 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning at Initialisation through the lens of Graphon Limit: Convergence, Expressivity, and Generalisation
Feb 06, 2026Pruning at Initialisation methods discover sparse, trainable subnetworks before training, but their theoretical mechanisms remain elusive. Existing analyses are often limited to finite-width statistics, lacking a rigorous characterisation of the global sparsity patterns that emerge as networks grow large. In this work, we connect discrete pruning heuristics to graph limit theory via graphons, establishing the graphon limit of PaI masks. We introduce a Factorised Saliency Model that encompasses popular pruning criteria and prove that, under regularity conditions, the discrete masks generated by these algorithms converge to deterministic bipartite graphons. This limit framework establishes a novel topological taxonomy for sparse networks: while unstructured methods (e.g., Random, Magnitude) converge to homogeneous graphons representing uniform connectivity, data-driven methods (e.g., SNIP, GraSP) converge to heterogeneous graphons that encode implicit feature selection. Leveraging this continuous characterisation, we derive two fundamental theoretical results: (i) a Universal Approximation Theorem for sparse networks that depends only on the intrinsic dimension of active coordinate subspaces; and (ii) a Graphon-NTK generalisation bound demonstrating how the limit graphon modulates the kernel geometry to align with informative features. Our results transform the study of sparse neural networks from combinatorial graph problems into a rigorous framework of continuous operators, offering a new mechanism for analysing expressivity and generalisation in sparse neural networks.
Sparse Offline Reinforcement Learning with Corruption Robustness
Dec 31, 2025We investigate robustness to strong data corruption in offline sparse reinforcement learning (RL). In our setting, an adversary may arbitrarily perturb a fraction of the collected trajectories from a high-dimensional but sparse Markov decision process, and our goal is to estimate a near optimal policy. The main challenge is that, in the high-dimensional regime where the number of samples $N$ is smaller than the feature dimension $d$, exploiting sparsity is essential for obtaining non-vacuous guarantees but has not been systematically studied in offline RL. We analyse the problem under uniform coverage and sparse single-concentrability assumptions. While Least Square Value Iteration (LSVI), a standard approach for robust offline RL, performs well under uniform coverage, we show that integrating sparsity into LSVI is unnatural, and its analysis may break down due to overly pessimistic bonuses. To overcome this, we propose actor-critic methods with sparse robust estimator oracles, which avoid the use of pointwise pessimistic bonuses and provide the first non-vacuous guarantees for sparse offline RL under single-policy concentrability coverage. Moreover, we extend our results to the contaminated setting and show that our algorithm remains robust under strong contamination. Our results provide the first non-vacuous guarantees in high-dimensional sparse MDPs with single-policy concentrability coverage and corruption, showing that learning a near-optimal policy remains possible in regimes where traditional robust offline RL techniques may fail.
Learning in Repeated Multi-Objective Stackelberg Games with Payoff Manipulation
Aug 20, 2025We study payoff manipulation in repeated multi-objective Stackelberg games, where a leader may strategically influence a follower's deterministic best response, e.g., by offering a share of their own payoff. We assume that the follower's utility function, representing preferences over multiple objectives, is unknown but linear, and its weight parameter must be inferred through interaction. This introduces a sequential decision-making challenge for the leader, who must balance preference elicitation with immediate utility maximisation. We formalise this problem and propose manipulation policies based on expected utility (EU) and long-term expected utility (longEU), which guide the leader in selecting actions and offering incentives that trade off short-term gains with long-term impact. We prove that under infinite repeated interactions, longEU converges to the optimal manipulation. Empirical results across benchmark environments demonstrate that our approach improves cumulative leader utility while promoting mutually beneficial outcomes, all without requiring explicit negotiation or prior knowledge of the follower's utility function.
Provably Improving Generalization of Few-Shot Models with Synthetic Data
May 30, 2025Few-shot image classification remains challenging due to the scarcity of labeled training examples. Augmenting them with synthetic data has emerged as a promising way to alleviate this issue, but models trained on synthetic samples often face performance degradation due to the inherent gap between real and synthetic distributions. To address this limitation, we develop a theoretical framework that quantifies the impact of such distribution discrepancies on supervised learning, specifically in the context of image classification. More importantly, our framework suggests practical ways to generate good synthetic samples and to train a predictor with high generalization ability. Building upon this framework, we propose a novel theoretical-based algorithm that integrates prototype learning to optimize both data partitioning and model training, effectively bridging the gap between real few-shot data and synthetic data. Extensive experiments results show that our approach demonstrates superior performance compared to state-of-the-art methods, outperforming them across multiple datasets.
Identifying the Best Arm in the Presence of Global Environment Shifts
Aug 22, 2024This paper formulates a new Best-Arm Identification problem in the non-stationary stochastic bandits setting, where the means of all arms are shifted in the same way due to a global influence of the environment. The aim is to identify the unique best arm across environmental change given a fixed total budget. While this setting can be regarded as a special case of Adversarial Bandits or Corrupted Bandits, we demonstrate that existing solutions tailored to those settings do not fully utilise the nature of this global influence, and thus, do not work well in practice (despite their theoretical guarantees). To overcome this issue, in this paper we develop a novel selection policy that is consistent and robust in dealing with global environmental shifts. We then propose an allocation policy, LinLUCB, which exploits information about global shifts across all arms in each environment. Empirical tests depict a significant improvement in our policies against other existing methods.
Symmetric Linear Bandits with Hidden Symmetry
May 22, 2024High-dimensional linear bandits with low-dimensional structure have received considerable attention in recent studies due to their practical significance. The most common structure in the literature is sparsity. However, it may not be available in practice. Symmetry, where the reward is invariant under certain groups of transformations on the set of arms, is another important inductive bias in the high-dimensional case that covers many standard structures, including sparsity. In this work, we study high-dimensional symmetric linear bandits where the symmetry is hidden from the learner, and the correct symmetry needs to be learned in an online setting. We examine the structure of a collection of hidden symmetry and provide a method based on model selection within the collection of low-dimensional subspaces. Our algorithm achieves a regret bound of $ O(d_0^{1/3} T^{2/3} \log(d))$, where $d$ is the ambient dimension which is potentially very large, and $d_0$ is the dimension of the true low-dimensional subspace such that $d_0 \ll d$. With an extra assumption on well-separated models, we can further improve the regret to $ O(d_0\sqrt{T\log(d)} )$.
Learning the Expected Core of Strictly Convex Stochastic Cooperative Games
Feb 10, 2024Reward allocation, also known as the credit assignment problem, has been an important topic in economics, engineering, and machine learning. An important concept in credit assignment is the core, which is the set of stable allocations where no agent has the motivation to deviate from the grand coalition. In this paper, we consider the stable allocation learning problem of stochastic cooperative games, where the reward function is characterised as a random variable with an unknown distribution. Given an oracle that returns a stochastic reward for an enquired coalition each round, our goal is to learn the expected core, that is, the set of allocations that are stable in expectation. Within the class of strictly convex games, we present an algorithm named \texttt{Common-Points-Picking} that returns a stable allocation given a polynomial number of samples, with high probability. The analysis of our algorithm involves the development of several new results in convex geometry, including an extension of the separation hyperplane theorem for multiple convex sets, and may be of independent interest.
Revisiting LARS for Large Batch Training Generalization of Neural Networks
Sep 25, 2023



LARS and LAMB have emerged as prominent techniques in Large Batch Learning (LBL), ensuring the stability of AI training. One of the primary challenges in LBL is convergence stability, where the AI agent usually gets trapped into the sharp minimizer. Addressing this challenge, a relatively recent technique, known as warm-up, has been employed. However, warm-up lacks a strong theoretical foundation, leaving the door open for further exploration of more efficacious algorithms. In light of this situation, we conduct empirical experiments to analyze the behaviors of the two most popular optimizers in the LARS family: LARS and LAMB, with and without a warm-up strategy. Our analyses give us a comprehension of the novel LARS, LAMB, and the necessity of a warm-up technique in LBL. Building upon these insights, we propose a novel algorithm called Time Varying LARS (TVLARS), which facilitates robust training in the initial phase without the need for warm-up. Experimental evaluation demonstrates that TVLARS achieves competitive results with LARS and LAMB when warm-up is utilized while surpassing their performance without the warm-up technique.
Examining the Effects of Degree Distribution and Homophily in Graph Learning Models
Jul 17, 2023Despite a surge in interest in GNN development, homogeneity in benchmarking datasets still presents a fundamental issue to GNN research. GraphWorld is a recent solution which uses the Stochastic Block Model (SBM) to generate diverse populations of synthetic graphs for benchmarking any GNN task. Despite its success, the SBM imposed fundamental limitations on the kinds of graph structure GraphWorld could create. In this work we examine how two additional synthetic graph generators can improve GraphWorld's evaluation; LFR, a well-established model in the graph clustering literature and CABAM, a recent adaptation of the Barabasi-Albert model tailored for GNN benchmarking. By integrating these generators, we significantly expand the coverage of graph space within the GraphWorld framework while preserving key graph properties observed in real-world networks. To demonstrate their effectiveness, we generate 300,000 graphs to benchmark 11 GNN models on a node classification task. We find GNN performance variations in response to homophily, degree distribution and feature signal. Based on these findings, we classify models by their sensitivity to the new generators under these properties. Additionally, we release the extensions made to GraphWorld on the GitHub repository, offering further evaluation of GNN performance on new graphs.
Predicting COVID-19 pandemic by spatio-temporal graph neural networks: A New Zealand's study
May 12, 2023
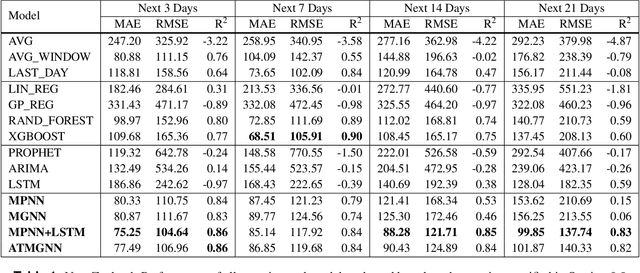
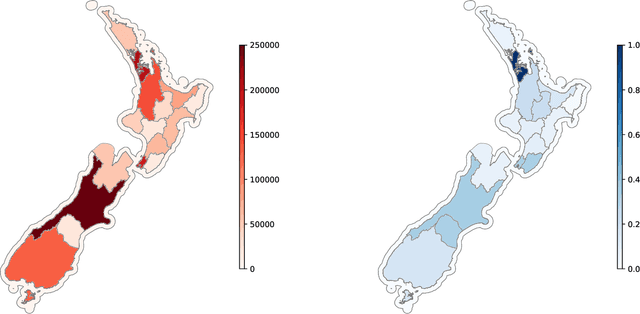
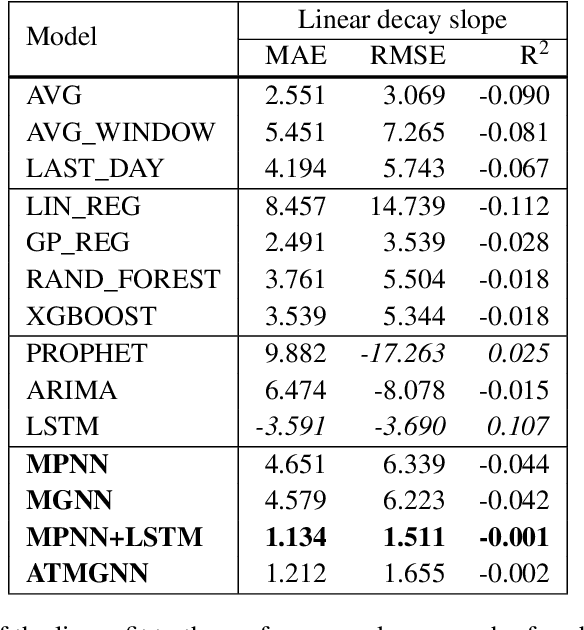
Modeling and simulations of pandemic dynamics play an essential role in understanding and addressing the spreading of highly infectious diseases such as COVID-19. In this work, we propose a novel deep learning architecture named Attention-based Multiresolution Graph Neural Networks (ATMGNN) that learns to combine the spatial graph information, i.e. geographical data, with the temporal information, i.e. timeseries data of number of COVID-19 cases, to predict the future dynamics of the pandemic. The key innovation is that our method can capture the multiscale structures of the spatial graph via a learning to cluster algorithm in a data-driven manner. This allows our architecture to learn to pick up either local or global signals of a pandemic, and model both the long-range spatial and temporal dependencies. Importantly, we collected and assembled a new dataset for New Zealand. We established a comprehensive benchmark of statistical methods, temporal architectures, graph neural networks along with our spatio-temporal model. We also incorporated socioeconomic cross-sectional data to further enhance our prediction. Our proposed model have shown highly robust predictions and outperformed all other baselines in various metrics for our new dataset of New Zealand along with existing datasets of England, France, Italy and Spain. For a future work, we plan to extend our work for real-time prediction and global scale. Our data and source code are publicly available at https://github.com/HySonLab/pandemic_tgnn