 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Transformer for Efficient Machine Translation on Embedded Devices
Paper and Code
Jul 30, 2021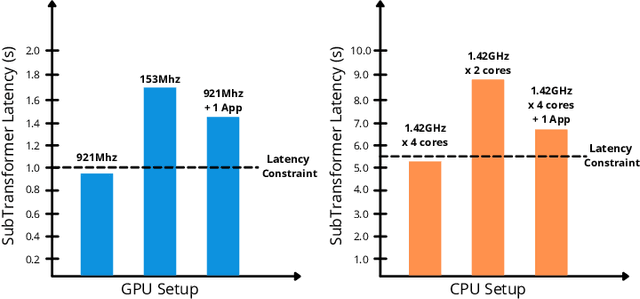
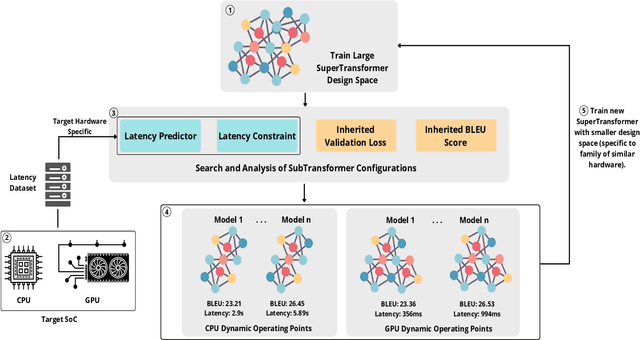
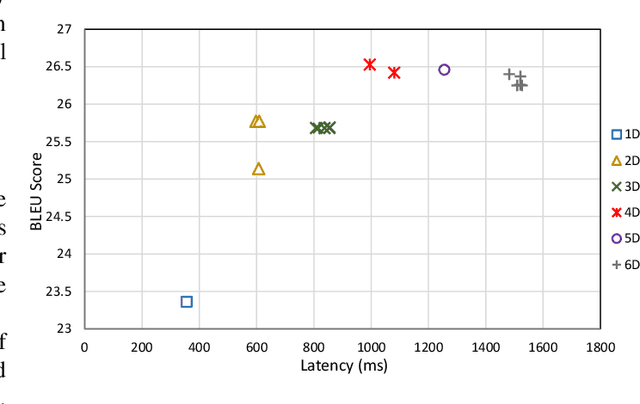
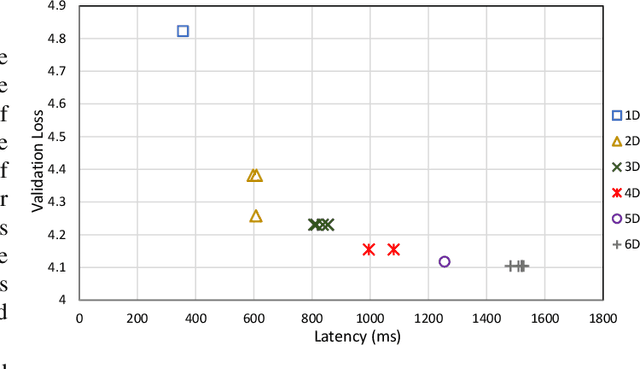
The Transformer architecture is widely used for machine translation tasks. However, its resource-intensive nature makes it challenging to implement on constrained embedded devices, particularly where available hardware resources can vary at run-time. We propose a dynamic machine translation model that scales the Transformer architecture based on the available resources at any particular time. The proposed approach, 'Dynamic-HAT', uses a HAT SuperTransformer as the backbone to search for SubTransformers with different accuracy-latency trade-offs at design time. The optimal SubTransformers are sampled from the SuperTransformer at run-time, depending on latency constraints. The Dynamic-HAT is tested on the Jetson Nano and the approach uses inherited SubTransformers sampled directly from the SuperTransformer with a switching time of <1s. Using inherited SubTransformers results in a BLEU score loss of <1.5% because the SubTransformer configuration is not retrained from scratch after sampling. However, to recover this loss in performance, the dimensions of the design space can be reduced to tailor it to a family of target hardware. The new reduced design space results in a BLEU score increase of approximately 1% for sub-optimal models from the original design space, with a wide range for performance scaling between 0.356s - 1.526s for the GPU and 2.9s - 7.31s for the CPU.