 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAria Digital Twin: A New Benchmark Dataset for Egocentric 3D Machine Perception
Jun 13, 2023
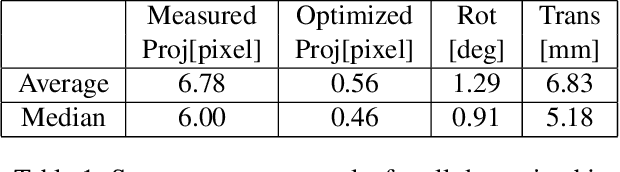
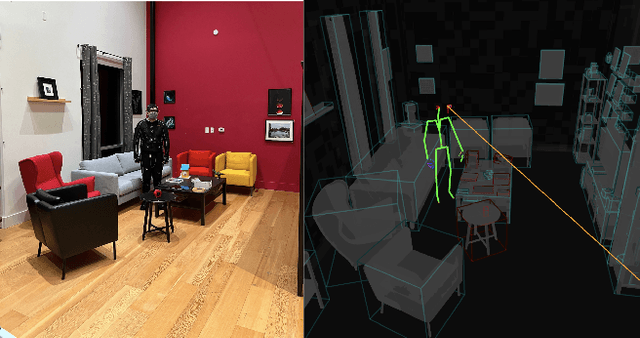
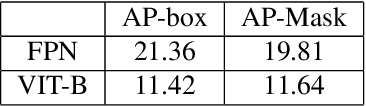
We introduce the Aria Digital Twin (ADT) - an egocentric dataset captured using Aria glasses with extensive object, environment, and human level ground truth. This ADT release contains 200 sequences of real-world activities conducted by Aria wearers in two real indoor scenes with 398 object instances (324 stationary and 74 dynamic). Each sequence consists of: a) raw data of two monochrome camera streams, one RGB camera stream, two IMU streams; b) complete sensor calibration; c) ground truth data including continuous 6-degree-of-freedom (6DoF) poses of the Aria devices, object 6DoF poses, 3D eye gaze vectors, 3D human poses, 2D image segmentations, image depth maps; and d) photo-realistic synthetic renderings. To the best of our knowledge, there is no existing egocentric dataset with a level of accuracy, photo-realism and comprehensiveness comparable to ADT. By contributing ADT to the research community, our mission is to set a new standard for evaluation in the egocentric machine perception domain, which includes very challenging research problems such as 3D object detection and tracking, scene reconstruction and understanding, sim-to-real learning, human pose prediction - while also inspiring new machine perception tasks for augmented reality (AR) applications. To kick start exploration of the ADT research use cases, we evaluated several existing state-of-the-art methods for object detection, segmentation and image translation tasks that demonstrate the usefulness of ADT as a benchmarking dataset.
FroDO: From Detections to 3D Objects
May 11, 2020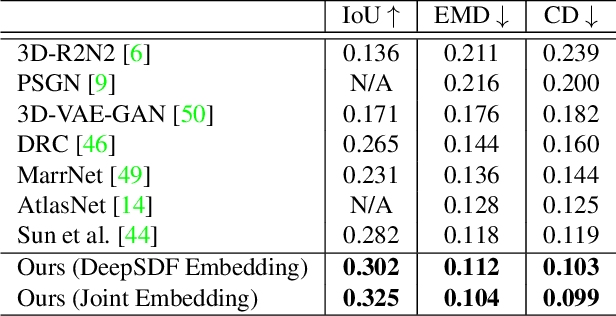


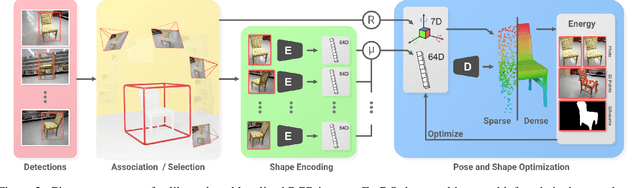
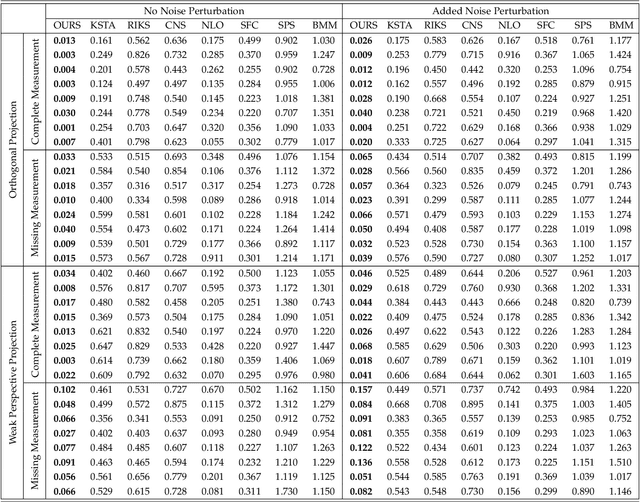
Object-oriented maps are important for scene understanding since they jointly capture geometry and semantics, allow individual instantiation and meaningful reasoning about objects. We introduce FroDO, a method for accurate 3D reconstruction of object instances from RGB video that infers object location, pose and shape in a coarse-to-fine manner. Key to FroDO is to embed object shapes in a novel learnt space that allows seamless switching between sparse point cloud and dense DeepSDF decoding. Given an input sequence of localized RGB frames, FroDO first aggregates 2D detections to instantiate a category-aware 3D bounding box per object. A shape code is regressed using an encoder network before optimizing shape and pose further under the learnt shape priors using sparse and dense shape representations. The optimization uses multi-view geometric, photometric and silhouette losses. We evaluate on real-world datasets, including Pix3D, Redwood-OS, and ScanNet, for single-view, multi-view, and multi-object reconstruction.
Deep Non-Rigid Structure from Motion with Missing Data
Sep 06, 2019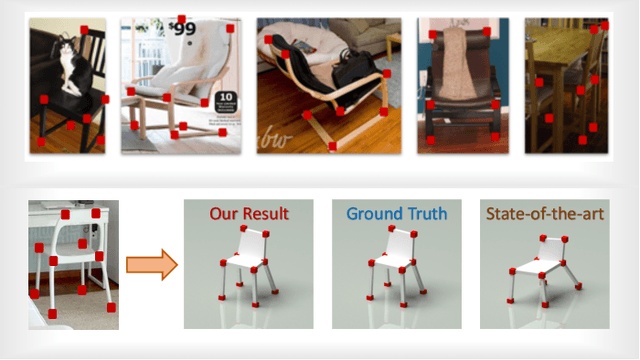


Non-Rigid Structure from Motion (NRSfM) refers to the problem of reconstructing cameras and the 3D point cloud of a non-rigid object from an ensemble of images with 2D correspondences. Current NRSfM algorithms are limited from two perspectives: (i) the number of images, and (ii) the type of shape variability they can handle. These difficulties stem from the inherent conflict between the condition of the system and the degrees of freedom needing to be modeled -- which has hampered its practical utility for many applications within vision. In this paper we propose a novel hierarchical sparse coding model for NRSFM which can overcome (i) and (ii) to such an extent, that NRSFM can be applied to problems in vision previously thought too ill posed. Our approach is realized in practice as the training of an unsupervised deep neural network (DNN) auto-encoder with a unique architecture that is able to disentangle pose from 3D structure. Using modern deep learning computational platforms allows us to solve NRSfM problems at an unprecedented scale and shape complexity. Our approach has no 3D supervision, relying solely on 2D point correspondences. Further, our approach is also able to handle missing/occluded 2D points without the need for matrix completion. Extensive experiments demonstrate the impressive performance of our approach where we exhibit superior precision and robustness against all available state-of-the-art works in some instances by an order of magnitude. We further propose a new quality measure (based on the network weights) which circumvents the need for 3D ground-truth to ascertain the confidence we have in the reconstructability. We believe our work to be a significant advance over state-of-the-art in NRSFM.
Distill Knowledge from NRSfM for Weakly Supervised 3D Pose Learning
Aug 18, 2019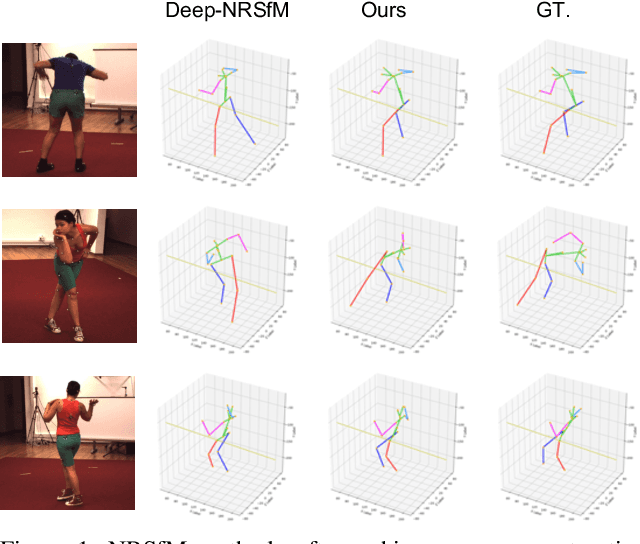
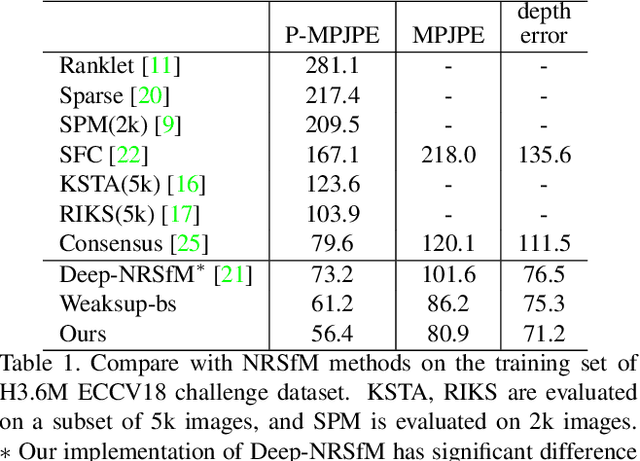
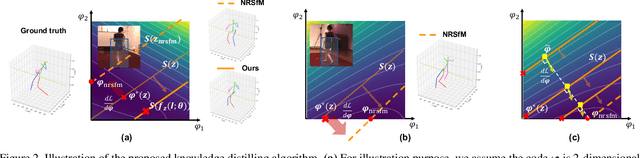
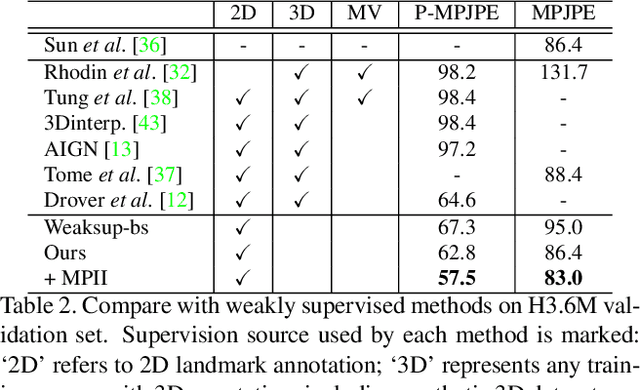
We propose to learn a 3D pose estimator by distilling knowledge from Non-Rigid Structure from Motion (NRSfM). Our method uses solely 2D landmark annotations. No 3D data, multi-view/temporal footage, or object specific prior is required. This alleviates the data bottleneck, which is one of the major concern for supervised methods. The challenge for using NRSfM as teacher is that they often make poor depth reconstruction when the 2D projections have strong ambiguity. Directly using those wrong depth as hard target would negatively impact the student. Instead, we propose a novel loss that ties depth prediction to the cost function used in NRSfM. This gives the student pose estimator freedom to reduce depth error by associating with image features. Validated on H3.6M dataset, our learned 3D pose estimation network achieves more accurate reconstruction compared to NRSfM methods. It also outperforms other weakly supervised methods, in spite of using significantly less supervision.
Deep Non-Rigid Structure from Motion
Aug 11, 2019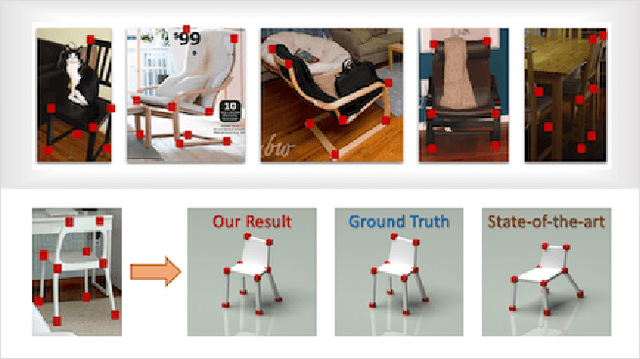
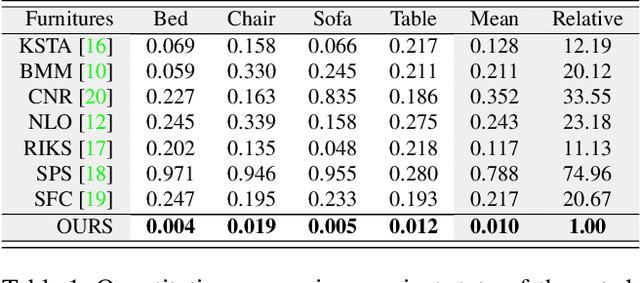

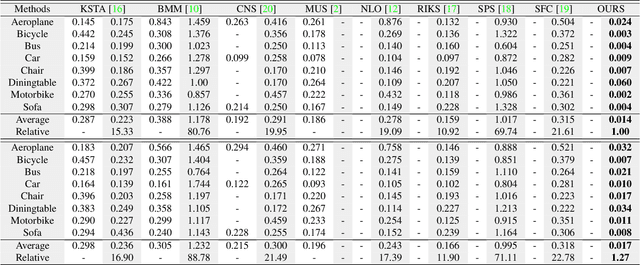
Current non-rigid structure from motion (NRSfM) algorithms are mainly limited with respect to: (i) the number of images, and (ii) the type of shape variability they can handle. This has hampered the practical utility of NRSfM for many applications within vision. In this paper we propose a novel deep neural network to recover camera poses and 3D points solely from an ensemble of 2D image coordinates. The proposed neural network is mathematically interpretable as a multi-layer block sparse dictionary learning problem, and can handle problems of unprecedented scale and shape complexity. Extensive experiments demonstrate the impressive performance of our approach where we exhibit superior precision and robustness against all available state-of-the-art works in the order of magnitude. We further propose a quality measure (based on the network weights) which circumvents the need for 3D ground-truth to ascertain the confidence we have in the reconstruction.
Deep Interpretable Non-Rigid Structure from Motion
Feb 28, 2019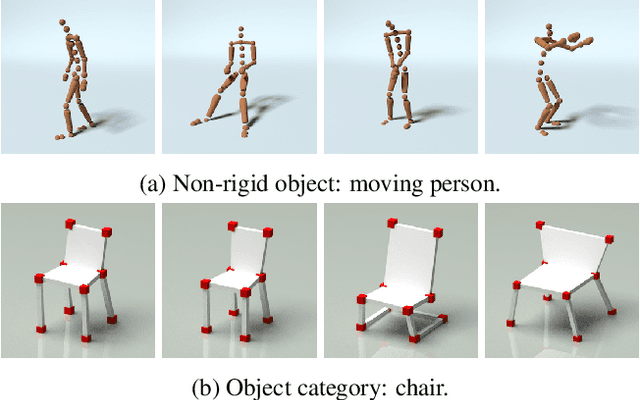
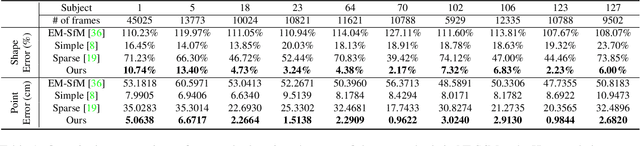

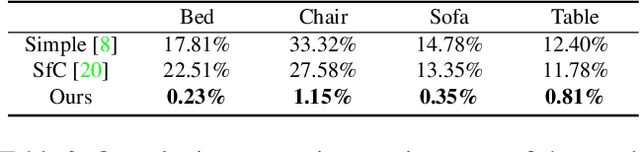
All current non-rigid structure from motion (NRSfM) algorithms are limited with respect to: (i) the number of images, and (ii) the type of shape variability they can handle. This has hampered the practical utility of NRSfM for many applications within vision. In this paper we propose a novel deep neural network to recover camera poses and 3D points solely from an ensemble of 2D image coordinates. The proposed neural network is mathematically interpretable as a multi-layer block sparse dictionary learning problem, and can handle problems of unprecedented scale and shape complexity. Extensive experiments demonstrate the impressive performance of our approach where we exhibit superior precision and robustness against all available state-of-the-art works. The considerable model capacity of our approach affords remarkable generalization to unseen data. We propose a quality measure (based on the network weights) which circumvents the need for 3D ground-truth to ascertain the confidence we have in the reconstruction. Once the network's weights are estimated (for a non-rigid object) we show how our approach can effectively recover 3D shape from a single image -- outperforming comparable methods that rely on direct 3D supervision.
CNNs are Globally Optimal Given Multi-Layer Support
Dec 14, 2017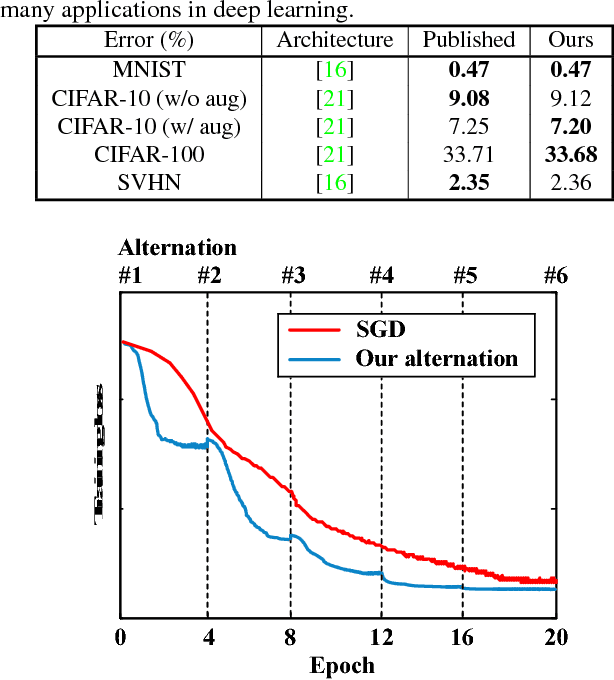
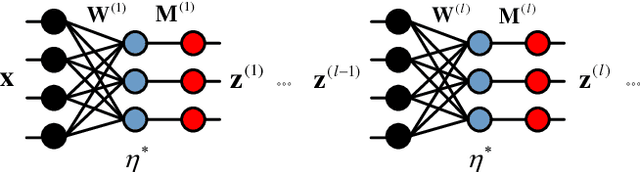
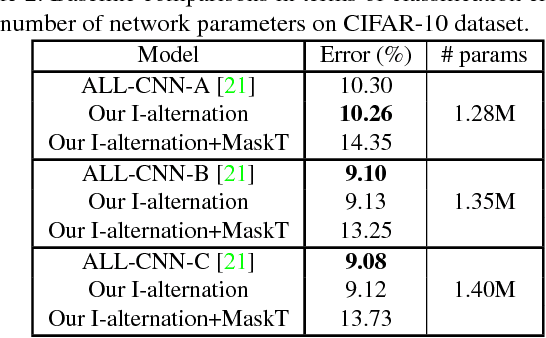
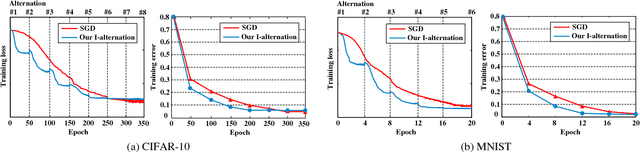
Stochastic Gradient Descent (SGD) is the central workhorse for training modern CNNs. Although giving impressive empirical performance it can be slow to converge. In this paper we explore a novel strategy for training a CNN using an alternation strategy that offers substantial speedups during training. We make the following contributions: (i) replace the ReLU non-linearity within a CNN with positive hard-thresholding, (ii) reinterpret this non-linearity as a binary state vector making the entire CNN linear if the multi-layer support is known, and (iii) demonstrate that under certain conditions a global optima to the CNN can be found through local descent. We then employ a novel alternation strategy (between weights and support) for CNN training that leads to substantially faster convergence rates, nice theoretical properties, and achieving state of the art results across large scale datasets (e.g. ImageNet) as well as other standard benchmarks.
Take it in your stride: Do we need striding in CNNs?
Dec 07, 2017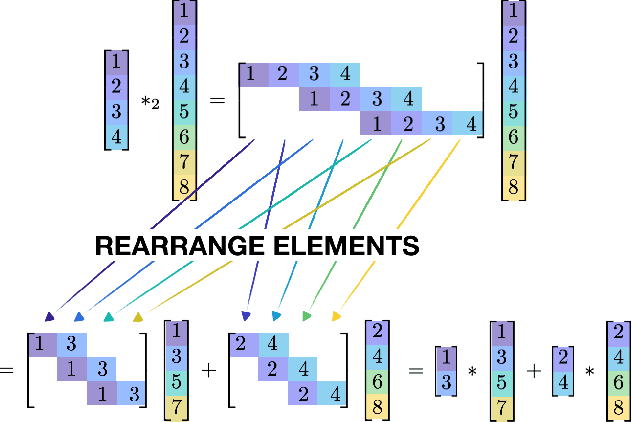

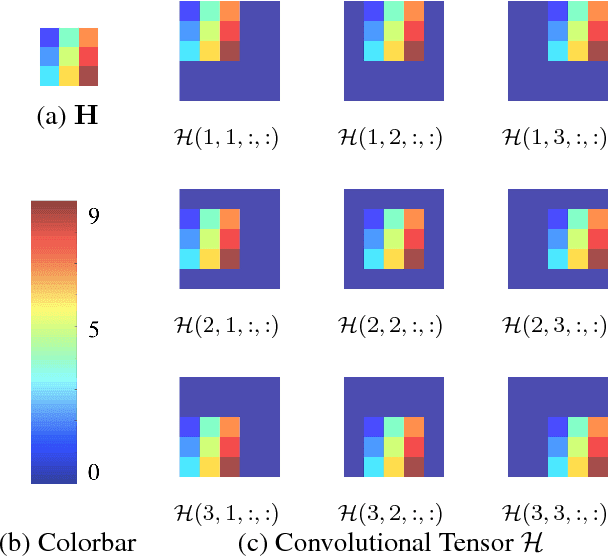

Since their inception, CNNs have utilized some type of striding operator to reduce the overlap of receptive fields and spatial dimensions. Although having clear heuristic motivations (i.e. lowering the number of parameters to learn) the mathematical role of striding within CNN learning remains unclear. This paper offers a novel and mathematical rigorous perspective on the role of the striding operator within modern CNNs. Specifically, we demonstrate theoretically that one can always represent a CNN that incorporates striding with an equivalent non-striding CNN which has more filters and smaller size. Through this equivalence we are then able to characterize striding as an additional mechanism for parameter sharing among channels, thus reducing training complexity. Finally, the framework presented in this paper offers a new mathematical perspective on the role of striding which we hope shall facilitate and simplify the future theoretical analysis of CNNs.
Image2Mesh: A Learning Framework for Single Image 3D Reconstruction
Nov 29, 2017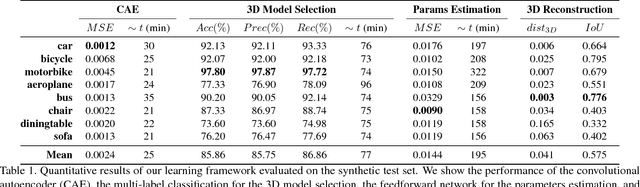


One challenge that remains open in 3D deep learning is how to efficiently represent 3D data to feed deep networks. Recent works have relied on volumetric or point cloud representations, but such approaches suffer from a number of issues such as computational complexity, unordered data, and lack of finer geometry. This paper demonstrates that a mesh representation (i.e. vertices and faces to form polygonal surfaces) is able to capture fine-grained geometry for 3D reconstruction tasks. A mesh however is also unstructured data similar to point clouds. We address this problem by proposing a learning framework to infer the parameters of a compact mesh representation rather than learning from the mesh itself. This compact representation encodes a mesh using free-form deformation and a sparse linear combination of models allowing us to reconstruct 3D meshes from single images. In contrast to prior work, we do not rely on silhouettes and landmarks to perform 3D reconstruction. We evaluate our method on synthetic and real-world datasets with very promising results. Our framework efficiently reconstructs 3D objects in a low-dimensional way while preserving its important geometrical aspects.
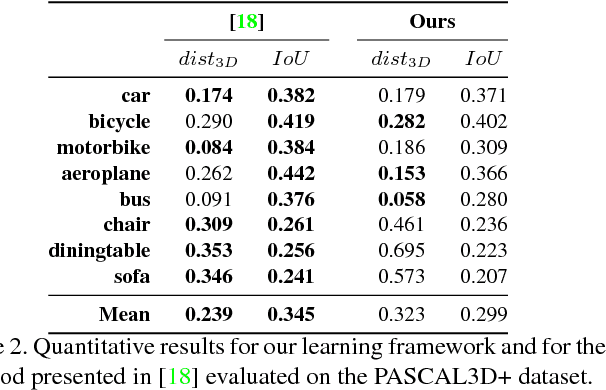
Compact Model Representation for 3D Reconstruction
Jul 23, 2017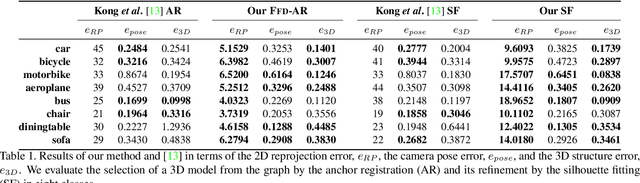
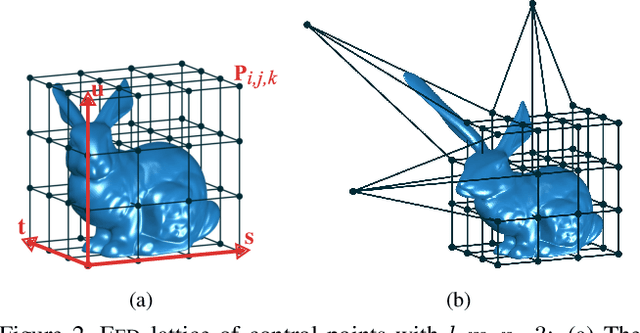
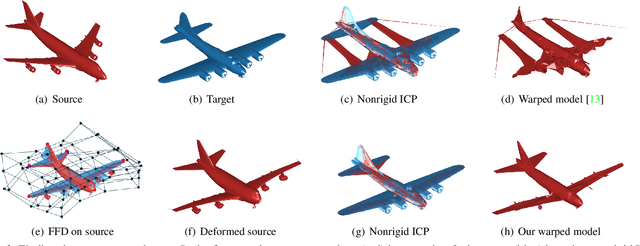

3D reconstruction from 2D images is a central problem in computer vision. Recent works have been focusing on reconstruction directly from a single image. It is well known however that only one image cannot provide enough information for such a reconstruction. A prior knowledge that has been entertained are 3D CAD models due to its online ubiquity. A fundamental question is how to compactly represent millions of CAD models while allowing generalization to new unseen objects with fine-scaled geometry. We introduce an approach to compactly represent a 3D mesh. Our method first selects a 3D model from a graph structure by using a novel free-form deformation FFD 3D-2D registration, and then the selected 3D model is refined to best fit the image silhouette. We perform a comprehensive quantitative and qualitative analysis that demonstrates impressive dense and realistic 3D reconstruction from single images.