 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Vocabulary Panoptic Segmentation with MaskCLIP
Paper and Code
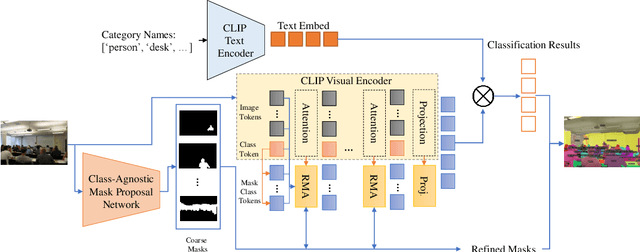


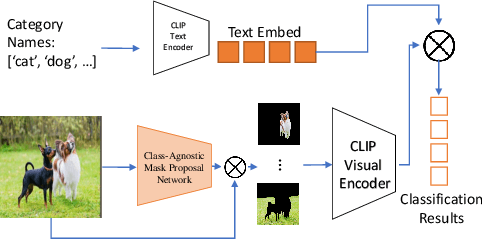
In this paper, we tackle a new computer vision task, open-vocabulary panoptic segmentation, that aims to perform panoptic segmentation (background semantic labeling + foreground instance segmentation) for arbitrary categories of text-based descriptions. We first build a baseline method without finetuning nor distillation to utilize the knowledge in the existing CLIP model. We then develop a new method, MaskCLIP, that is a Transformer-based approach using mask queries with the ViT-based CLIP backbone to perform semantic segmentation and object instance segmentation. Here we design a Relative Mask Attention (RMA) module to account for segmentations as additional tokens to the ViT CLIP model. MaskCLIP learns to efficiently and effectively utilize pre-trained dense/local CLIP features by avoiding the time-consuming operation to crop image patches and compute feature from an external CLIP image model. We obtain encouraging results for open-vocabulary panoptic segmentation and state-of-the-art results for open-vocabulary semantic segmentation on ADE20K and PASCAL datasets. We show qualitative illustration for MaskCLIP with custom categories.