 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROKA: Robust Knowledge Unlearning against Adversaries
Feb 28, 2026The need for machine unlearning is critical for data privacy, yet existing methods often cause Knowledge Contamination by unintentionally damaging related knowledge. Such a degraded model performance after unlearning has been recently leveraged for new inference and backdoor attacks. Most studies design adversarial unlearning requests that require poisoning or duplicating training data. In this study, we introduce a new unlearning-induced attack model, namely indirect unlearning attack, which does not require data manipulation but exploits the consequence of knowledge contamination to perturb the model accuracy on security-critical predictions. To mitigate this attack, we introduce a theoretical framework that models neural networks as Neural Knowledge Systems. Based on this, we propose ROKA, a robust unlearning strategy centered on Neural Healing. Unlike conventional unlearning methods that only destroy information, ROKA constructively rebalances the model by nullifying the influence of forgotten data while strengthening its conceptual neighbors. To the best of our knowledge, our work is the first to provide a theoretical guarantee for knowledge preservation during unlearning. Evaluations on various large models, including vision transformers, multi-modal models, and large language models, show that ROKA effectively unlearns targets while preserving, or even enhancing, the accuracy of retained data, thereby mitigating the indirect unlearning attacks.
AttnCache: Accelerating Self-Attention Inference for LLM Prefill via Attention Cache
Oct 29, 2025



Large Language Models (LLMs) are widely used in generative applications such as chatting, code generation, and reasoning. However, many realworld workloads such as classification, question answering, recommendation, and text embedding rely solely on the prefill stage of inference, where the model encodes input sequences without performing autoregressive decoding. In these prefill only scenarios, the self-attention computation becomes the primary performance bottleneck due to its quadratic complexity with respect to sequence length. In this paper, we observe that semantically different sentences often produce similar attention maps across layers and heads. Building on this insight, we propose AttnCache, a framework that accelerates the prefill stage of LLM inference by retrieving and reusing similar attention maps. Based on an attention map memorization database, AttnCache employs efficient caching and similarity search techniques to identify and reuse pre-cached attention maps during inference, thereby reducing the computational overhead of self-attention. Experimental results show that AttnCache achieves an average of 1.2x end-to-end and 2x attention speedup on CPU, and 1.6x end-to-end and 3x attention speedup on GPU, with negligible accuracy degradation.
ReDistill: Residual Encoded Distillation for Peak Memory Reduction
Jun 07, 2024



The expansion of neural network sizes and the enhancement of image resolution through modern camera sensors result in heightened memory and power demands for neural networks. Reducing peak memory, which is the maximum memory consumed during the execution of a neural network, is critical to deploy neural networks on edge devices with limited memory budget. A naive approach to reducing peak memory is aggressive down-sampling of feature maps via pooling with large stride, which often results in unacceptable degradation in network performance. To mitigate this problem, we propose residual encoded distillation (ReDistill) for peak memory reduction in a teacher-student framework, in which a student network with less memory is derived from the teacher network using aggressive pooling. We apply our distillation method to multiple problems in computer vision including image classification and diffusion based image generation. For image classification, our method yields 2x-3.2x measured peak memory on an edge GPU with negligible degradation in accuracy for most CNN based architectures. Additionally, our method yields improved test accuracy for tiny vision transformer (ViT) based models distilled from large CNN based teacher architectures. For diffusion-based image generation, our proposed distillation method yields a denoising network with 4x lower theoretical peak memory while maintaining decent diversity and fidelity for image generation. Experiments demonstrate our method's superior performance compared to other feature-based and response-based distillation methods.
MEMO : Accelerating Transformers with Memoization on Big Memory Systems
Jan 23, 2023Transformers gain popularity because of their superior prediction accuracy and inference throughput. However, the transformer is computation-intensive, causing a long inference time. The existing work to accelerate transformer inferences has limitations because of the changes to transformer architectures or the need for specialized hardware. In this paper, we identify the opportunities of using memoization to accelerate the attention mechanism in transformers without the above limitation. Built upon a unique observation that there is a rich similarity in attention computation across inference sequences, we build an attention database upon the emerging big memory system. We introduce the embedding technique to find semantically similar inputs to identify computation similarity. We also introduce a series of techniques such as memory mapping and selective memoization to avoid memory copy and unnecessary overhead. We enable 21% performance improvement on average (up to 68%) with the TB-scale attention database and with ignorable loss in inference accuracy.
Hydra: Hybrid Server Power Model
Jul 20, 2022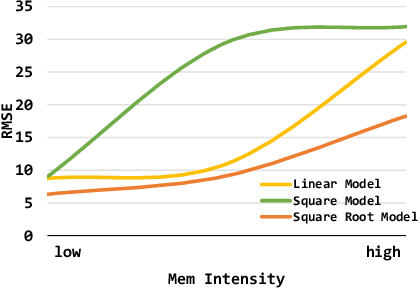
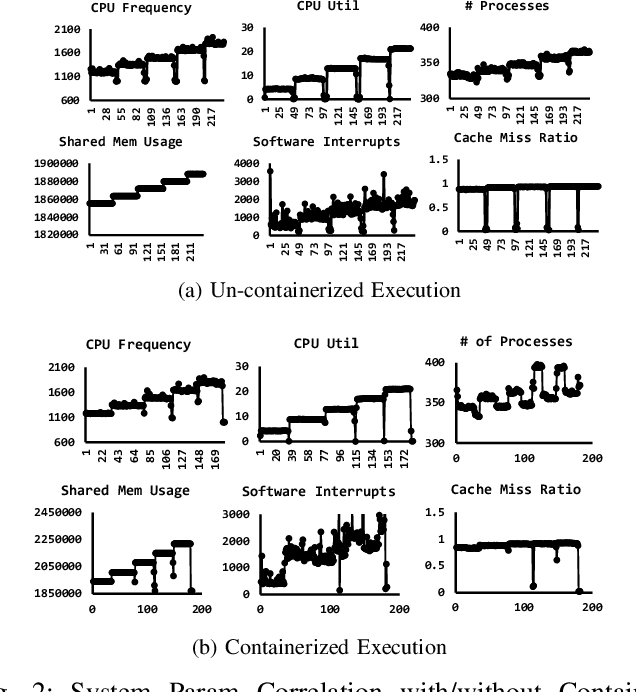
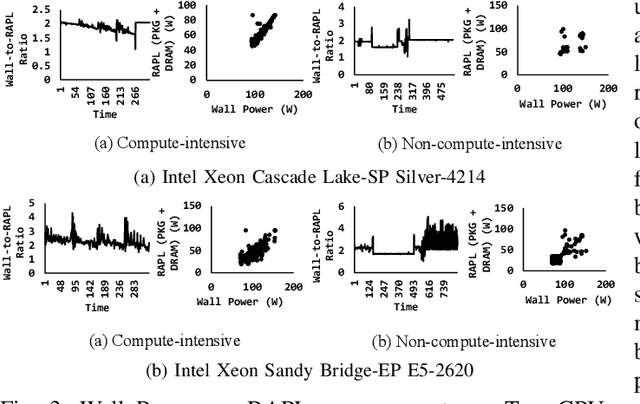
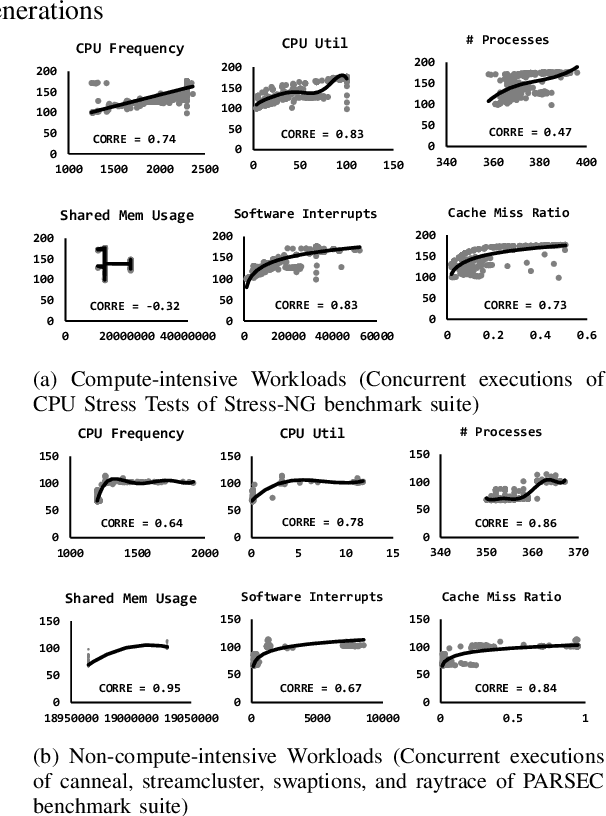
With the growing complexity of big data workloads that require abundant data and computation, data centers consume a tremendous amount of power daily. In an effort to minimize data center power consumption, several studies developed power models that can be used for job scheduling either reducing the number of active servers or balancing workloads across servers at their peak energy efficiency points. Due to increasing software and hardware heterogeneity, we observed that there is no single power model that works the best for all server conditions. Some complicated machine learning models themselves incur performance and power overheads and hence it is not desirable to use them frequently. There are no power models that consider containerized workload execution. In this paper, we propose a hybrid server power model, Hydra, that considers both prediction accuracy and performance overhead. Hydra dynamically chooses the best power model for the given server conditions. Compared with state-of-the-art solutions, Hydra outperforms across all compute-intensity levels on heterogeneous servers.
Revealing Secrets From Pre-trained Models
Jul 19, 2022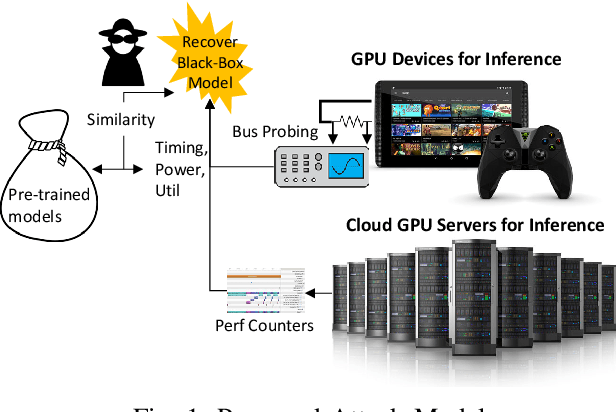
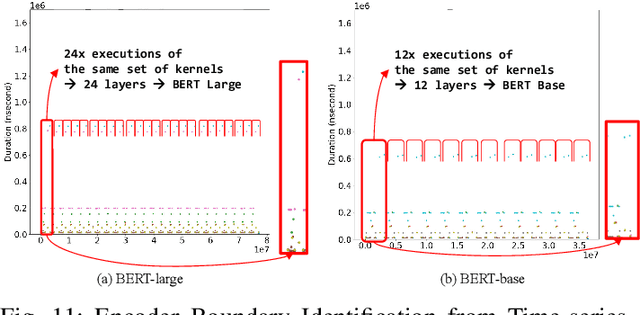
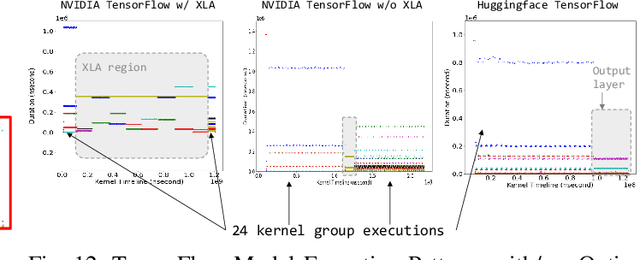
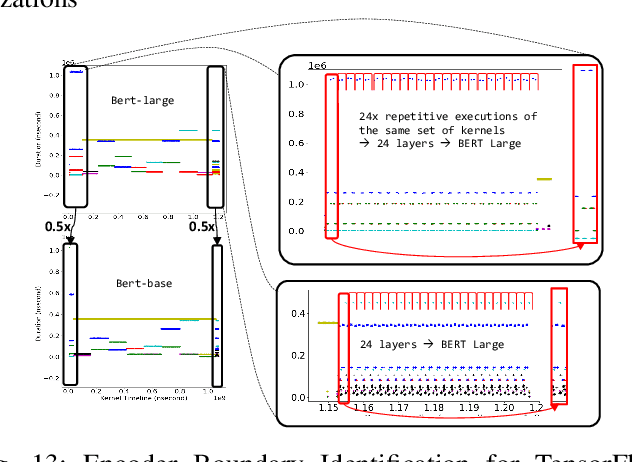
With the growing burden of training deep learning models with large data sets, transfer-learning has been widely adopted in many emerging deep learning algorithms. Transformer models such as BERT are the main player in natural language processing and use transfer-learning as a de facto standard training method. A few big data companies release pre-trained models that are trained with a few popular datasets with which end users and researchers fine-tune the model with their own datasets. Transfer-learning significantly reduces the time and effort of training models. However, it comes at the cost of security concerns. In this paper, we show a new observation that pre-trained models and fine-tuned models have significantly high similarities in weight values. Also, we demonstrate that there exist vendor-specific computing patterns even for the same models. With these new findings, we propose a new model extraction attack that reveals the model architecture and the pre-trained model used by the black-box victim model with vendor-specific computing patterns and then estimates the entire model weights based on the weight value similarities between the fine-tuned model and pre-trained model. We also show that the weight similarity can be leveraged for increasing the model extraction feasibility through a novel weight extraction pruning.
Characterization of Semantic Segmentation Models on Mobile Platforms for Self-Navigation in Disaster-Struck Zones
Feb 03, 2022
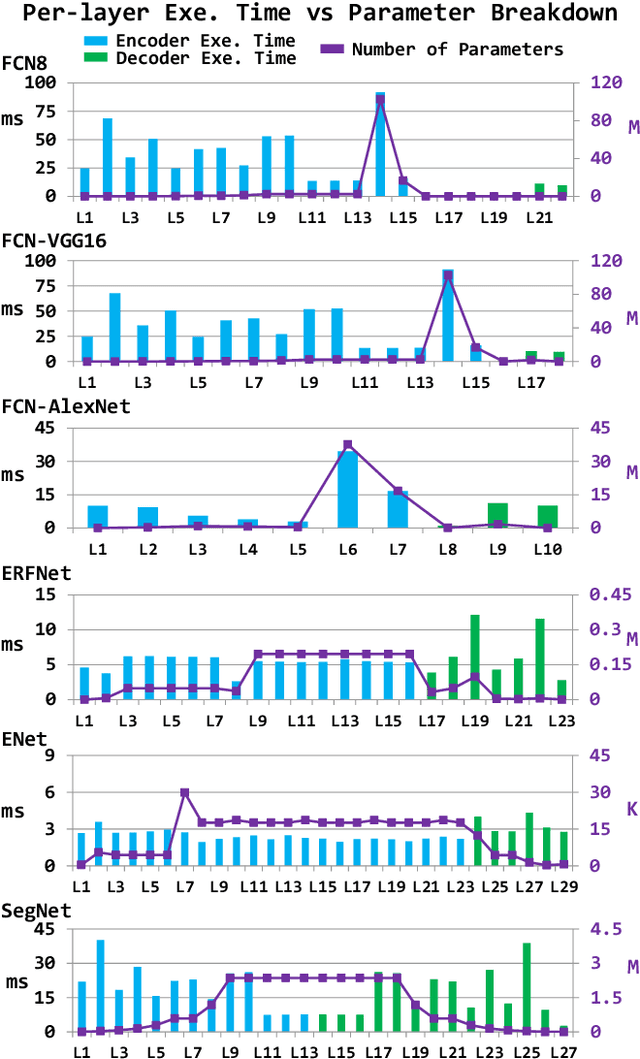
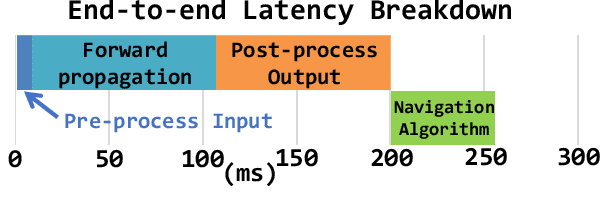
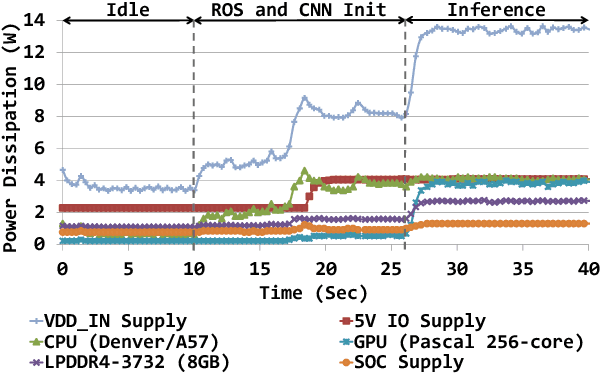
The role of unmanned vehicles for searching and localizing the victims in disaster impacted areas such as earthquake-struck zones is getting more important. Self-navigation on an earthquake zone has a unique challenge of detecting irregularly shaped obstacles such as road cracks, debris on the streets, and water puddles. In this paper, we characterize a number of state-of-the-art FCN models on mobile embedded platforms for self-navigation at these sites containing extremely irregular obstacles. We evaluate the models in terms of accuracy, performance, and energy efficiency. We present a few optimizations for our designed vision system. Lastly, we discuss the trade-offs of these models for a couple of mobile platforms that can each perform self-navigation. To enable vehicles to safely navigate earthquake-struck zones, we compiled a new annotated image database of various earthquake impacted regions that is different than traditional road damage databases. We train our database with a number of state-of-the-art semantic segmentation models in order to identify obstacles unique to earthquake-struck zones. Based on the statistics and tradeoffs, an optimal CNN model is selected for the mobile vehicular platforms, which we apply to both low-power and extremely low-power configurations of our design. To our best knowledge, this is the first study that identifies unique challenges and discusses the accuracy, performance, and energy impact of edge-based self-navigation mobile vehicles for earthquake-struck zones. Our proposed database and trained models are publicly available.
Tango: A Deep Neural Network Benchmark Suite for Various Accelerators
Jan 14, 2019
Deep neural networks (DNNs) have been proving the effectiveness in various computing fields. To provide more efficient computing platforms for DNN applications, it is essential to have evaluation environments that include assorted benchmark workloads. Though a few DNN benchmark suites have been recently released, most of them require to install proprietary DNN libraries or resource-intensive DNN frameworks, which are hard to run on resource-limited mobile platforms or architecture simulators. To provide a more scalable evaluation environment, we propose a new DNN benchmark suite that can run on any platform that supports CUDA and OpenCL. The proposed benchmark suite includes the most widely used five convolution neural networks and two recurrent neural networks. We provide in-depth architectural statistics of these networks while running them on an architecture simulator, a server- and a mobile-GPU, and a mobile FPGA.