for mixed initiative (i.e., teleoperated or autonomous) missions, both equipped 7-DoF hydraulic manipulators. We describe an adaptable, hardware-independent computer vision architecture that enables high-level automated manipulation. The vision system provides a 3D understanding of the workspace to inform manipulator motion planning in complex unstructured environments. We demonstrate the effectiveness of the vision system and control framework through field trials in increasingly challenging environments, including the automated collection and return of biological samples from within the active undersea volcano, Kolumbo. Based on our experiences in the field, we discuss the performance of our system and identify promising directions for future research.