 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Cross Diffusion Guidance for Text-to-Image Synthesis of Similar Subjects
Nov 28, 2024



Diffusion models have achieved unprecedented fidelity and diversity for synthesizing image, video, 3D assets, etc. However, subject mixing is a known and unresolved issue for diffusion-based image synthesis, particularly for synthesizing multiple similar-looking subjects. We propose Self-Cross diffusion guidance to penalize the overlap between cross-attention maps and aggregated self-attention maps. Compared to previous methods based on self-attention or cross-attention alone, our self-cross guidance is more effective in eliminating subject mixing. What's more, our guidance addresses mixing for all relevant patches of a subject beyond the most discriminant one, e.g., beak of a bird. We aggregate self-attention maps of automatically selected patches for a subject to form a region that the whole subject attends to. Our method is training-free and can boost the performance of any transformer-based diffusion model such as Stable Diffusion.% for synthesizing similar subjects. We also release a more challenging benchmark with many text prompts of similar-looking subjects and utilize GPT-4o for automatic and reliable evaluation. Extensive qualitative and quantitative results demonstrate the effectiveness of our Self-Cross guidance.
ReDistill: Residual Encoded Distillation for Peak Memory Reduction
Jun 07, 2024



The expansion of neural network sizes and the enhancement of image resolution through modern camera sensors result in heightened memory and power demands for neural networks. Reducing peak memory, which is the maximum memory consumed during the execution of a neural network, is critical to deploy neural networks on edge devices with limited memory budget. A naive approach to reducing peak memory is aggressive down-sampling of feature maps via pooling with large stride, which often results in unacceptable degradation in network performance. To mitigate this problem, we propose residual encoded distillation (ReDistill) for peak memory reduction in a teacher-student framework, in which a student network with less memory is derived from the teacher network using aggressive pooling. We apply our distillation method to multiple problems in computer vision including image classification and diffusion based image generation. For image classification, our method yields 2x-3.2x measured peak memory on an edge GPU with negligible degradation in accuracy for most CNN based architectures. Additionally, our method yields improved test accuracy for tiny vision transformer (ViT) based models distilled from large CNN based teacher architectures. For diffusion-based image generation, our proposed distillation method yields a denoising network with 4x lower theoretical peak memory while maintaining decent diversity and fidelity for image generation. Experiments demonstrate our method's superior performance compared to other feature-based and response-based distillation methods.
Training Class-Imbalanced Diffusion Model Via Overlap Optimization
Feb 16, 2024



Diffusion models have made significant advances recently in high-quality image synthesis and related tasks. However, diffusion models trained on real-world datasets, which often follow long-tailed distributions, yield inferior fidelity for tail classes. Deep generative models, including diffusion models, are biased towards classes with abundant training images. To address the observed appearance overlap between synthesized images of rare classes and tail classes, we propose a method based on contrastive learning to minimize the overlap between distributions of synthetic images for different classes. We show variants of our probabilistic contrastive learning method can be applied to any class conditional diffusion model. We show significant improvement in image synthesis using our loss for multiple datasets with long-tailed distribution. Extensive experimental results demonstrate that the proposed method can effectively handle imbalanced data for diffusion-based generation and classification models. Our code and datasets will be publicly available at https://github.com/yanliang3612/DiffROP.
Latent Space Editing in Transformer-Based Flow Matching
Dec 17, 2023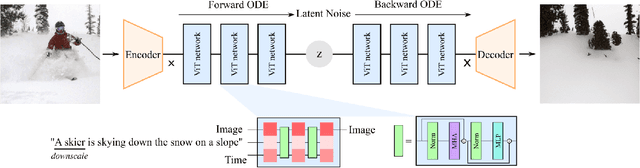
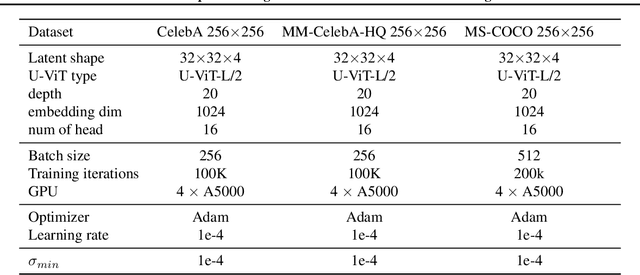


This paper strives for image editing via generative models. Flow Matching is an emerging generative modeling technique that offers the advantage of simple and efficient training. Simultaneously, a new transformer-based U-ViT has recently been proposed to replace the commonly used UNet for better scalability and performance in generative modeling. Hence, Flow Matching with a transformer backbone offers the potential for scalable and high-quality generative modeling, but their latent structure and editing ability are as of yet unknown. Hence, we adopt this setting and explore how to edit images through latent space manipulation. We introduce an editing space, which we call $u$-space, that can be manipulated in a controllable, accumulative, and composable manner. Additionally, we propose a tailored sampling solution to enable sampling with the more efficient adaptive step-size ODE solvers. Lastly, we put forth a straightforward yet powerful method for achieving fine-grained and nuanced editing using text prompts. Our framework is simple and efficient, all while being highly effective at editing images while preserving the essence of the original content. Our code will be publicly available at https://taohu.me/lfm/
Generative Data Augmentation Improves Scribble-supervised Semantic Segmentation
Nov 28, 2023



Recent advances in generative models, such as diffusion models, have made generating high-quality synthetic images widely accessible. Prior works have shown that training on synthetic images improves many perception tasks, such as image classification, object detection, and semantic segmentation. We are the first to explore generative data augmentations for scribble-supervised semantic segmentation. We propose a generative data augmentation method that leverages a ControlNet diffusion model conditioned on semantic scribbles to produce high-quality training data. However, naive implementations of generative data augmentations may inadvertently harm the performance of the downstream segmentor rather than improve it. We leverage classifier-free diffusion guidance to enforce class consistency and introduce encode ratios to trade off data diversity for data realism. Using the guidance scale and encode ratio, we are able to generate a spectrum of high-quality training images. We propose multiple augmentation schemes and find that these schemes significantly impact model performance, especially in the low-data regime. Our framework further reduces the gap between the performance of scribble-supervised segmentation and that of fully-supervised segmentation. We also show that our framework significantly improves segmentation performance on small datasets, even surpassing fully-supervised segmentation.
Divide and Conquer: Text Semantic Matching with Disentangled Keywords and Intents
Mar 06, 2022
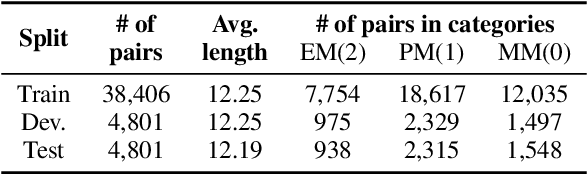
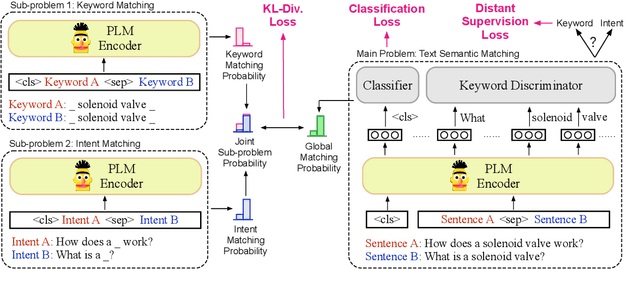
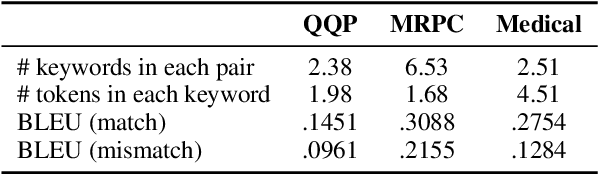
Text semantic matching is a fundamental task that has been widely used in various scenarios, such as community question answering, information retrieval, and recommendation. Most state-of-the-art matching models, e.g., BERT, directly perform text comparison by processing each word uniformly. However, a query sentence generally comprises content that calls for different levels of matching granularity. Specifically, keywords represent factual information such as action, entity, and event that should be strictly matched, while intents convey abstract concepts and ideas that can be paraphrased into various expressions. In this work, we propose a simple yet effective training strategy for text semantic matching in a divide-and-conquer manner by disentangling keywords from intents. Our approach can be easily combined with pre-trained language models (PLM) without influencing their inference efficiency, achieving stable performance improvements against a wide range of PLMs on three benchmarks.
Deep-learning-based coupled flow-geomechanics surrogate model for CO$_2$ sequestration
May 04, 2021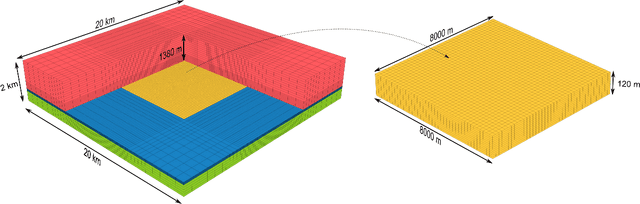
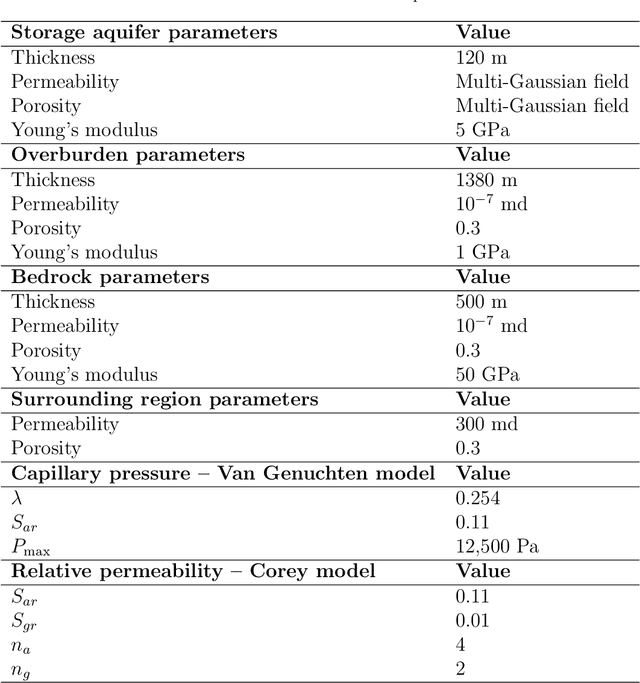
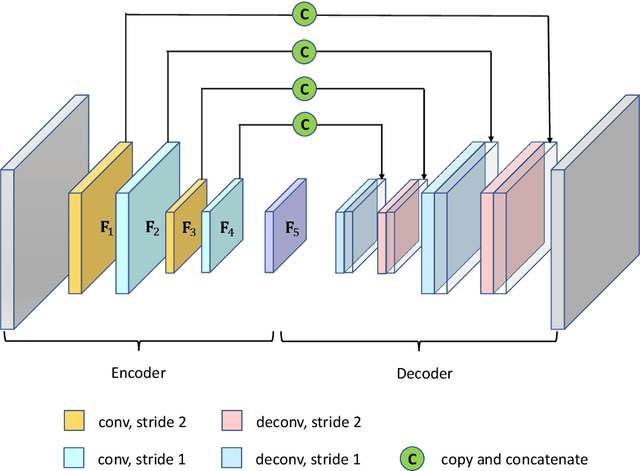
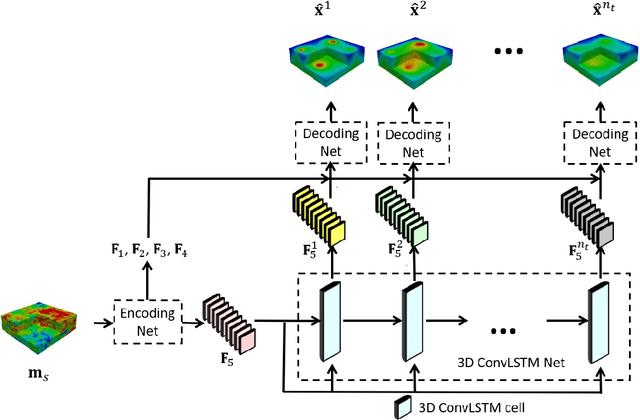
A deep-learning-based surrogate model capable of predicting flow and geomechanical responses in CO2 storage operations is presented and applied. The 3D recurrent R-U-Net model combines deep convolutional and recurrent neural networks to capture the spatial distribution and temporal evolution of saturation, pressure and surface displacement fields. The method is trained using high-fidelity simulation results for 2000 storage-aquifer realizations characterized by multi-Gaussian porosity and log-permeability fields. These numerical solutions are expensive because the domain that must be considered for the coupled problem includes not only the storage aquifer but also a surrounding region, overburden and bedrock. The surrogate model is trained to predict the 3D CO2 saturation and pressure fields in the storage aquifer, and 2D displacement maps at the Earth's surface. Detailed comparisons between surrogate model and full-order simulation results for new (test-case) storage-aquifer realizations are presented. The saturation, pressure and surface displacement fields provided by the surrogate model display a high degree of accuracy, both for individual test-case realizations and for ensemble statistics. Finally, the the recurrent R-U-Net surrogate model is applied with a rejection sampling procedure for data assimilation. Although the observations consist of only a small number of surface displacement measurements, significant uncertainty reduction in pressure buildup at the top of the storage aquifer (caprock) is achieved.
FroDO: From Detections to 3D Objects
May 11, 2020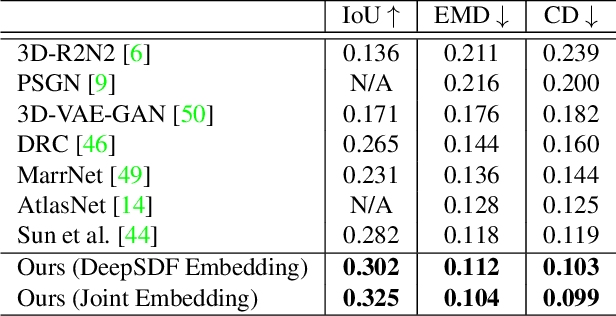


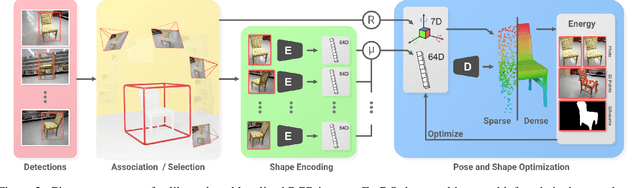
Object-oriented maps are important for scene understanding since they jointly capture geometry and semantics, allow individual instantiation and meaningful reasoning about objects. We introduce FroDO, a method for accurate 3D reconstruction of object instances from RGB video that infers object location, pose and shape in a coarse-to-fine manner. Key to FroDO is to embed object shapes in a novel learnt space that allows seamless switching between sparse point cloud and dense DeepSDF decoding. Given an input sequence of localized RGB frames, FroDO first aggregates 2D detections to instantiate a category-aware 3D bounding box per object. A shape code is regressed using an encoder network before optimizing shape and pose further under the learnt shape priors using sparse and dense shape representations. The optimization uses multi-view geometric, photometric and silhouette losses. We evaluate on real-world datasets, including Pix3D, Redwood-OS, and ScanNet, for single-view, multi-view, and multi-object reconstruction.
Multiphase flow prediction with deep neural networks
Oct 21, 2019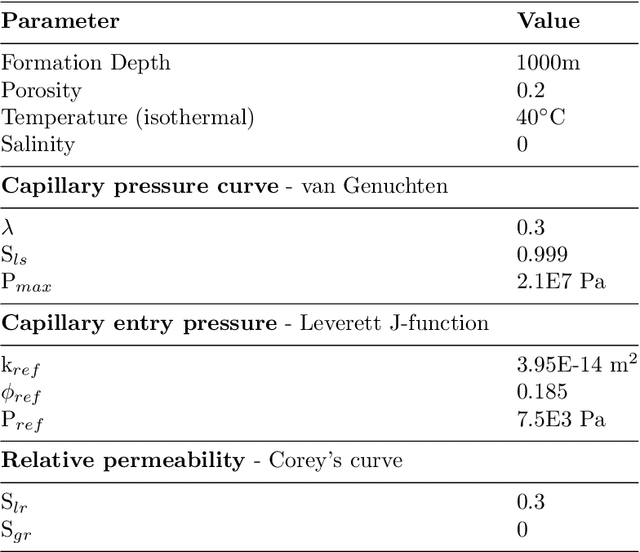
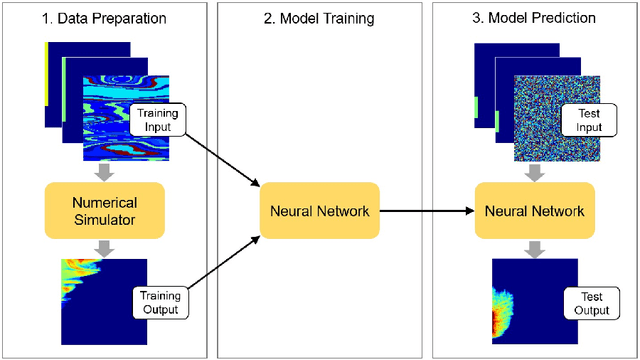
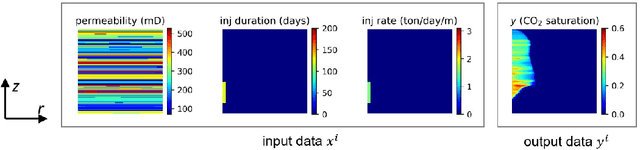

This paper proposes a deep neural network approach for predicting multiphase flow in heterogeneous domains with high computational efficiency. The deep neural network model is able to handle permeability heterogeneity in high dimensional systems, and can learn the interplay of viscous, gravity, and capillary forces from small data sets. Using the example of carbon dioxide (CO2) storage, we demonstrate that the model can generate highly accurate predictions of a CO2 saturation distribution given a permeability field, injection duration, injection rate, and injection location. The trained neural network model has an excellent ability to interpolate and to a limited extent, the ability to extrapolate beyond the training data ranges. To improve the prediction accuracy when the neural network model needs to extrapolate, we propose a transfer learning (fine-tuning) procedure that can quickly teach the neural network model new information without going through massive data collection and retraining. Based on this trained neural network model, a web-based tool is provided that allows users to perform CO2-water multiphase flow calculations online. With the tools provided in this paper, the deep neural network approach can provide a computationally efficient substitute for repetitive forward multiphase flow simulations, which can be adopted to the context of history matching and uncertainty quantification.
A deep-learning-based surrogate model for data assimilation in dynamic subsurface flow problems
Aug 16, 2019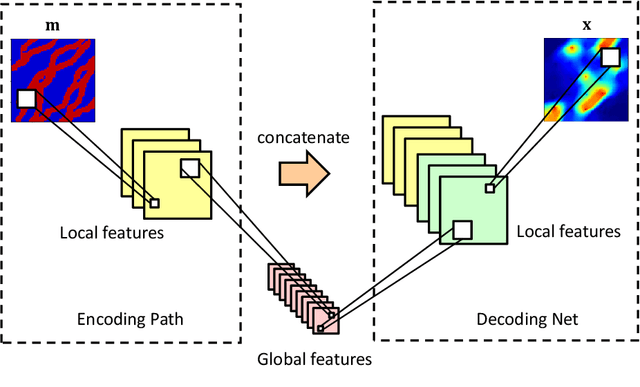
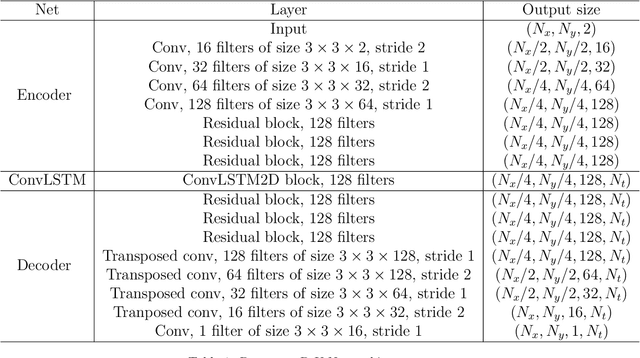
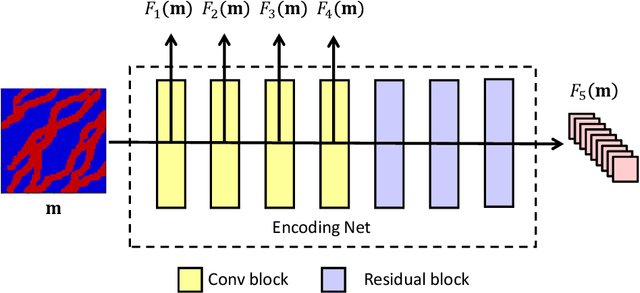
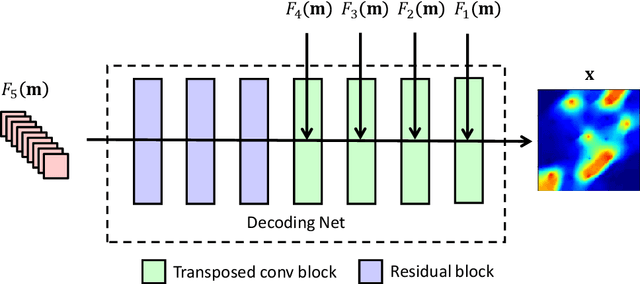
A deep-learning-based surrogate model is developed and applied for predicting dynamic subsurface flow in channelized geological models. The surrogate model is based on deep convolutional and recurrent neural network architectures, specifically a residual U-Net and a convolutional long short term memory recurrent network. Training samples entail global pressure and saturation maps, at a series of time steps, generated by simulating oil-water flow in many (1500 in our case) realizations of a 2D channelized system. After training, the `recurrent R-U-Net' surrogate model is shown to be capable of accurately predicting dynamic pressure and saturation maps and well rates (e.g., time-varying oil and water rates at production wells) for new geological realizations. Assessments demonstrating high surrogate-model accuracy are presented for an individual geological realization and for an ensemble of 500 test geomodels. The surrogate model is then used for the challenging problem of data assimilation (history matching) in a channelized system. For this study, posterior reservoir models are generated using the randomized maximum likelihood method, with the permeability field represented using the recently developed CNN-PCA parameterization. The flow responses required during the data assimilation procedure are provided by the recurrent R-U-Net. The overall approach is shown to lead to substantial reduction in prediction uncertainty. High-fidelity numerical simulation results for the posterior geomodels (generated by the surrogate-based data assimilation procedure) are shown to be in essential agreement with the recurrent R-U-Net predictions. The accuracy and dramatic speedup provided by the surrogate model suggest that it may eventually enable the application of more formal posterior sampling methods in realistic problems.