 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolar Irradiance Anticipative Transformer
May 29, 2023



This paper proposes an anticipative transformer-based model for short-term solar irradiance forecasting. Given a sequence of sky images, our proposed vision transformer encodes features of consecutive images, feeding into a transformer decoder to predict irradiance values associated with future unseen sky images. We show that our model effectively learns to attend only to relevant features in images in order to forecast irradiance. Moreover, the proposed anticipative transformer captures long-range dependencies between sky images to achieve a forecasting skill of 21.45 % on a 15 minute ahead prediction for a newly introduced dataset of all-sky images when compared to a smart persistence model.
Dynamic Transformer for Efficient Machine Translation on Embedded Devices
Jul 30, 2021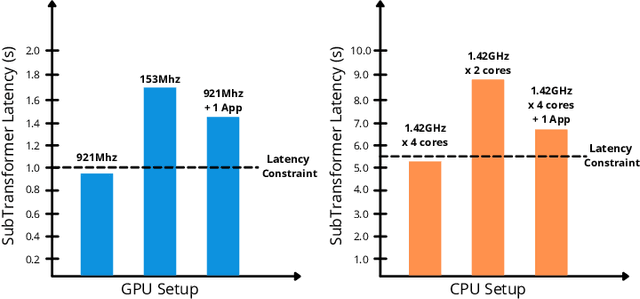
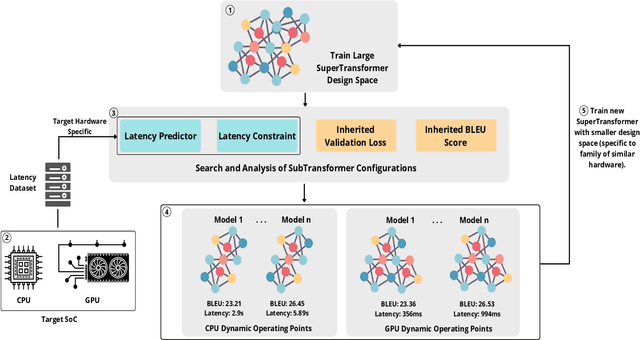
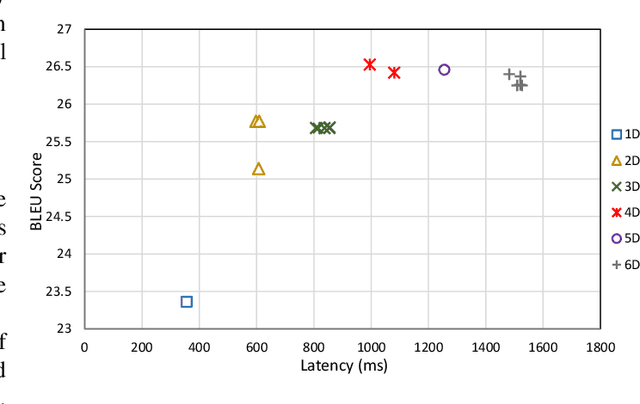
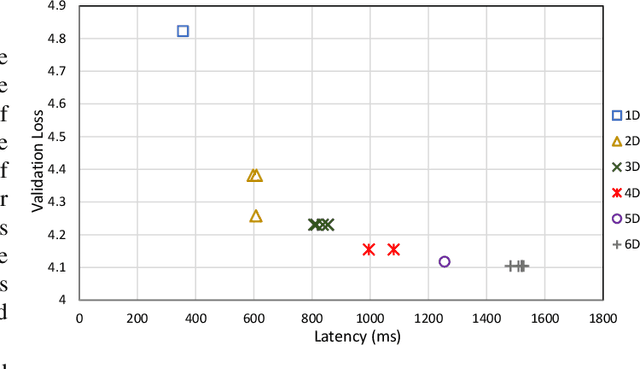
The Transformer architecture is widely used for machine translation tasks. However, its resource-intensive nature makes it challenging to implement on constrained embedded devices, particularly where available hardware resources can vary at run-time. We propose a dynamic machine translation model that scales the Transformer architecture based on the available resources at any particular time. The proposed approach, 'Dynamic-HAT', uses a HAT SuperTransformer as the backbone to search for SubTransformers with different accuracy-latency trade-offs at design time. The optimal SubTransformers are sampled from the SuperTransformer at run-time, depending on latency constraints. The Dynamic-HAT is tested on the Jetson Nano and the approach uses inherited SubTransformers sampled directly from the SuperTransformer with a switching time of <1s. Using inherited SubTransformers results in a BLEU score loss of <1.5% because the SubTransformer configuration is not retrained from scratch after sampling. However, to recover this loss in performance, the dimensions of the design space can be reduced to tailor it to a family of target hardware. The new reduced design space results in a BLEU score increase of approximately 1% for sub-optimal models from the original design space, with a wide range for performance scaling between 0.356s - 1.526s for the GPU and 2.9s - 7.31s for the CPU.
Temporal Early Exits for Efficient Video Object Detection
Jun 21, 2021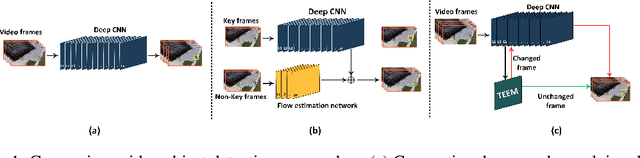
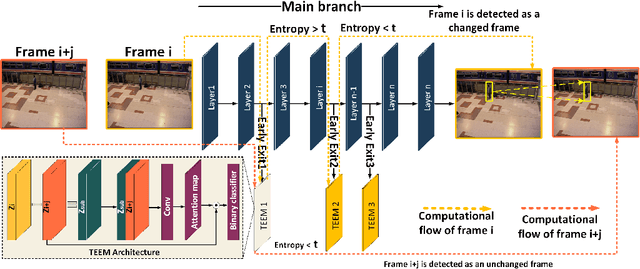
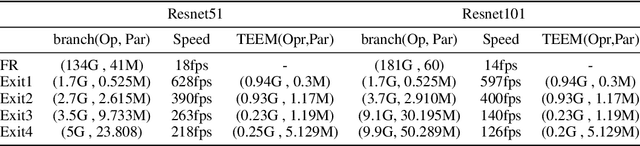

Transferring image-based object detectors to the domain of video remains challenging under resource constraints. Previous efforts utilised optical flow to allow unchanged features to be propagated, however, the overhead is considerable when working with very slowly changing scenes from applications such as surveillance. In this paper, we propose temporal early exits to reduce the computational complexity of per-frame video object detection. Multiple temporal early exit modules with low computational overhead are inserted at early layers of the backbone network to identify the semantic differences between consecutive frames. Full computation is only required if the frame is identified as having a semantic change to previous frames; otherwise, detection results from previous frames are reused. Experiments on CDnet show that our method significantly reduces the computational complexity and execution of per-frame video object detection up to $34 \times$ compared to existing methods with an acceptable reduction of 2.2\% in mAP.
Dynamic-OFA: Runtime DNN Architecture Switching for Performance Scaling on Heterogeneous Embedded Platforms
May 11, 2021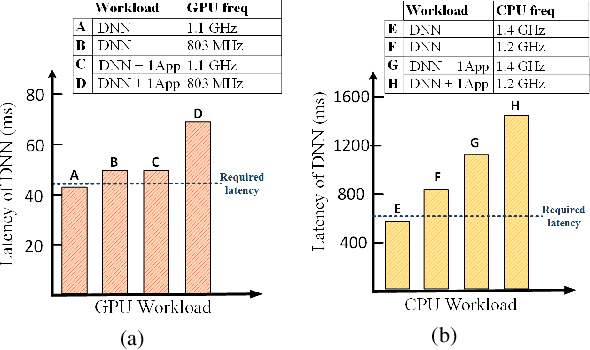

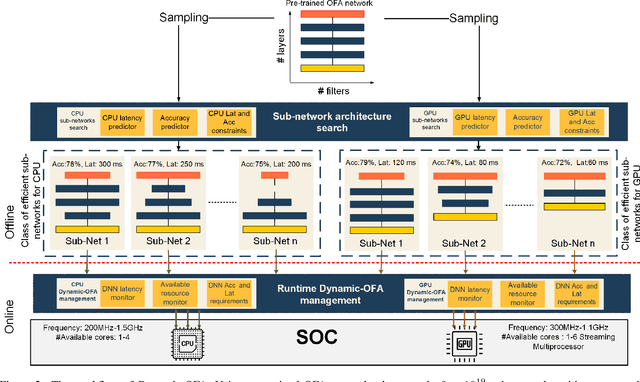
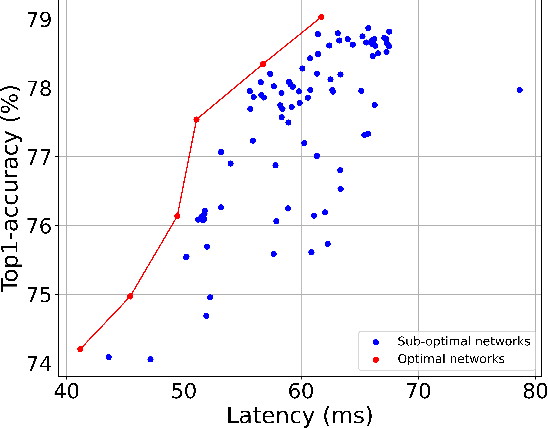
Mobile and embedded platforms are increasingly required to efficiently execute computationally demanding DNNs across heterogeneous processing elements. At runtime, the available hardware resources to DNNs can vary considerably due to other concurrently running applications. The performance requirements of the applications could also change under different scenarios. To achieve the desired performance, dynamic DNNs have been proposed in which the number of channels/layers can be scaled in real time to meet different requirements under varying resource constraints. However, the training process of such dynamic DNNs can be costly, since platform-aware models of different deployment scenarios must be retrained to become dynamic. This paper proposes Dynamic-OFA, a novel dynamic DNN approach for state-of-the-art platform-aware NAS models (i.e. Once-for-all network (OFA)). Dynamic-OFA pre-samples a family of sub-networks from a static OFA backbone model, and contains a runtime manager to choose different sub-networks under different runtime environments. As such, Dynamic-OFA does not need the traditional dynamic DNN training pipeline. Compared to the state-of-the-art, our experimental results using ImageNet on a Jetson Xavier NX show that the approach is up to 3.5x (CPU), 2.4x (GPU) faster for similar ImageNet Top-1 accuracy, or 3.8% (CPU), 5.1% (GPU) higher accuracy at similar latency.