 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFluid Dynamic DNNs for Reliable and Adaptive Distributed Inference on Edge Devices
Jan 17, 2024

Distributed inference is a popular approach for efficient DNN inference at the edge. However, traditional Static and Dynamic DNNs are not distribution-friendly, causing system reliability and adaptability issues. In this paper, we introduce Fluid Dynamic DNNs (Fluid DyDNNs), tailored for distributed inference. Distinct from Static and Dynamic DNNs, Fluid DyDNNs utilize a novel nested incremental training algorithm to enable independent and combined operation of its sub-networks, enhancing system reliability and adaptability. Evaluation on embedded Arm CPUs with a DNN model and the MNIST dataset, shows that in scenarios of single device failure, Fluid DyDNNs ensure continued inference, whereas Static and Dynamic DNNs fail. When devices are fully operational, Fluid DyDNNs can operate in either a High-Accuracy mode and achieve comparable accuracy with Static DNNs, or in a High-Throughput mode and achieve 2.5x and 2x throughput compared with Static and Dynamic DNNs, respectively.
Efficient Integer-Arithmetic-Only Convolutional Neural Networks
Jun 21, 2020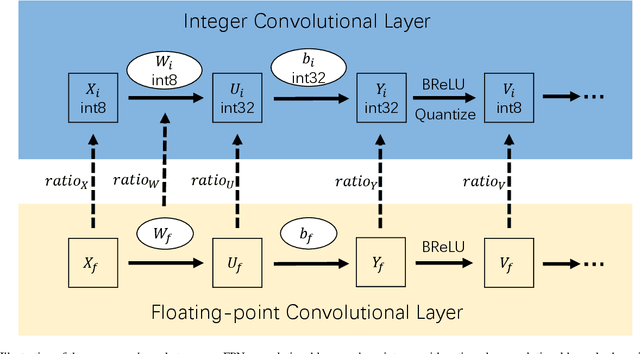
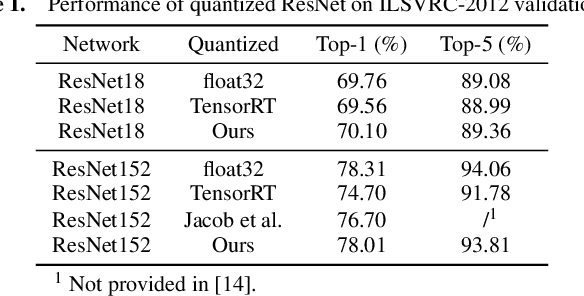
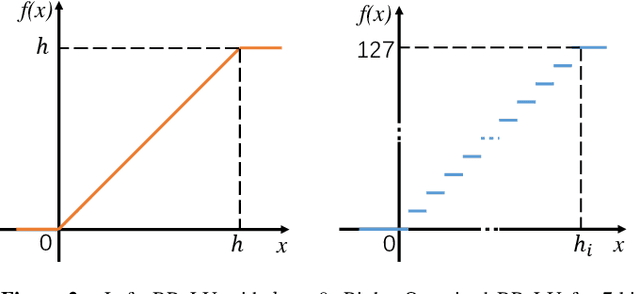
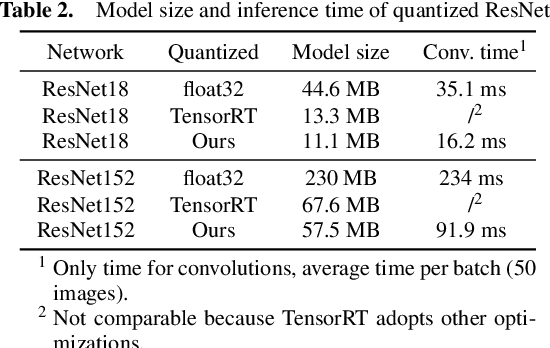
Integer-arithmetic-only networks have been demonstrated effective to reduce computational cost and to ensure cross-platform consistency. However, previous works usually report a decline in the inference accuracy when converting well-trained floating-point-number (FPN) networks into integer networks. We analyze this phonomenon and find that the decline is due to activation quantization. Specifically, when we replace conventional ReLU with Bounded ReLU, how to set the bound for each neuron is a key problem. Considering the tradeoff between activation quantization error and network learning ability, we set an empirical rule to tune the bound of each Bounded ReLU. We also design a mechanism to handle the cases of feature map addition and feature map concatenation. Based on the proposed method, our trained 8-bit integer ResNet outperforms the 8-bit networks of Google's TensorFlow and NVIDIA's TensorRT for image recognition. We also experiment on VDSR for image super-resolution and on VRCNN for compression artifact reduction, both of which serve for regression tasks that natively require high inference accuracy. Our integer networks achieve equivalent performance as the corresponding FPN networks, but have only 1/4 memory cost and run 2x faster on modern GPUs. Our code and models can be found at github.com/HengRuiZ/brelu.