 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs there really a Citation Age Bias in NLP?
Jan 07, 2024Citations are a key ingredient of scientific research to relate a paper to others published in the community. Recently, it has been noted that there is a citation age bias in the Natural Language Processing (NLP) community, one of the currently fastest growing AI subfields, in that the mean age of the bibliography of NLP papers has become ever younger in the last few years, leading to `citation amnesia' in which older knowledge is increasingly forgotten. In this work, we put such claims into perspective by analyzing the bibliography of $\sim$300k papers across 15 different scientific fields submitted to the popular preprint server Arxiv in the time period from 2013 to 2022. We find that all AI subfields (in particular: cs.AI, cs.CL, cs.CV, cs.LG) have similar trends of citation amnesia, in which the age of the bibliography has roughly halved in the last 10 years (from above 12 in 2013 to below 7 in 2022), on average. Rather than diagnosing this as a citation age bias in the NLP community, we believe this pattern is an artefact of the dynamics of these research fields, in which new knowledge is produced in ever shorter time intervals.
Revisiting LARS for Large Batch Training Generalization of Neural Networks
Sep 25, 2023



LARS and LAMB have emerged as prominent techniques in Large Batch Learning (LBL), ensuring the stability of AI training. One of the primary challenges in LBL is convergence stability, where the AI agent usually gets trapped into the sharp minimizer. Addressing this challenge, a relatively recent technique, known as warm-up, has been employed. However, warm-up lacks a strong theoretical foundation, leaving the door open for further exploration of more efficacious algorithms. In light of this situation, we conduct empirical experiments to analyze the behaviors of the two most popular optimizers in the LARS family: LARS and LAMB, with and without a warm-up strategy. Our analyses give us a comprehension of the novel LARS, LAMB, and the necessity of a warm-up technique in LBL. Building upon these insights, we propose a novel algorithm called Time Varying LARS (TVLARS), which facilitates robust training in the initial phase without the need for warm-up. Experimental evaluation demonstrates that TVLARS achieves competitive results with LARS and LAMB when warm-up is utilized while surpassing their performance without the warm-up technique.
BMX: Boosting Machine Translation Metrics with Explainability
Dec 20, 2022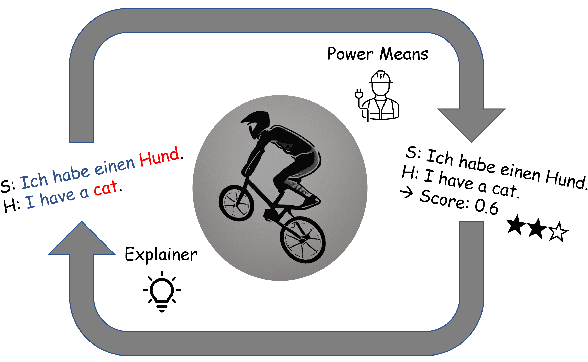

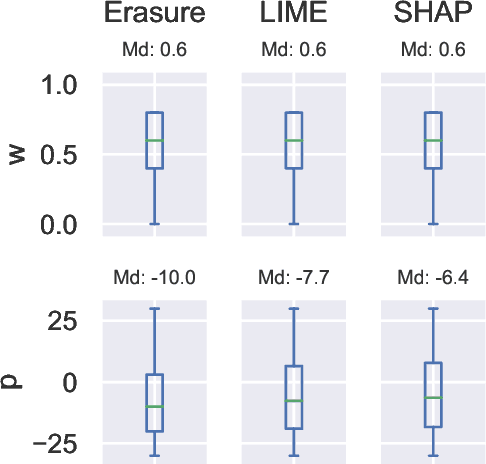
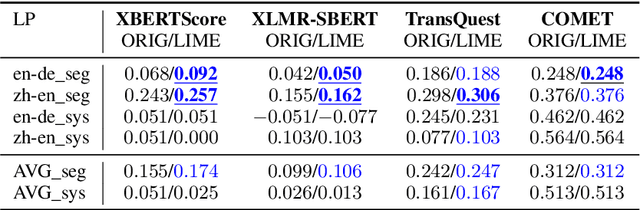
State-of-the-art machine translation evaluation metrics are based on black-box language models. Hence, recent works consider their explainability with the goals of better understandability for humans and better metric analysis, including failure cases. In contrast, we explicitly leverage explanations to boost the metrics' performance. In particular, we perceive explanations as word-level scores, which we convert, via power means, into sentence-level scores. We combine this sentence-level score with the original metric to obtain a better metric. Our extensive evaluation and analysis across 5 datasets, 5 metrics and 4 explainability techniques shows that some configurations reliably improve the original metrics' correlation with human judgment. On two held datasets for testing, we obtain improvements in 15/18 resp. 4/4 cases. The gains in Pearson correlation are up to 0.032 resp. 0.055. We make our code available.
Hydra: Hybrid Server Power Model
Jul 20, 2022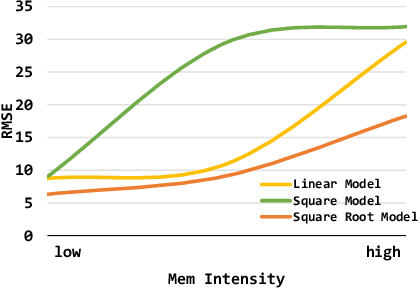
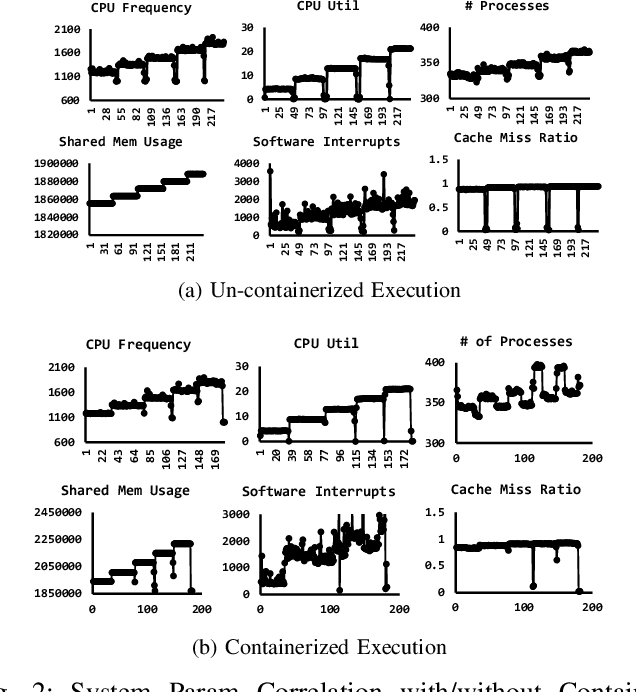
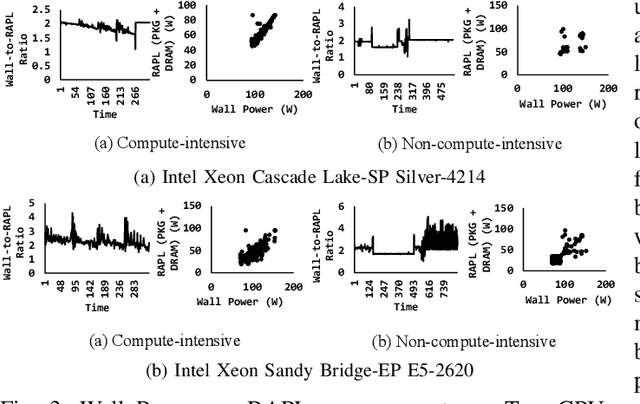
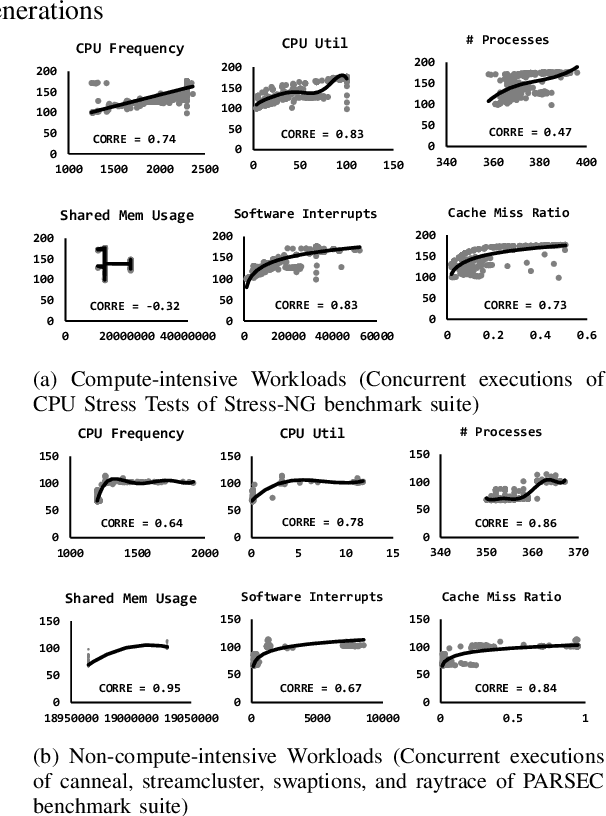
With the growing complexity of big data workloads that require abundant data and computation, data centers consume a tremendous amount of power daily. In an effort to minimize data center power consumption, several studies developed power models that can be used for job scheduling either reducing the number of active servers or balancing workloads across servers at their peak energy efficiency points. Due to increasing software and hardware heterogeneity, we observed that there is no single power model that works the best for all server conditions. Some complicated machine learning models themselves incur performance and power overheads and hence it is not desirable to use them frequently. There are no power models that consider containerized workload execution. In this paper, we propose a hybrid server power model, Hydra, that considers both prediction accuracy and performance overhead. Hydra dynamically chooses the best power model for the given server conditions. Compared with state-of-the-art solutions, Hydra outperforms across all compute-intensity levels on heterogeneous servers.
Block Model Guided Unsupervised Feature Selection
Jul 05, 2020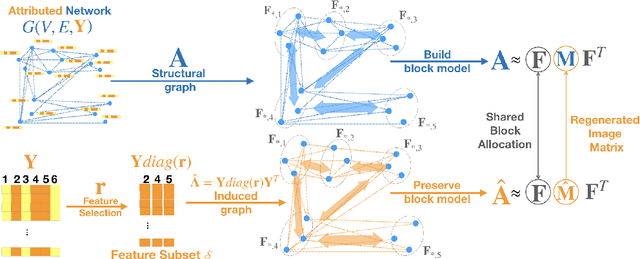
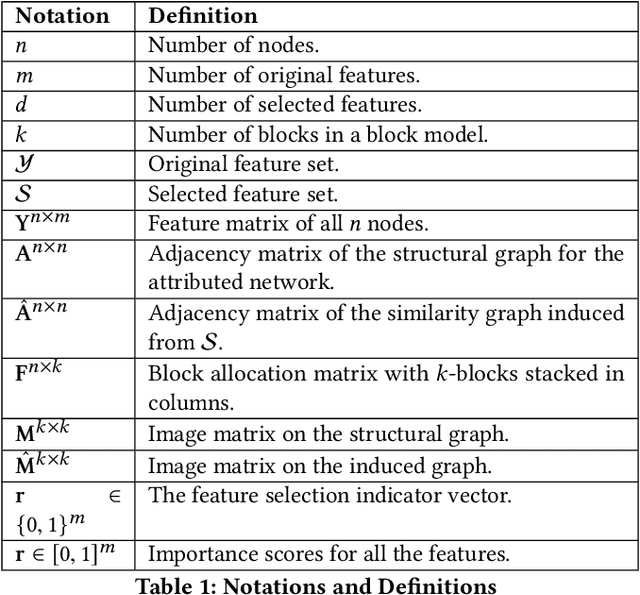
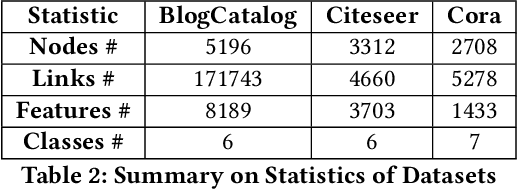

Feature selection is a core area of data mining with a recent innovation of graph-driven unsupervised feature selection for linked data. In this setting we have a dataset $\mathbf{Y}$ consisting of $n$ instances each with $m$ features and a corresponding $n$ node graph (whose adjacency matrix is $\mathbf{A}$) with an edge indicating that the two instances are similar. Existing efforts for unsupervised feature selection on attributed networks have explored either directly regenerating the links by solving for $f$ such that $f(\mathbf{y}_i,\mathbf{y}_j) \approx \mathbf{A}_{i,j}$ or finding community structure in $\mathbf{A}$ and using the features in $\mathbf{Y}$ to predict these communities. However, graph-driven unsupervised feature selection remains an understudied area with respect to exploring more complex guidance. Here we take the novel approach of first building a block model on the graph and then using the block model for feature selection. That is, we discover $\mathbf{F}\mathbf{M}\mathbf{F}^T \approx \mathbf{A}$ and then find a subset of features $\mathcal{S}$ that induces another graph to preserve both $\mathbf{F}$ and $\mathbf{M}$. We call our approach Block Model Guided Unsupervised Feature Selection (BMGUFS). Experimental results show that our method outperforms the state of the art on several real-world public datasets in finding high-quality features for clustering.
* Published at KDD2020