 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBMX: Boosting Machine Translation Metrics with Explainability
Paper and Code
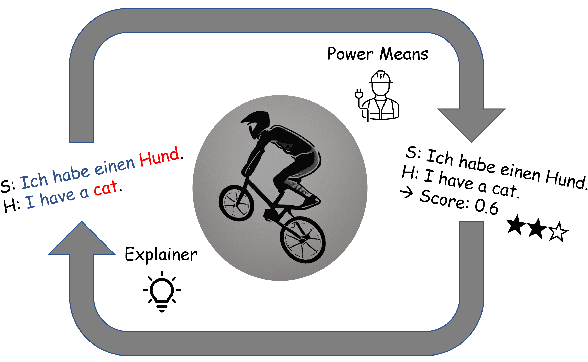

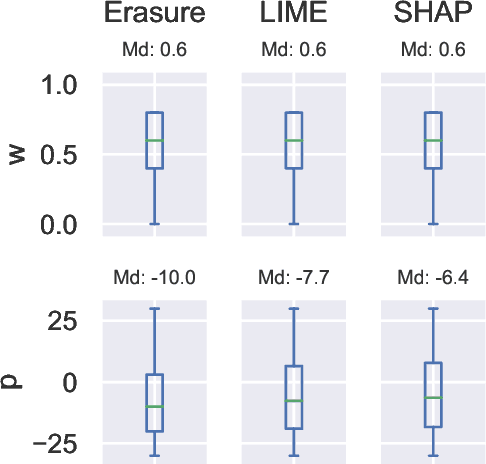
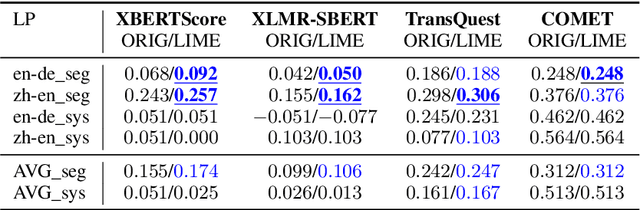
State-of-the-art machine translation evaluation metrics are based on black-box language models. Hence, recent works consider their explainability with the goals of better understandability for humans and better metric analysis, including failure cases. In contrast, we explicitly leverage explanations to boost the metrics' performance. In particular, we perceive explanations as word-level scores, which we convert, via power means, into sentence-level scores. We combine this sentence-level score with the original metric to obtain a better metric. Our extensive evaluation and analysis across 5 datasets, 5 metrics and 4 explainability techniques shows that some configurations reliably improve the original metrics' correlation with human judgment. On two held datasets for testing, we obtain improvements in 15/18 resp. 4/4 cases. The gains in Pearson correlation are up to 0.032 resp. 0.055. We make our code available.