 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHydra: Hybrid Server Power Model
Jul 20, 2022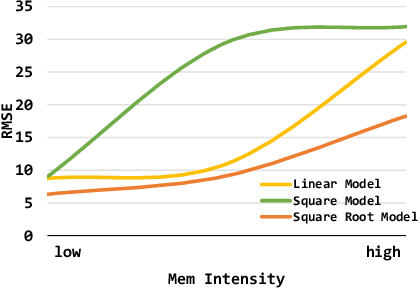
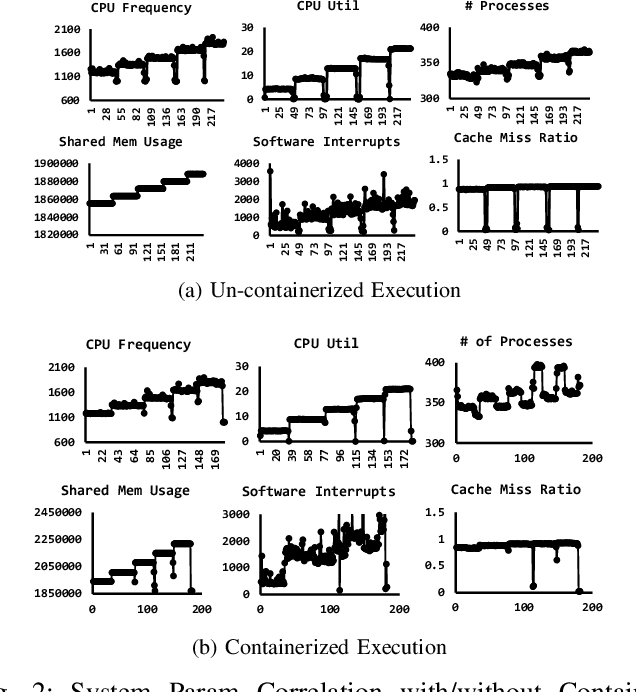
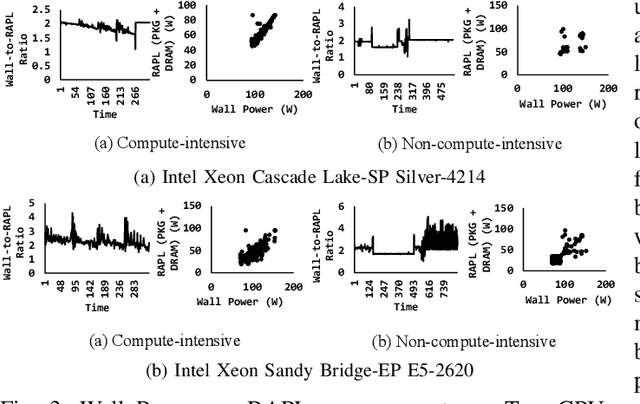
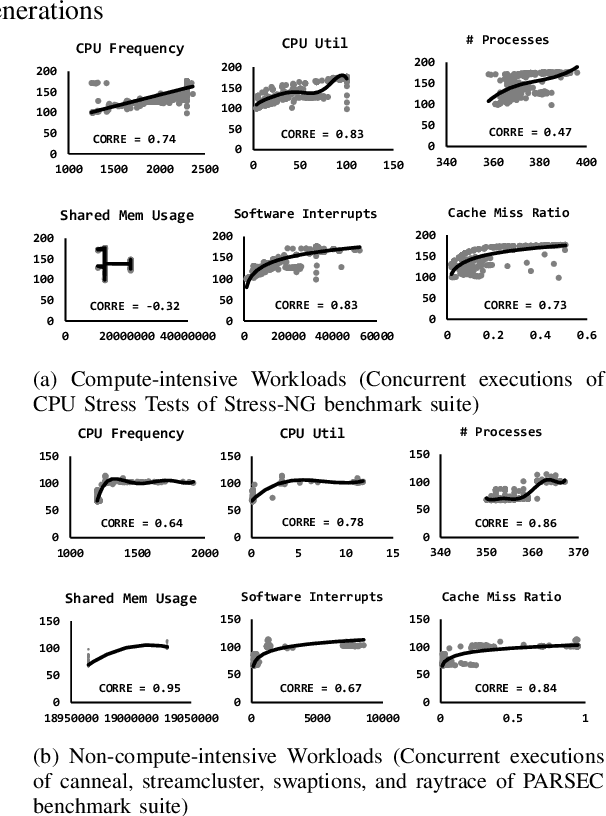
With the growing complexity of big data workloads that require abundant data and computation, data centers consume a tremendous amount of power daily. In an effort to minimize data center power consumption, several studies developed power models that can be used for job scheduling either reducing the number of active servers or balancing workloads across servers at their peak energy efficiency points. Due to increasing software and hardware heterogeneity, we observed that there is no single power model that works the best for all server conditions. Some complicated machine learning models themselves incur performance and power overheads and hence it is not desirable to use them frequently. There are no power models that consider containerized workload execution. In this paper, we propose a hybrid server power model, Hydra, that considers both prediction accuracy and performance overhead. Hydra dynamically chooses the best power model for the given server conditions. Compared with state-of-the-art solutions, Hydra outperforms across all compute-intensity levels on heterogeneous servers.