 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Layer-Wise Personalized Federated Learning: Adaptive Layer Disentanglement via Conflicting Gradients
Oct 03, 2024



In personalized Federated Learning (pFL), high data heterogeneity can cause significant gradient divergence across devices, adversely affecting the learning process. This divergence, especially when gradients from different users form an obtuse angle during aggregation, can negate progress, leading to severe weight and gradient update degradation. To address this issue, we introduce a new approach to pFL design, namely Federated Learning with Layer-wise Aggregation via Gradient Analysis (FedLAG), utilizing the concept of gradient conflict at the layer level. Specifically, when layer-wise gradients of different clients form acute angles, those gradients align in the same direction, enabling updates across different clients toward identifying client-invariant features. Conversely, when layer-wise gradient pairs make create obtuse angles, the layers tend to focus on client-specific tasks. In hindsights, FedLAG assigns layers for personalization based on the extent of layer-wise gradient conflicts. Specifically, layers with gradient conflicts are excluded from the global aggregation process. The theoretical evaluation demonstrates that when integrated into other pFL baselines, FedLAG enhances pFL performance by a certain margin. Therefore, our proposed method achieves superior convergence behavior compared with other baselines. Extensive experiments show that our FedLAG outperforms several state-of-the-art methods and can be easily incorporated with many existing methods to further enhance performance.
How Homogenizing the Channel-wise Magnitude Can Enhance EEG Classification Model?
Jul 19, 2024A significant challenge in the electroencephalogram EEG lies in the fact that current data representations involve multiple electrode signals, resulting in data redundancy and dominant lead information. However extensive research conducted on EEG classification focuses on designing model architectures without tackling the underlying issues. Otherwise, there has been a notable gap in addressing data preprocessing for EEG, leading to considerable computational overhead in Deep Learning (DL) processes. In light of these issues, we propose a simple yet effective approach for EEG data pre-processing. Our method first transforms the EEG data into an encoded image by an Inverted Channel-wise Magnitude Homogenization (ICWMH) to mitigate inter-channel biases. Next, we apply the edge detection technique on the EEG-encoded image combined with skip connection to emphasize the most significant transitions in the data while preserving structural and invariant information. By doing so, we can improve the EEG learning process efficiently without using a huge DL network. Our experimental evaluations reveal that we can significantly improve (i.e., from 2% to 5%) over current baselines.
Revisiting the Disequilibrium Issues in Tackling Heart Disease Classification Tasks
Jul 19, 2024



In the field of heart disease classification, two primary obstacles arise. Firstly, existing Electrocardiogram (ECG) datasets consistently demonstrate imbalances and biases across various modalities. Secondly, these time-series data consist of diverse lead signals, causing Convolutional Neural Networks (CNNs) to become overfitting to the one with higher power, hence diminishing the performance of the Deep Learning (DL) process. In addition, when facing an imbalanced dataset, performance from such high-dimensional data may be susceptible to overfitting. Current efforts predominantly focus on enhancing DL models by designing novel architectures, despite these evident challenges, seemingly overlooking the core issues, therefore hindering advancements in heart disease classification. To address these obstacles, our proposed approach introduces two straightforward and direct methods to enhance the classification tasks. To address the high dimensionality issue, we employ a Channel-wise Magnitude Equalizer (CME) on signal-encoded images. This approach reduces redundancy in the feature data range, highlighting changes in the dataset. Simultaneously, to counteract data imbalance, we propose the Inverted Weight Logarithmic Loss (IWL) to alleviate imbalances among the data. When applying IWL loss, the accuracy of state-of-the-art models (SOTA) increases up to 5% in the CPSC2018 dataset. CME in combination with IWL also surpasses the classification results of other baseline models from 5% to 10%.
PAT: Pixel-wise Adaptive Training for Long-tailed Segmentation
Apr 09, 2024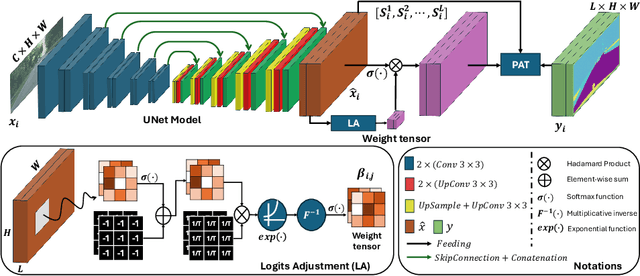
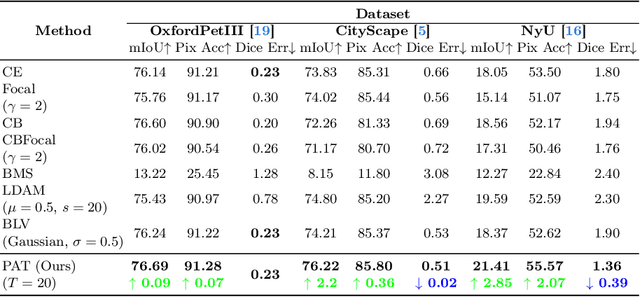
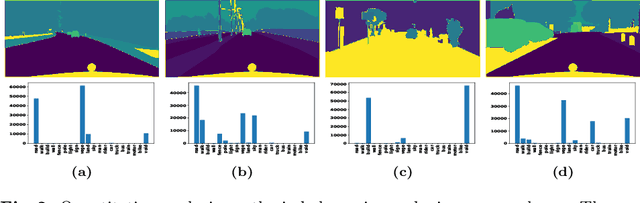
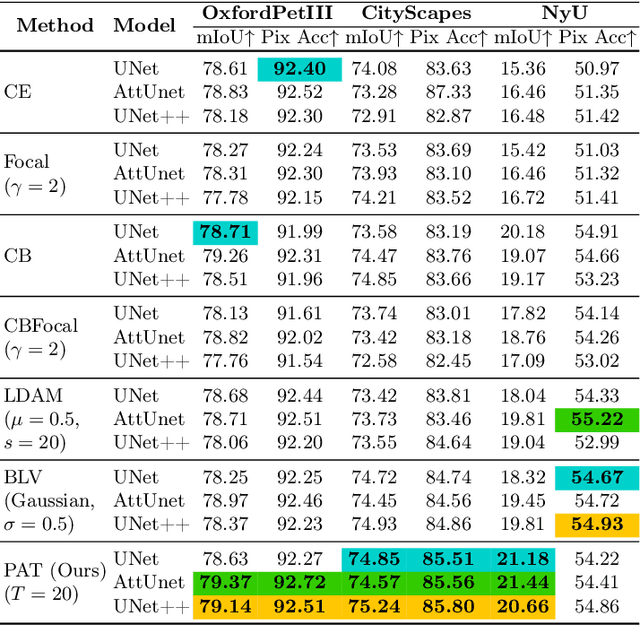
Beyond class frequency, we recognize the impact of class-wise relationships among various class-specific predictions and the imbalance in label masks on long-tailed segmentation learning. To address these challenges, we propose an innovative Pixel-wise Adaptive Training (PAT) technique tailored for long-tailed segmentation. PAT has two key features: 1) class-wise gradient magnitude homogenization, and 2) pixel-wise class-specific loss adaptation (PCLA). First, the class-wise gradient magnitude homogenization helps alleviate the imbalance among label masks by ensuring equal consideration of the class-wise impact on model updates. Second, PCLA tackles the detrimental impact of both rare classes within the long-tailed distribution and inaccurate predictions from previous training stages by encouraging learning classes with low prediction confidence and guarding against forgetting classes with high confidence. This combined approach fosters robust learning while preventing the model from forgetting previously learned knowledge. PAT exhibits significant performance improvements, surpassing the current state-of-the-art by 2.2% in the NyU dataset. Moreover, it enhances overall pixel-wise accuracy by 2.85% and intersection over union value by 2.07%, with a particularly notable declination of 0.39% in detecting rare classes compared to Balance Logits Variation, as demonstrated on the three popular datasets, i.e., OxfordPetIII, CityScape, and NYU.
Revisiting LARS for Large Batch Training Generalization of Neural Networks
Sep 25, 2023



LARS and LAMB have emerged as prominent techniques in Large Batch Learning (LBL), ensuring the stability of AI training. One of the primary challenges in LBL is convergence stability, where the AI agent usually gets trapped into the sharp minimizer. Addressing this challenge, a relatively recent technique, known as warm-up, has been employed. However, warm-up lacks a strong theoretical foundation, leaving the door open for further exploration of more efficacious algorithms. In light of this situation, we conduct empirical experiments to analyze the behaviors of the two most popular optimizers in the LARS family: LARS and LAMB, with and without a warm-up strategy. Our analyses give us a comprehension of the novel LARS, LAMB, and the necessity of a warm-up technique in LBL. Building upon these insights, we propose a novel algorithm called Time Varying LARS (TVLARS), which facilitates robust training in the initial phase without the need for warm-up. Experimental evaluation demonstrates that TVLARS achieves competitive results with LARS and LAMB when warm-up is utilized while surpassing their performance without the warm-up technique.