 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoCLR: Georeference Contrastive Learning for Efficient Seafloor Image Interpretation
Paper and Code
Aug 13, 2021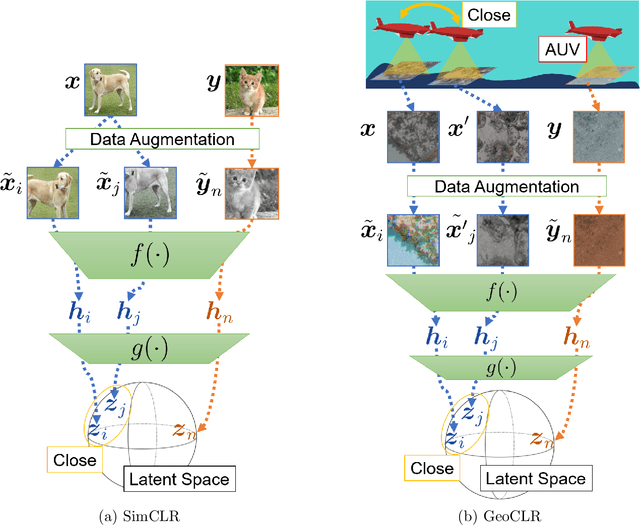


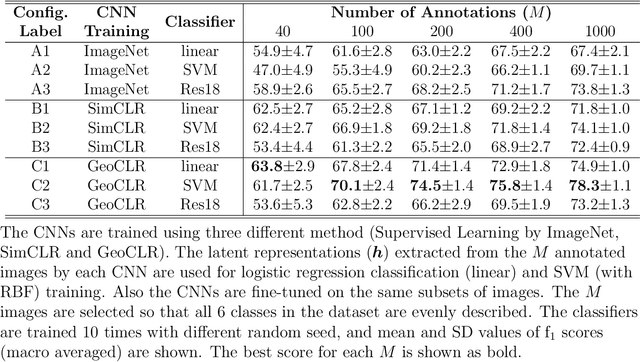
This paper describes Georeference Contrastive Learning of visual Representation (GeoCLR) for efficient training of deep-learning Convolutional Neural Networks (CNNs). The method leverages georeference information by generating a similar image pair using images taken of nearby locations, and contrasting these with an image pair that is far apart. The underlying assumption is that images gathered within a close distance are more likely to have similar visual appearance, where this can be reasonably satisfied in seafloor robotic imaging applications where image footprints are limited to edge lengths of a few metres and are taken so that they overlap along a vehicle's trajectory, whereas seafloor substrates and habitats have patch sizes that are far larger. A key advantage of this method is that it is self-supervised and does not require any human input for CNN training. The method is computationally efficient, where results can be generated between dives during multi-day AUV missions using computational resources that would be accessible during most oceanic field trials. We apply GeoCLR to habitat classification on a dataset that consists of ~86k images gathered using an Autonomous Underwater Vehicle (AUV). We demonstrate how the latent representations generated by GeoCLR can be used to efficiently guide human annotation efforts, where the semi-supervised framework improves classification accuracy by an average of 11.8 % compared to state-of-the-art transfer learning using the same CNN and equivalent number of human annotations for training.