 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Deep Thinking: Stable Learning of Algorithms using Lipschitz Constraints
Oct 30, 2024Iterative algorithms solve problems by taking steps until a solution is reached. Models in the form of Deep Thinking (DT) networks have been demonstrated to learn iterative algorithms in a way that can scale to different sized problems at inference time using recurrent computation and convolutions. However, they are often unstable during training, and have no guarantees of convergence/termination at the solution. This paper addresses the problem of instability by analyzing the growth in intermediate representations, allowing us to build models (referred to as Deep Thinking with Lipschitz Constraints (DT-L)) with many fewer parameters and providing more reliable solutions. Additionally our DT-L formulation provides guarantees of convergence of the learned iterative procedure to a unique solution at inference time. We demonstrate DT-L is capable of robustly learning algorithms which extrapolate to harder problems than in the training set. We benchmark on the traveling salesperson problem to evaluate the capabilities of the modified system in an NP-hard problem where DT fails to learn.
Semantic Segmentation by Semantic Proportions
May 24, 2023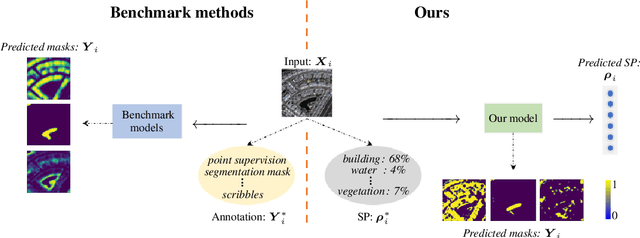


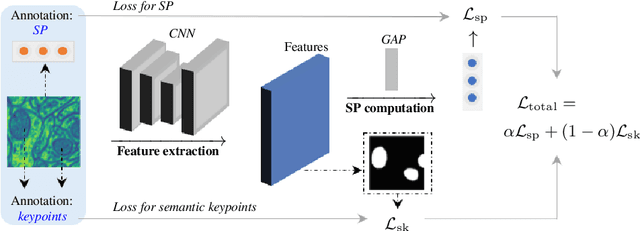
Semantic segmentation is a critical task in computer vision that aims to identify and classify individual pixels in an image, with numerous applications for example autonomous driving and medical image analysis. However, semantic segmentation can be super challenging particularly due to the need for large amounts of annotated data. Annotating images is a time-consuming and costly process, often requiring expert knowledge and significant effort. In this paper, we propose a novel approach for semantic segmentation by eliminating the need of ground-truth segmentation maps. Instead, our approach requires only the rough information of individual semantic class proportions, shortened as semantic proportions. It greatly simplifies the data annotation process and thus will significantly reduce the annotation time and cost, making it more feasible for large-scale applications. Moreover, it opens up new possibilities for semantic segmentation tasks where obtaining the full ground-truth segmentation maps may not be feasible or practical. Extensive experimental results demonstrate that our approach can achieve comparable and sometimes even better performance against the benchmark method that relies on the ground-truth segmentation maps. Utilising semantic proportions suggested in this work offers a promising direction for future research in the field of semantic segmentation.
Generalisation and the Risk--Entropy Curve
Feb 15, 2022



In this paper we show that the expected generalisation performance of a learning machine is determined by the distribution of risks or equivalently its logarithm -- a quantity we term the risk entropy -- and the fluctuations in a quantity we call the training ratio. We show that the risk entropy can be empirically inferred for deep neural network models using Markov Chain Monte Carlo techniques. Results are presented for different deep neural networks on a variety of problems. The asymptotic behaviour of the risk entropy acts in an analogous way to the capacity of the learning machine, but the generalisation performance experienced in practical situations is determined by the behaviour of the risk entropy before the asymptotic regime is reached. This performance is strongly dependent on the distribution of the data (features and targets) and not just on the capacity of the learning machine.
Orthogonalising gradients to speed up neural network optimisation
Feb 14, 2022
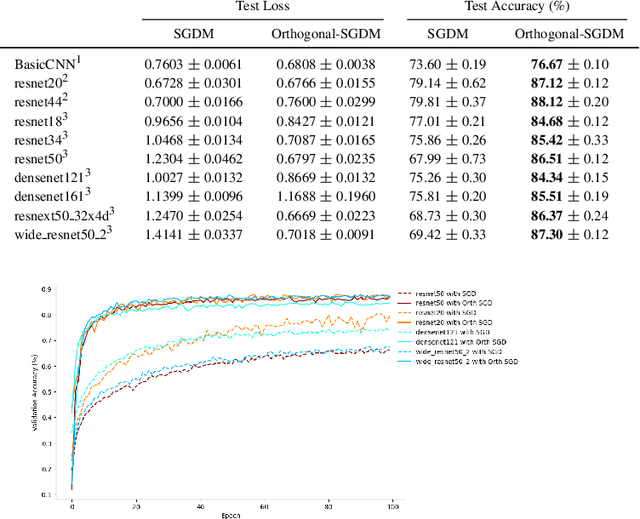
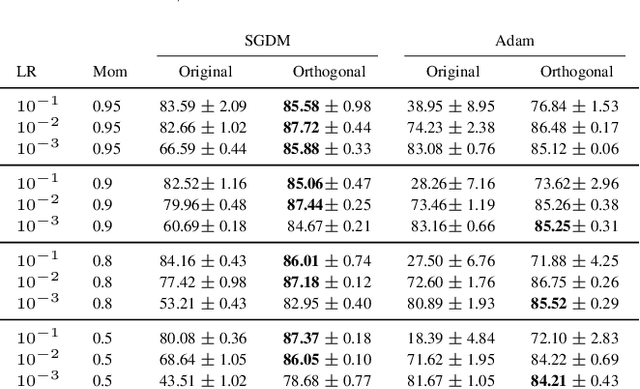

The optimisation of neural networks can be sped up by orthogonalising the gradients before the optimisation step, ensuring the diversification of the learned representations. We orthogonalise the gradients of the layer's components/filters with respect to each other to separate out the intermediate representations. Our method of orthogonalisation allows the weights to be used more flexibly, in contrast to restricting the weights to an orthogonalised sub-space. We tested this method on ImageNet and CIFAR-10 resulting in a large decrease in learning time, and also obtain a speed-up on the semi-supervised learning BarlowTwins. We obtain similar accuracy to SGD without fine-tuning and better accuracy for na\"ively chosen hyper-parameters.
On Data-centric Myths
Nov 22, 2021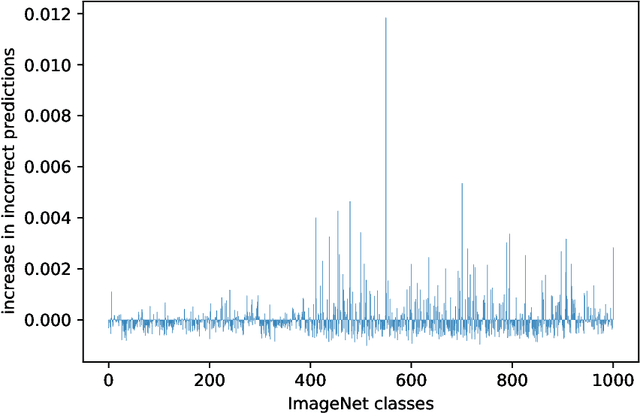

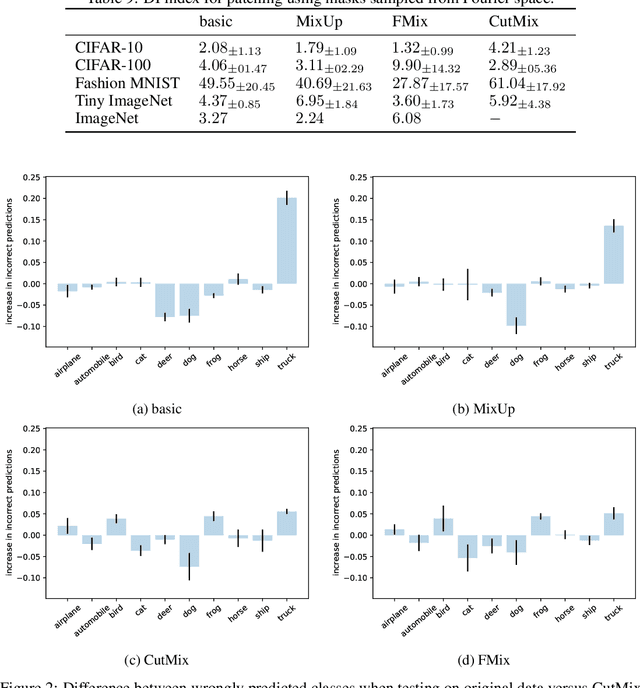

The community lacks theory-informed guidelines for building good data sets. We analyse theoretical directions relating to what aspects of the data matter and conclude that the intuitions derived from the existing literature are incorrect and misleading. Using empirical counter-examples, we show that 1) data dimension should not necessarily be minimised and 2) when manipulating data, preserving the distribution is inessential. This calls for a more data-aware theoretical understanding. Although not explored in this work, we propose the study of the impact of data modification on learned representations as a promising research direction.
On the Effects of Data Distortion on Model Analysis and Training
Oct 26, 2021



Data modification can introduce artificial information. It is often assumed that the resulting artefacts are detrimental to training, whilst being negligible when analysing models. We investigate these assumptions and conclude that in some cases they are unfounded and lead to incorrect results. Specifically, we show current shape bias identification methods and occlusion robustness measures are biased and propose a fairer alternative for the latter. Subsequently, through a series of experiments we seek to correct and strengthen the community's perception of how distorting data affects learning. Based on our empirical results we argue that the impact of the artefacts must be understood and exploited rather than eliminated.
GeoCLR: Georeference Contrastive Learning for Efficient Seafloor Image Interpretation
Aug 13, 2021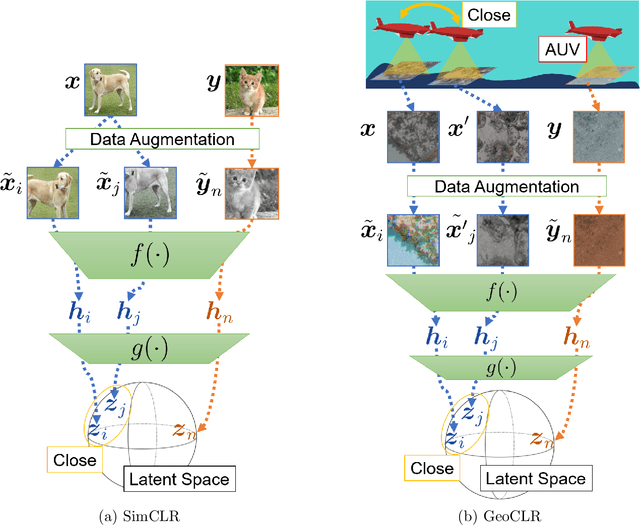


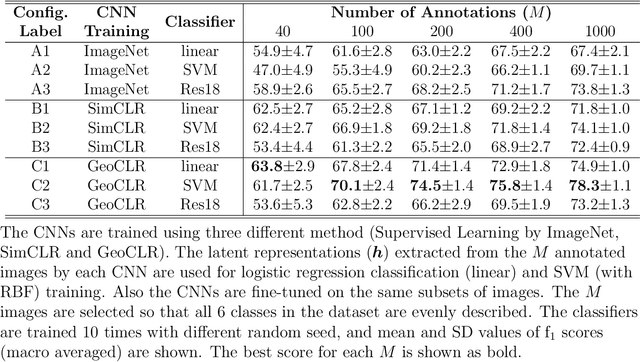
This paper describes Georeference Contrastive Learning of visual Representation (GeoCLR) for efficient training of deep-learning Convolutional Neural Networks (CNNs). The method leverages georeference information by generating a similar image pair using images taken of nearby locations, and contrasting these with an image pair that is far apart. The underlying assumption is that images gathered within a close distance are more likely to have similar visual appearance, where this can be reasonably satisfied in seafloor robotic imaging applications where image footprints are limited to edge lengths of a few metres and are taken so that they overlap along a vehicle's trajectory, whereas seafloor substrates and habitats have patch sizes that are far larger. A key advantage of this method is that it is self-supervised and does not require any human input for CNN training. The method is computationally efficient, where results can be generated between dives during multi-day AUV missions using computational resources that would be accessible during most oceanic field trials. We apply GeoCLR to habitat classification on a dataset that consists of ~86k images gathered using an Autonomous Underwater Vehicle (AUV). We demonstrate how the latent representations generated by GeoCLR can be used to efficiently guide human annotation efforts, where the semi-supervised framework improves classification accuracy by an average of 11.8 % compared to state-of-the-art transfer learning using the same CNN and equivalent number of human annotations for training.
Language Models as Zero-shot Visual Semantic Learners
Jul 26, 2021Visual Semantic Embedding (VSE) models, which map images into a rich semantic embedding space, have been a milestone in object recognition and zero-shot learning. Current approaches to VSE heavily rely on static word em-bedding techniques. In this work, we propose a Visual Se-mantic Embedding Probe (VSEP) designed to probe the semantic information of contextualized word embeddings in visual semantic understanding tasks. We show that the knowledge encoded in transformer language models can be exploited for tasks requiring visual semantic understanding.The VSEP with contextual representations can distinguish word-level object representations in complicated scenes as a compositional zero-shot learner. We further introduce a zero-shot setting with VSEPs to evaluate a model's ability to associate a novel word with a novel visual category. We find that contextual representations in language mod-els outperform static word embeddings, when the compositional chain of object is short. We notice that current visual semantic embedding models lack a mutual exclusivity bias which limits their performance.
What Remains of Visual Semantic Embeddings
Jul 26, 2021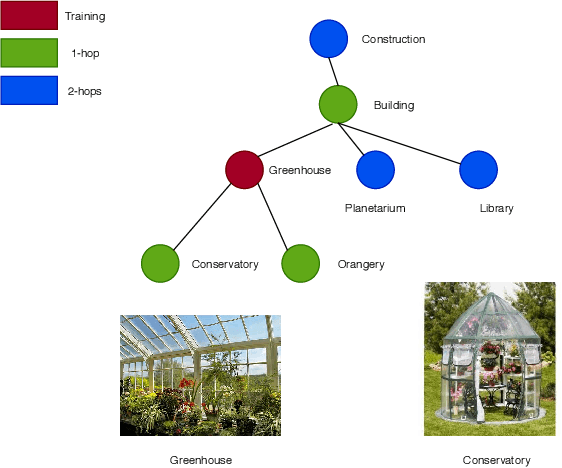

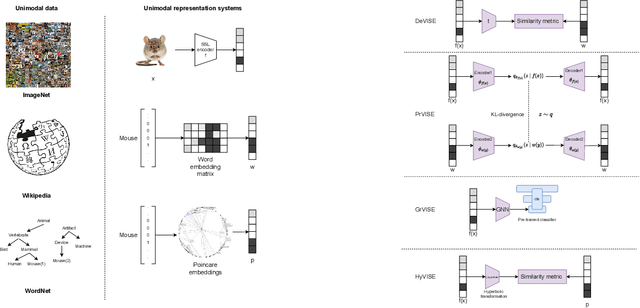
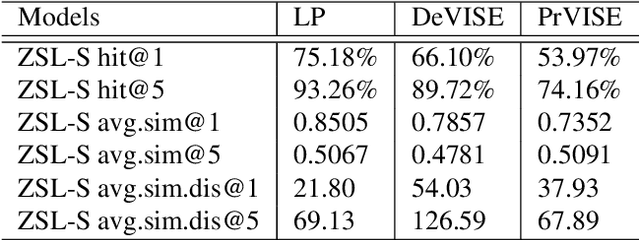
Zero shot learning (ZSL) has seen a surge in interest over the decade for its tight links with the mechanism making young children recognize novel objects. Although different paradigms of visual semantic embedding models are designed to align visual features and distributed word representations, it is unclear to what extent current ZSL models encode semantic information from distributed word representations. In this work, we introduce the split of tiered-ImageNet to the ZSL task, in order to avoid the structural flaws in the standard ImageNet benchmark. We build a unified framework for ZSL with contrastive learning as pre-training, which guarantees no semantic information leakage and encourages linearly separable visual features. Our work makes it fair for evaluating visual semantic embedding models on a ZSL setting in which semantic inference is decisive. With this framework, we show that current ZSL models struggle with encoding semantic relationships from word analogy and word hierarchy. Our analyses provide motivation for exploring the role of context language representations in ZSL tasks.
Object detection for crabs in top-view seabed imagery
May 02, 2021
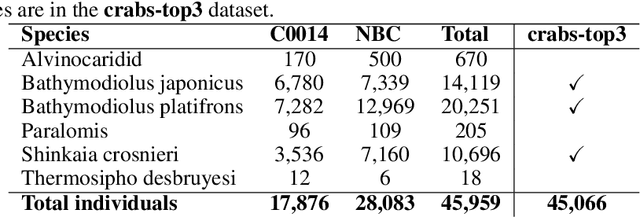
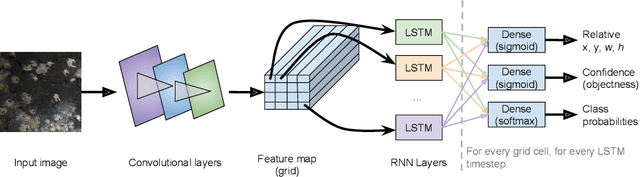
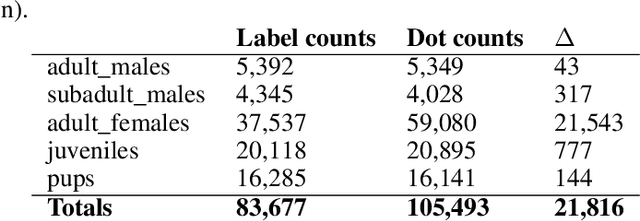
This report presents the application of object detection on a database of underwater images of different species of crabs, as well as aerial images of sea lions and finally the Pascal VOC dataset. The model is an end-to-end object detection neural network based on a convolutional network base and a Long Short-Term Memory detector.