 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Cross Diffusion Guidance for Text-to-Image Synthesis of Similar Subjects
Nov 28, 2024



Diffusion models have achieved unprecedented fidelity and diversity for synthesizing image, video, 3D assets, etc. However, subject mixing is a known and unresolved issue for diffusion-based image synthesis, particularly for synthesizing multiple similar-looking subjects. We propose Self-Cross diffusion guidance to penalize the overlap between cross-attention maps and aggregated self-attention maps. Compared to previous methods based on self-attention or cross-attention alone, our self-cross guidance is more effective in eliminating subject mixing. What's more, our guidance addresses mixing for all relevant patches of a subject beyond the most discriminant one, e.g., beak of a bird. We aggregate self-attention maps of automatically selected patches for a subject to form a region that the whole subject attends to. Our method is training-free and can boost the performance of any transformer-based diffusion model such as Stable Diffusion.% for synthesizing similar subjects. We also release a more challenging benchmark with many text prompts of similar-looking subjects and utilize GPT-4o for automatic and reliable evaluation. Extensive qualitative and quantitative results demonstrate the effectiveness of our Self-Cross guidance.
Generative Data Augmentation Improves Scribble-supervised Semantic Segmentation
Nov 28, 2023Recent advances in generative models, such as diffusion models, have made generating high-quality synthetic images widely accessible. Prior works have shown that training on synthetic images improves many perception tasks, such as image classification, object detection, and semantic segmentation. We are the first to explore generative data augmentations for scribble-supervised semantic segmentation. We propose a generative data augmentation method that leverages a ControlNet diffusion model conditioned on semantic scribbles to produce high-quality training data. However, naive implementations of generative data augmentations may inadvertently harm the performance of the downstream segmentor rather than improve it. We leverage classifier-free diffusion guidance to enforce class consistency and introduce encode ratios to trade off data diversity for data realism. Using the guidance scale and encode ratio, we are able to generate a spectrum of high-quality training images. We propose multiple augmentation schemes and find that these schemes significantly impact model performance, especially in the low-data regime. Our framework further reduces the gap between the performance of scribble-supervised segmentation and that of fully-supervised segmentation. We also show that our framework significantly improves segmentation performance on small datasets, even surpassing fully-supervised segmentation.
Open-Vocabulary Panoptic Segmentation with MaskCLIP
Aug 18, 2022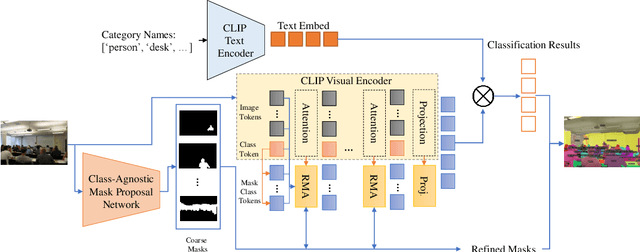


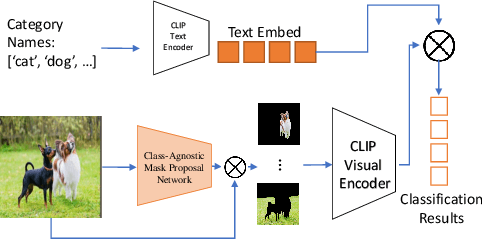
In this paper, we tackle a new computer vision task, open-vocabulary panoptic segmentation, that aims to perform panoptic segmentation (background semantic labeling + foreground instance segmentation) for arbitrary categories of text-based descriptions. We first build a baseline method without finetuning nor distillation to utilize the knowledge in the existing CLIP model. We then develop a new method, MaskCLIP, that is a Transformer-based approach using mask queries with the ViT-based CLIP backbone to perform semantic segmentation and object instance segmentation. Here we design a Relative Mask Attention (RMA) module to account for segmentations as additional tokens to the ViT CLIP model. MaskCLIP learns to efficiently and effectively utilize pre-trained dense/local CLIP features by avoiding the time-consuming operation to crop image patches and compute feature from an external CLIP image model. We obtain encouraging results for open-vocabulary panoptic segmentation and state-of-the-art results for open-vocabulary semantic segmentation on ADE20K and PASCAL datasets. We show qualitative illustration for MaskCLIP with custom categories.