 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCountering adversarial evasion in regression analysis
Sep 26, 2025Adversarial machine learning challenges the assumption that the underlying distribution remains consistent throughout the training and implementation of a prediction model. In particular, adversarial evasion considers scenarios where adversaries adapt their data to influence particular outcomes from established prediction models, such scenarios arise in applications such as spam email filtering, malware detection and fake-image generation, where security methods must be actively updated to keep up with the ever-improving generation of malicious data. Game theoretic models have been shown to be effective at modelling these scenarios and hence training resilient predictors against such adversaries. Recent advancements in the use of pessimistic bilevel optimsiation which remove assumptions about the convexity and uniqueness of the adversary's optimal strategy have proved to be particularly effective at mitigating threats to classifiers due to its ability to capture the antagonistic nature of the adversary. However, this formulation has not yet been adapted to regression scenarios. This article serves to propose a pessimistic bilevel optimisation program for regression scenarios which makes no assumptions on the convexity or uniqueness of the adversary's solutions.
Classification under strategic adversary manipulation using pessimistic bilevel optimisation
Oct 26, 2024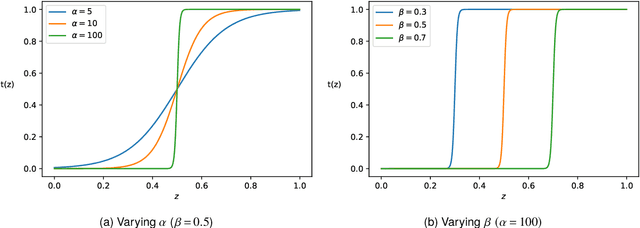

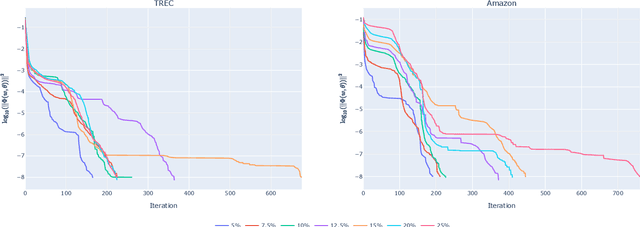
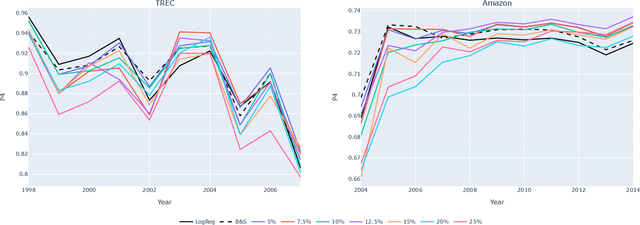
Adversarial machine learning concerns situations in which learners face attacks from active adversaries. Such scenarios arise in applications such as spam email filtering, malware detection and fake-image generation, where security methods must be actively updated to keep up with the ever improving generation of malicious data.We model these interactions between the learner and the adversary as a game and formulate the problem as a pessimistic bilevel optimisation problem with the learner taking the role of the leader. The adversary, modelled as a stochastic data generator, takes the role of the follower, generating data in response to the classifier. While existing models rely on the assumption that the adversary will choose the least costly solution leading to a convex lower-level problem with a unique solution, we present a novel model and solution method which do not make such assumptions. We compare these to the existing approach and see significant improvements in performance suggesting that relaxing these assumptions leads to a more realistic model.
AIIPot: Adaptive Intelligent-Interaction Honeypot for IoT Devices
Mar 22, 2023



The proliferation of the Internet of Things (IoT) has raised concerns about the security of connected devices. There is a need to develop suitable and cost-efficient methods to identify vulnerabilities in IoT devices in order to address them before attackers seize opportunities to compromise them. The deception technique is a prominent approach to improving the security posture of IoT systems. Honeypot is a popular deception technique that mimics interaction in real fashion and encourages unauthorised users (attackers) to launch attacks. Due to the large number and the heterogeneity of IoT devices, manually crafting the low and high-interaction honeypots is not affordable. This has forced researchers to seek innovative ways to build honeypots for IoT devices. In this paper, we propose a honeypot for IoT devices that uses machine learning techniques to learn and interact with attackers automatically. The evaluation of the proposed model indicates that our system can improve the session length with attackers and capture more attacks on the IoT network.
Achieving Better Regret against Strategic Adversaries
Feb 13, 2023



We study online learning problems in which the learner has extra knowledge about the adversary's behaviour, i.e., in game-theoretic settings where opponents typically follow some no-external regret learning algorithms. Under this assumption, we propose two new online learning algorithms, Accurate Follow the Regularized Leader (AFTRL) and Prod-Best Response (Prod-BR), that intensively exploit this extra knowledge while maintaining the no-regret property in the worst-case scenario of having inaccurate extra information. Specifically, AFTRL achieves $O(1)$ external regret or $O(1)$ \emph{forward regret} against no-external regret adversary in comparison with $O(\sqrt{T})$ \emph{dynamic regret} of Prod-BR. To the best of our knowledge, our algorithm is the first to consider forward regret that achieves $O(1)$ regret against strategic adversaries. When playing zero-sum games with Accurate Multiplicative Weights Update (AMWU), a special case of AFTRL, we achieve \emph{last round convergence} to the Nash Equilibrium. We also provide numerical experiments to further support our theoretical results. In particular, we demonstrate that our methods achieve significantly better regret bounds and rate of last round convergence, compared to the state of the art (e.g., Multiplicative Weights Update (MWU) and its optimistic counterpart, OMWU).