 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Off-Policy Deep Reinforcement Learning Doesn't Have to be Slow
Dec 23, 2025



Recurrent off-policy deep reinforcement learning models achieve state-of-the-art performance but are often sidelined due to their high computational demands. In response, we introduce RISE (Recurrent Integration via Simplified Encodings), a novel approach that can leverage recurrent networks in any image-based off-policy RL setting without significant computational overheads via using both learnable and non-learnable encoder layers. When integrating RISE into leading non-recurrent off-policy RL algorithms, we observe a 35.6% human-normalized interquartile mean (IQM) performance improvement across the Atari benchmark. We analyze various implementation strategies to highlight the versatility and potential of our proposed framework.
Beyond The Rainbow: High Performance Deep Reinforcement Learning On A Desktop PC
Nov 06, 2024



Rainbow Deep Q-Network (DQN) demonstrated combining multiple independent enhancements could significantly boost a reinforcement learning (RL) agent's performance. In this paper, we present "Beyond The Rainbow" (BTR), a novel algorithm that integrates six improvements from across the RL literature to Rainbow DQN, establishing a new state-of-the-art for RL using a desktop PC, with a human-normalized interquartile mean (IQM) of 7.4 on atari-60. Beyond Atari, we demonstrate BTR's capability to handle complex 3D games, successfully training agents to play Super Mario Galaxy, Mario Kart, and Mortal Kombat with minimal algorithmic changes. Designing BTR with computational efficiency in mind, agents can be trained using a desktop PC on 200 million Atari frames within 12 hours. Additionally, we conduct detailed ablation studies of each component, analzying the performance and impact using numerous measures.
Rethinking Deep Thinking: Stable Learning of Algorithms using Lipschitz Constraints
Oct 30, 2024Iterative algorithms solve problems by taking steps until a solution is reached. Models in the form of Deep Thinking (DT) networks have been demonstrated to learn iterative algorithms in a way that can scale to different sized problems at inference time using recurrent computation and convolutions. However, they are often unstable during training, and have no guarantees of convergence/termination at the solution. This paper addresses the problem of instability by analyzing the growth in intermediate representations, allowing us to build models (referred to as Deep Thinking with Lipschitz Constraints (DT-L)) with many fewer parameters and providing more reliable solutions. Additionally our DT-L formulation provides guarantees of convergence of the learned iterative procedure to a unique solution at inference time. We demonstrate DT-L is capable of robustly learning algorithms which extrapolate to harder problems than in the training set. We benchmark on the traveling salesperson problem to evaluate the capabilities of the modified system in an NP-hard problem where DT fails to learn.
Dynamic DNNs and Runtime Management for Efficient Inference on Mobile/Embedded Devices
Jan 17, 2024Deep neural network (DNN) inference is increasingly being executed on mobile and embedded platforms due to several key advantages in latency, privacy and always-on availability. However, due to limited computing resources, efficient DNN deployment on mobile and embedded platforms is challenging. Although many hardware accelerators and static model compression methods were proposed by previous works, at system runtime, multiple applications are typically executed concurrently and compete for hardware resources. This raises two main challenges: Runtime Hardware Availability and Runtime Application Variability. Previous works have addressed these challenges through either dynamic neural networks that contain sub-networks with different performance trade-offs or runtime hardware resource management. In this thesis, we proposed a combined method, a system was developed for DNN performance trade-off management, combining the runtime trade-off opportunities in both algorithms and hardware to meet dynamically changing application performance targets and hardware constraints in real time. We co-designed novel Dynamic Super-Networks to maximise runtime system-level performance and energy efficiency on heterogeneous hardware platforms. Compared with SOTA, our experimental results using ImageNet on the GPU of Jetson Xavier NX show our model is 2.4x faster for similar ImageNet Top-1 accuracy, or 5.1% higher accuracy at similar latency. We also designed a hierarchical runtime resource manager that tunes both dynamic neural networks and DVFS at runtime. Compared with the Linux DVFS governor schedutil, our runtime approach achieves up to a 19% energy reduction and a 9% latency reduction in single model deployment scenario, and an 89% energy reduction and a 23% latency reduction in a two concurrent model deployment scenario.
Fluid Dynamic DNNs for Reliable and Adaptive Distributed Inference on Edge Devices
Jan 17, 2024

Distributed inference is a popular approach for efficient DNN inference at the edge. However, traditional Static and Dynamic DNNs are not distribution-friendly, causing system reliability and adaptability issues. In this paper, we introduce Fluid Dynamic DNNs (Fluid DyDNNs), tailored for distributed inference. Distinct from Static and Dynamic DNNs, Fluid DyDNNs utilize a novel nested incremental training algorithm to enable independent and combined operation of its sub-networks, enhancing system reliability and adaptability. Evaluation on embedded Arm CPUs with a DNN model and the MNIST dataset, shows that in scenarios of single device failure, Fluid DyDNNs ensure continued inference, whereas Static and Dynamic DNNs fail. When devices are fully operational, Fluid DyDNNs can operate in either a High-Accuracy mode and achieve comparable accuracy with Static DNNs, or in a High-Throughput mode and achieve 2.5x and 2x throughput compared with Static and Dynamic DNNs, respectively.
Improving the Robustness of Neural Multiplication Units with Reversible Stochasticity
Nov 10, 2022Multilayer Perceptrons struggle to learn certain simple arithmetic tasks. Specialist neural modules for arithmetic can outperform classical architectures with gains in extrapolation, interpretability and convergence speeds, but are highly sensitive to the training range. In this paper, we show that Neural Multiplication Units (NMUs) are unable to reliably learn tasks as simple as multiplying two inputs when given different training ranges. Causes of failure are linked to inductive and input biases which encourage convergence to solutions in undesirable optima. A solution, the stochastic NMU (sNMU), is proposed to apply reversible stochasticity, encouraging avoidance of such optima whilst converging to the true solution. Empirically, we show that stochasticity provides improved robustness with the potential to improve learned representations of upstream networks for numerical and image tasks.
Physically Embodied Deep Image Optimisation
Jan 20, 2022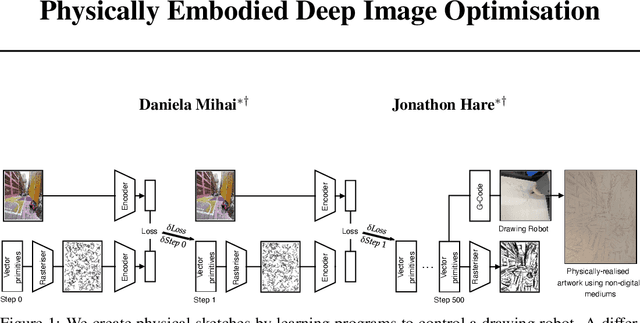



Physical sketches are created by learning programs to control a drawing robot. A differentiable rasteriser is used to optimise sets of drawing strokes to match an input image, using deep networks to provide an encoding for which we can compute a loss. The optimised drawing primitives can then be translated into G-code commands which command a robot to draw the image using drawing instruments such as pens and pencils on a physical support medium.
Shared Visual Representations of Drawing for Communication: How do different biases affect human interpretability and intent?
Oct 15, 2021
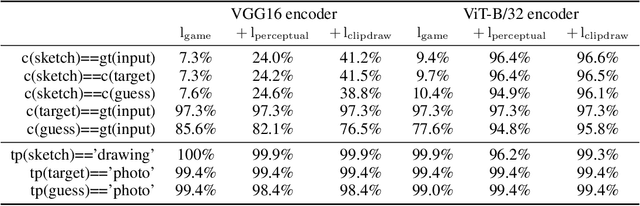


We present an investigation into how representational losses can affect the drawings produced by artificial agents playing a communication game. Building upon recent advances, we show that a combination of powerful pretrained encoder networks, with appropriate inductive biases, can lead to agents that draw recognisable sketches, whilst still communicating well. Further, we start to develop an approach to help automatically analyse the semantic content being conveyed by a sketch and demonstrate that current approaches to inducing perceptual biases lead to a notion of objectness being a key feature despite the agent training being self-supervised.
Learning Division with Neural Arithmetic Logic Modules
Oct 12, 2021
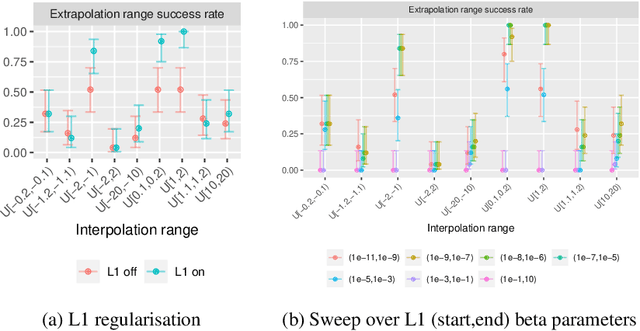


To achieve systematic generalisation, it first makes sense to master simple tasks such as arithmetic. Of the four fundamental arithmetic operations (+,-,$\times$,$\div$), division is considered the most difficult for both humans and computers. In this paper we show that robustly learning division in a systematic manner remains a challenge even at the simplest level of dividing two numbers. We propose two novel approaches for division which we call the Neural Reciprocal Unit (NRU) and the Neural Multiplicative Reciprocal Unit (NMRU), and present improvements for an existing division module, the Real Neural Power Unit (Real NPU). Experiments in learning division with input redundancy on 225 different training sets, find that our proposed modifications to the Real NPU obtains an average success of 85.3$\%$ improving over the original by 15.1$\%$. In light of the suggestion above, our NMRU approach can further improve the success to 91.6$\%$.
GhostShiftAddNet: More Features from Energy-Efficient Operations
Sep 20, 2021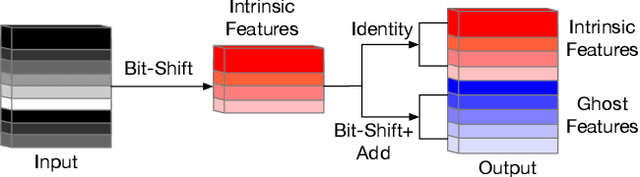
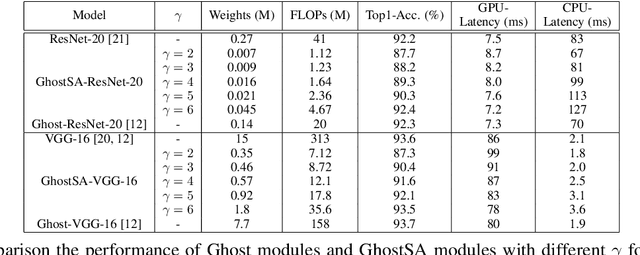
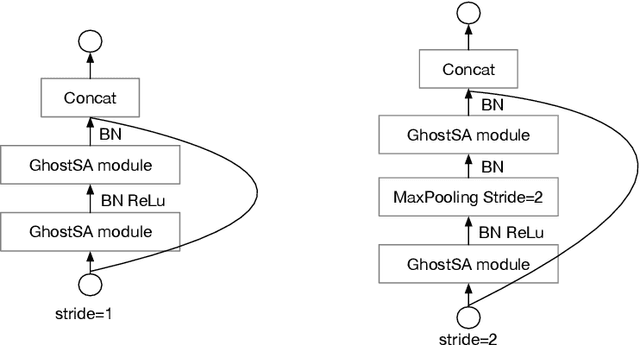
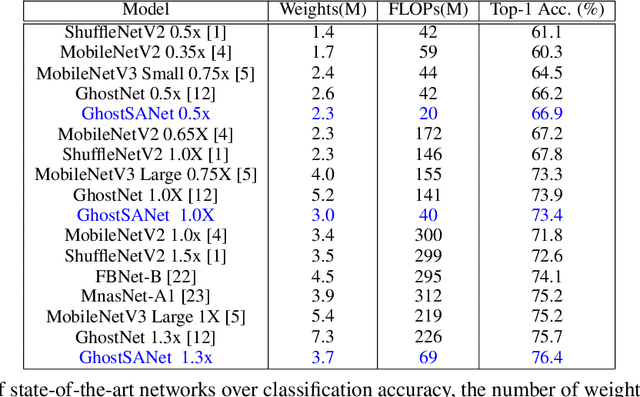
Deep convolutional neural networks (CNNs) are computationally and memory intensive. In CNNs, intensive multiplication can have resource implications that may challenge the ability for effective deployment of inference on resource-constrained edge devices. This paper proposes GhostShiftAddNet, where the motivation is to implement a hardware-efficient deep network: a multiplication-free CNN with fewer redundant features. We introduce a new bottleneck block, GhostSA, that converts all multiplications in the block to cheap operations. The bottleneck uses an appropriate number of bit-shift filters to process intrinsic feature maps, then applies a series of transformations that consist of bit-wise shifts with addition operations to generate more feature maps that fully learn to capture information underlying intrinsic features. We schedule the number of bit-shift and addition operations for different hardware platforms. We conduct extensive experiments and ablation studies with desktop and embedded (Jetson Nano) devices for implementation and measurements. We demonstrate the proposed GhostSA block can replace bottleneck blocks in the backbone of state-of-the-art networks architectures and gives improved performance on image classification benchmarks. Further, our GhostShiftAddNet can achieve higher classification accuracy with fewer FLOPs and parameters (reduced by up to 3x) than GhostNet. When compared to GhostNet, inference latency on the Jetson Nano is improved by 1.3x and 2x on the GPU and CPU respectively.