 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFluid Dynamic DNNs for Reliable and Adaptive Distributed Inference on Edge Devices
Jan 17, 2024

Distributed inference is a popular approach for efficient DNN inference at the edge. However, traditional Static and Dynamic DNNs are not distribution-friendly, causing system reliability and adaptability issues. In this paper, we introduce Fluid Dynamic DNNs (Fluid DyDNNs), tailored for distributed inference. Distinct from Static and Dynamic DNNs, Fluid DyDNNs utilize a novel nested incremental training algorithm to enable independent and combined operation of its sub-networks, enhancing system reliability and adaptability. Evaluation on embedded Arm CPUs with a DNN model and the MNIST dataset, shows that in scenarios of single device failure, Fluid DyDNNs ensure continued inference, whereas Static and Dynamic DNNs fail. When devices are fully operational, Fluid DyDNNs can operate in either a High-Accuracy mode and achieve comparable accuracy with Static DNNs, or in a High-Throughput mode and achieve 2.5x and 2x throughput compared with Static and Dynamic DNNs, respectively.
Dynamic DNNs and Runtime Management for Efficient Inference on Mobile/Embedded Devices
Jan 17, 2024Deep neural network (DNN) inference is increasingly being executed on mobile and embedded platforms due to several key advantages in latency, privacy and always-on availability. However, due to limited computing resources, efficient DNN deployment on mobile and embedded platforms is challenging. Although many hardware accelerators and static model compression methods were proposed by previous works, at system runtime, multiple applications are typically executed concurrently and compete for hardware resources. This raises two main challenges: Runtime Hardware Availability and Runtime Application Variability. Previous works have addressed these challenges through either dynamic neural networks that contain sub-networks with different performance trade-offs or runtime hardware resource management. In this thesis, we proposed a combined method, a system was developed for DNN performance trade-off management, combining the runtime trade-off opportunities in both algorithms and hardware to meet dynamically changing application performance targets and hardware constraints in real time. We co-designed novel Dynamic Super-Networks to maximise runtime system-level performance and energy efficiency on heterogeneous hardware platforms. Compared with SOTA, our experimental results using ImageNet on the GPU of Jetson Xavier NX show our model is 2.4x faster for similar ImageNet Top-1 accuracy, or 5.1% higher accuracy at similar latency. We also designed a hierarchical runtime resource manager that tunes both dynamic neural networks and DVFS at runtime. Compared with the Linux DVFS governor schedutil, our runtime approach achieves up to a 19% energy reduction and a 9% latency reduction in single model deployment scenario, and an 89% energy reduction and a 23% latency reduction in a two concurrent model deployment scenario.
Dynamic Transformer for Efficient Machine Translation on Embedded Devices
Jul 30, 2021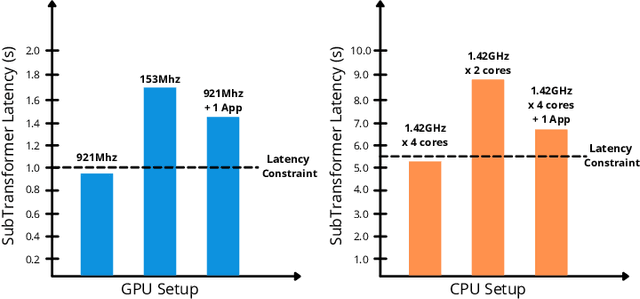
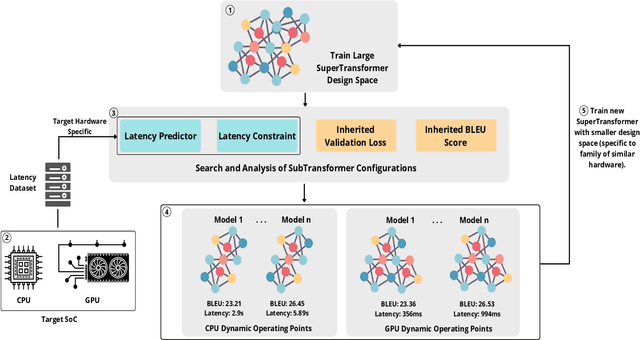
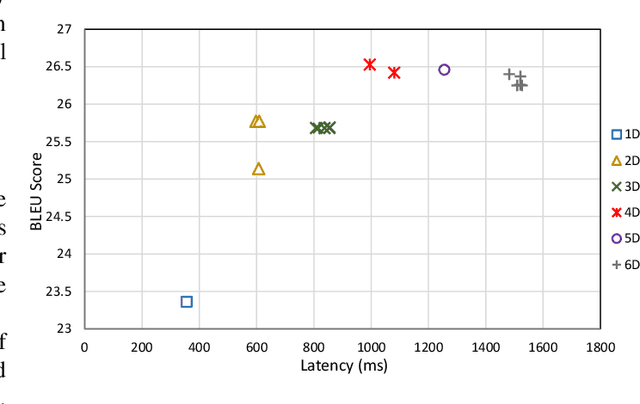
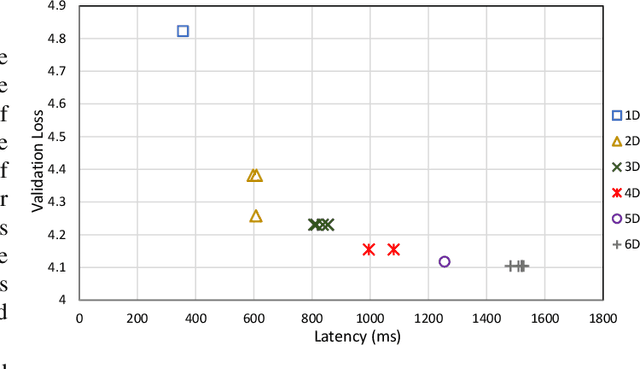
The Transformer architecture is widely used for machine translation tasks. However, its resource-intensive nature makes it challenging to implement on constrained embedded devices, particularly where available hardware resources can vary at run-time. We propose a dynamic machine translation model that scales the Transformer architecture based on the available resources at any particular time. The proposed approach, 'Dynamic-HAT', uses a HAT SuperTransformer as the backbone to search for SubTransformers with different accuracy-latency trade-offs at design time. The optimal SubTransformers are sampled from the SuperTransformer at run-time, depending on latency constraints. The Dynamic-HAT is tested on the Jetson Nano and the approach uses inherited SubTransformers sampled directly from the SuperTransformer with a switching time of <1s. Using inherited SubTransformers results in a BLEU score loss of <1.5% because the SubTransformer configuration is not retrained from scratch after sampling. However, to recover this loss in performance, the dimensions of the design space can be reduced to tailor it to a family of target hardware. The new reduced design space results in a BLEU score increase of approximately 1% for sub-optimal models from the original design space, with a wide range for performance scaling between 0.356s - 1.526s for the GPU and 2.9s - 7.31s for the CPU.
Dynamic-OFA: Runtime DNN Architecture Switching for Performance Scaling on Heterogeneous Embedded Platforms
May 11, 2021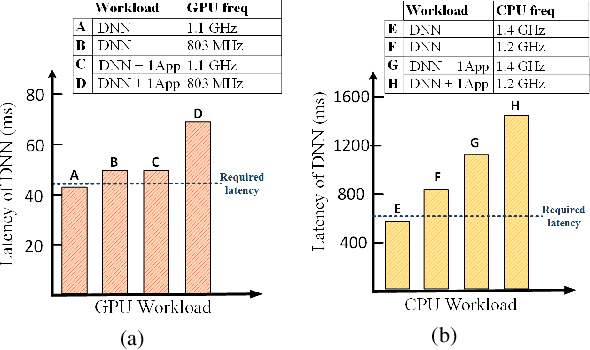

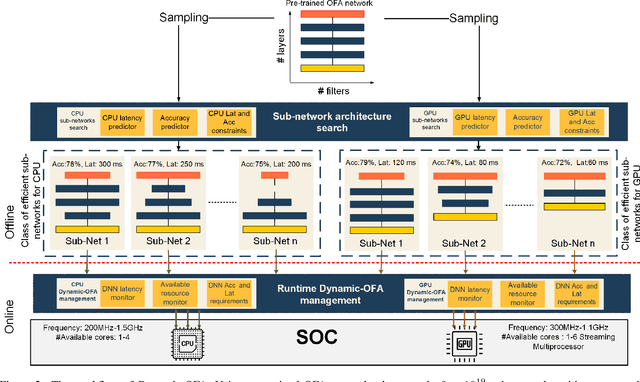
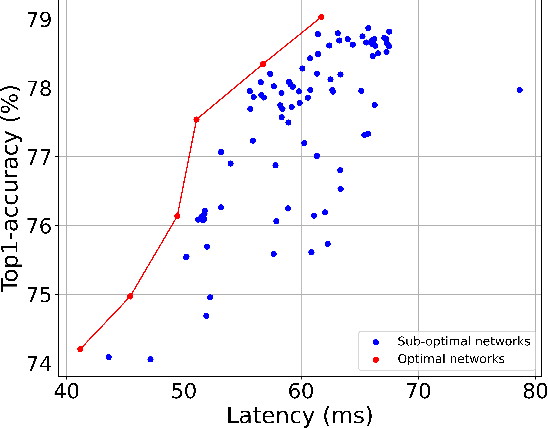
Mobile and embedded platforms are increasingly required to efficiently execute computationally demanding DNNs across heterogeneous processing elements. At runtime, the available hardware resources to DNNs can vary considerably due to other concurrently running applications. The performance requirements of the applications could also change under different scenarios. To achieve the desired performance, dynamic DNNs have been proposed in which the number of channels/layers can be scaled in real time to meet different requirements under varying resource constraints. However, the training process of such dynamic DNNs can be costly, since platform-aware models of different deployment scenarios must be retrained to become dynamic. This paper proposes Dynamic-OFA, a novel dynamic DNN approach for state-of-the-art platform-aware NAS models (i.e. Once-for-all network (OFA)). Dynamic-OFA pre-samples a family of sub-networks from a static OFA backbone model, and contains a runtime manager to choose different sub-networks under different runtime environments. As such, Dynamic-OFA does not need the traditional dynamic DNN training pipeline. Compared to the state-of-the-art, our experimental results using ImageNet on a Jetson Xavier NX show that the approach is up to 3.5x (CPU), 2.4x (GPU) faster for similar ImageNet Top-1 accuracy, or 3.8% (CPU), 5.1% (GPU) higher accuracy at similar latency.
Optimising Resource Management for Embedded Machine Learning
May 08, 2021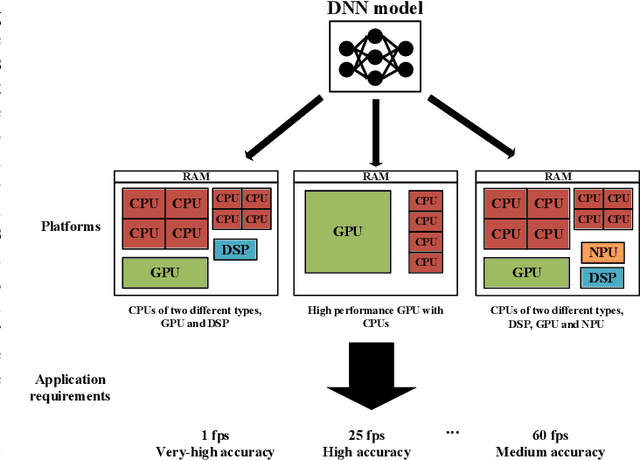
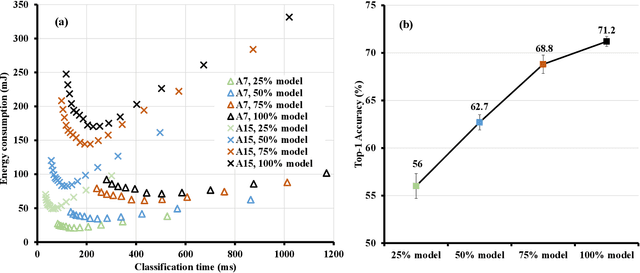
Machine learning inference is increasingly being executed locally on mobile and embedded platforms, due to the clear advantages in latency, privacy and connectivity. In this paper, we present approaches for online resource management in heterogeneous multi-core systems and show how they can be applied to optimise the performance of machine learning workloads. Performance can be defined using platform-dependent (e.g. speed, energy) and platform-independent (accuracy, confidence) metrics. In particular, we show how a Deep Neural Network (DNN) can be dynamically scalable to trade-off these various performance metrics. Achieving consistent performance when executing on different platforms is necessary yet challenging, due to the different resources provided and their capability, and their time-varying availability when executing alongside other workloads. Managing the interface between available hardware resources (often numerous and heterogeneous in nature), software requirements, and user experience is increasingly complex.
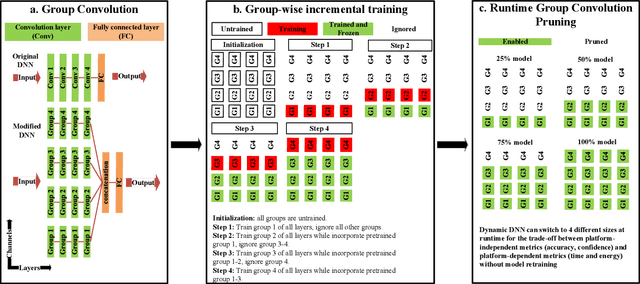
Incremental Training and Group Convolution Pruning for Runtime DNN Performance Scaling on Heterogeneous Embedded Platforms
May 08, 2021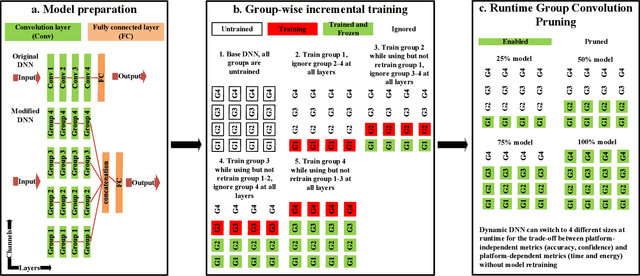
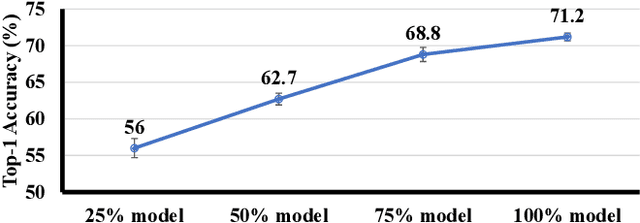
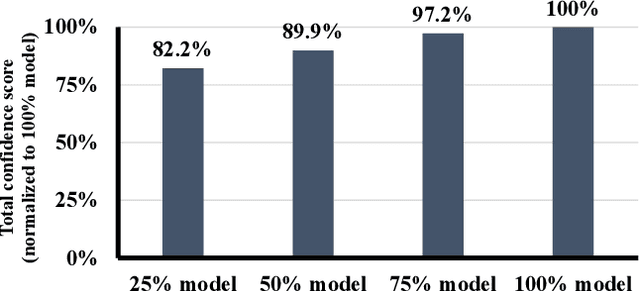
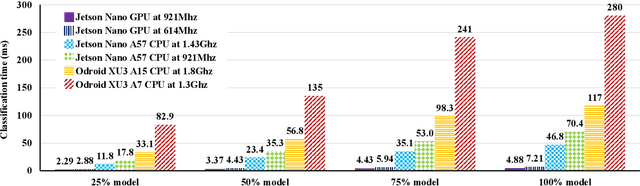
Inference for Deep Neural Networks is increasingly being executed locally on mobile and embedded platforms due to its advantages in latency, privacy and connectivity. Since modern System on Chips typically execute a combination of different and dynamic workloads concurrently, it is challenging to consistently meet inference time/energy budget at runtime because of the local computing resources available to the DNNs vary considerably. To address this challenge, a variety of dynamic DNNs were proposed. However, these works have significant memory overhead, limited runtime recoverable compression rate and narrow dynamic ranges of performance scaling. In this paper, we present a dynamic DNN using incremental training and group convolution pruning. The channels of the DNN convolution layer are divided into groups, which are then trained incrementally. At runtime, following groups can be pruned for inference time/energy reduction or added back for accuracy recovery without model retraining. In addition, we combine task mapping and Dynamic Voltage Frequency Scaling (DVFS) with our dynamic DNN to deliver finer trade-off between accuracy and time/power/energy over a wider dynamic range. We illustrate the approach by modifying AlexNet for the CIFAR10 image dataset and evaluate our work on two heterogeneous hardware platforms: Odroid XU3 (ARM big.LITTLE CPUs) and Nvidia Jetson Nano (CPU and GPU). Compared to the existing works, our approach can provide up to 2.36x (energy) and 2.73x (time) wider dynamic range with a 2.4x smaller memory footprint at the same compression rate. It achieved 10.6x (energy) and 41.6x (time) wider dynamic range by combining with task mapping and DVFS.