 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReDistill: Residual Encoded Distillation for Peak Memory Reduction
Jun 07, 2024



The expansion of neural network sizes and the enhancement of image resolution through modern camera sensors result in heightened memory and power demands for neural networks. Reducing peak memory, which is the maximum memory consumed during the execution of a neural network, is critical to deploy neural networks on edge devices with limited memory budget. A naive approach to reducing peak memory is aggressive down-sampling of feature maps via pooling with large stride, which often results in unacceptable degradation in network performance. To mitigate this problem, we propose residual encoded distillation (ReDistill) for peak memory reduction in a teacher-student framework, in which a student network with less memory is derived from the teacher network using aggressive pooling. We apply our distillation method to multiple problems in computer vision including image classification and diffusion based image generation. For image classification, our method yields 2x-3.2x measured peak memory on an edge GPU with negligible degradation in accuracy for most CNN based architectures. Additionally, our method yields improved test accuracy for tiny vision transformer (ViT) based models distilled from large CNN based teacher architectures. For diffusion-based image generation, our proposed distillation method yields a denoising network with 4x lower theoretical peak memory while maintaining decent diversity and fidelity for image generation. Experiments demonstrate our method's superior performance compared to other feature-based and response-based distillation methods.
Revealing Secrets From Pre-trained Models
Jul 19, 2022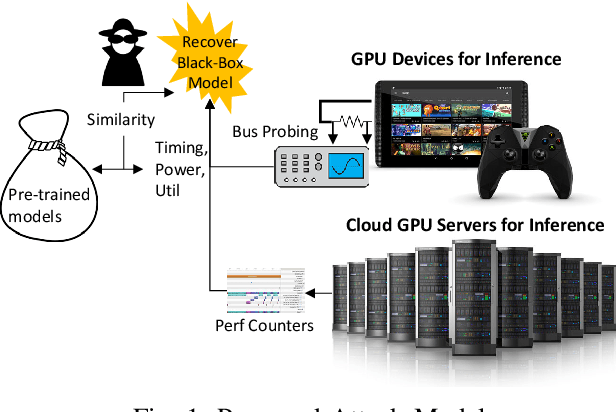
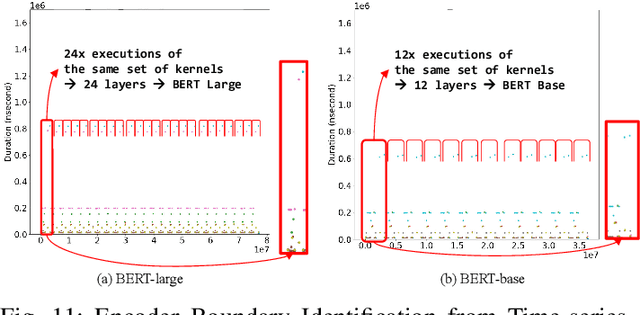
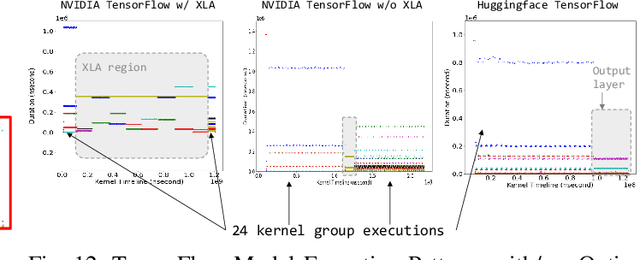
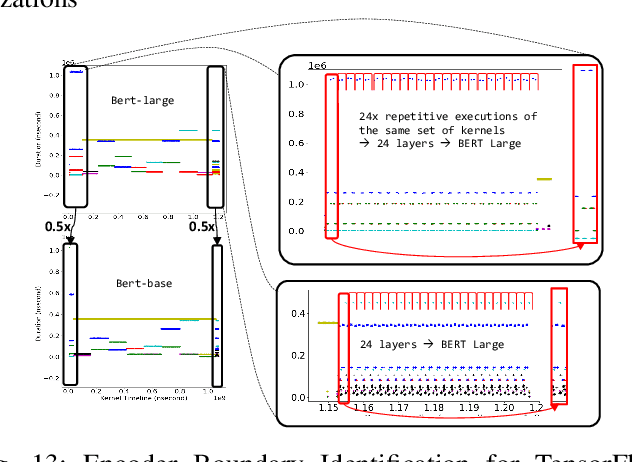
With the growing burden of training deep learning models with large data sets, transfer-learning has been widely adopted in many emerging deep learning algorithms. Transformer models such as BERT are the main player in natural language processing and use transfer-learning as a de facto standard training method. A few big data companies release pre-trained models that are trained with a few popular datasets with which end users and researchers fine-tune the model with their own datasets. Transfer-learning significantly reduces the time and effort of training models. However, it comes at the cost of security concerns. In this paper, we show a new observation that pre-trained models and fine-tuned models have significantly high similarities in weight values. Also, we demonstrate that there exist vendor-specific computing patterns even for the same models. With these new findings, we propose a new model extraction attack that reveals the model architecture and the pre-trained model used by the black-box victim model with vendor-specific computing patterns and then estimates the entire model weights based on the weight value similarities between the fine-tuned model and pre-trained model. We also show that the weight similarity can be leveraged for increasing the model extraction feasibility through a novel weight extraction pruning.