 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERF: Explicit Radiance Field Reconstruction From Scratch
Feb 28, 2022

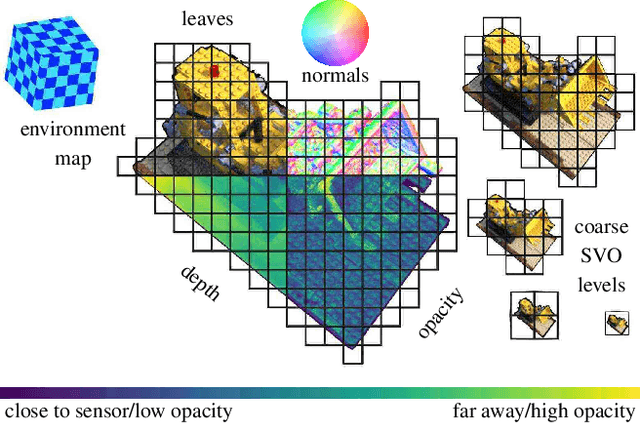

We propose a novel explicit dense 3D reconstruction approach that processes a set of images of a scene with sensor poses and calibrations and estimates a photo-real digital model. One of the key innovations is that the underlying volumetric representation is completely explicit in contrast to neural network-based (implicit) alternatives. We encode scenes explicitly using clear and understandable mappings of optimization variables to scene geometry and their outgoing surface radiance. We represent them using hierarchical volumetric fields stored in a sparse voxel octree. Robustly reconstructing such a volumetric scene model with millions of unknown variables from registered scene images only is a highly non-convex and complex optimization problem. To this end, we employ stochastic gradient descent (Adam) which is steered by an inverse differentiable renderer. We demonstrate that our method can reconstruct models of high quality that are comparable to state-of-the-art implicit methods. Importantly, we do not use a sequential reconstruction pipeline where individual steps suffer from incomplete or unreliable information from previous stages, but start our optimizations from uniformed initial solutions with scene geometry and radiance that is far off from the ground truth. We show that our method is general and practical. It does not require a highly controlled lab setup for capturing, but allows for reconstructing scenes with a vast variety of objects, including challenging ones, such as outdoor plants or furry toys. Finally, our reconstructed scene models are versatile thanks to their explicit design. They can be edited interactively which is computationally too costly for implicit alternatives.
Identity-Disentangled Neural Deformation Model for Dynamic Meshes
Oct 04, 2021
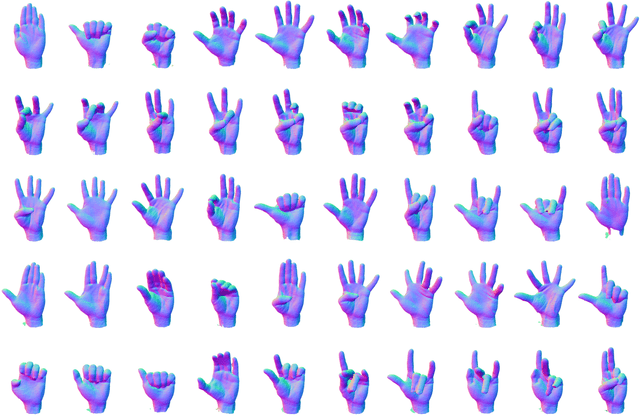


Neural shape models can represent complex 3D shapes with a compact latent space. When applied to dynamically deforming shapes such as the human hands, however, they would need to preserve temporal coherence of the deformation as well as the intrinsic identity of the subject. These properties are difficult to regularize with manually designed loss functions. In this paper, we learn a neural deformation model that disentangles the identity-induced shape variations from pose-dependent deformations using implicit neural functions. We perform template-free unsupervised learning on 3D scans without explicit mesh correspondence or semantic correspondences of shapes across subjects. We can then apply the learned model to reconstruct partial dynamic 4D scans of novel subjects performing unseen actions. We propose two methods to integrate global pose alignment with our neural deformation model. Experiments demonstrate the efficacy of our method in the disentanglement of identities and pose. Our method also outperforms traditional skeleton-driven models in reconstructing surface details such as palm prints or tendons without limitations from a fixed template.
Neural 3D Video Synthesis
Mar 03, 2021



We propose a novel approach for 3D video synthesis that is able to represent multi-view video recordings of a dynamic real-world scene in a compact, yet expressive representation that enables high-quality view synthesis and motion interpolation. Our approach takes the high quality and compactness of static neural radiance fields in a new direction: to a model-free, dynamic setting. At the core of our approach is a novel time-conditioned neural radiance fields that represents scene dynamics using a set of compact latent codes. To exploit the fact that changes between adjacent frames of a video are typically small and locally consistent, we propose two novel strategies for efficient training of our neural network: 1) An efficient hierarchical training scheme, and 2) an importance sampling strategy that selects the next rays for training based on the temporal variation of the input videos. In combination, these two strategies significantly boost the training speed, lead to fast convergence of the training process, and enable high quality results. Our learned representation is highly compact and able to represent a 10 second 30 FPS multi-view video recording by 18 cameras with a model size of just 28MB. We demonstrate that our method can render high-fidelity wide-angle novel views at over 1K resolution, even for highly complex and dynamic scenes. We perform an extensive qualitative and quantitative evaluation that shows that our approach outperforms the current state of the art. We include additional video and information at: https://neural-3d-video.github.io/
STaR: Self-supervised Tracking and Reconstruction of Rigid Objects in Motion with Neural Rendering
Dec 22, 2020
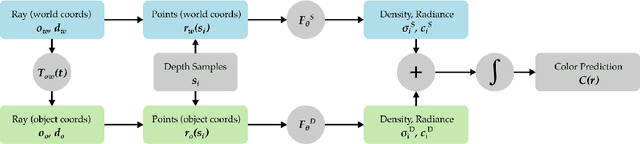
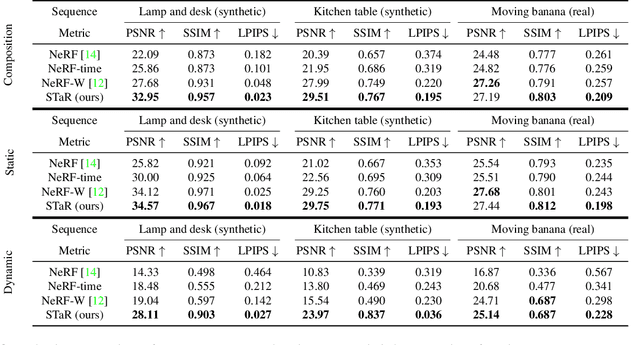
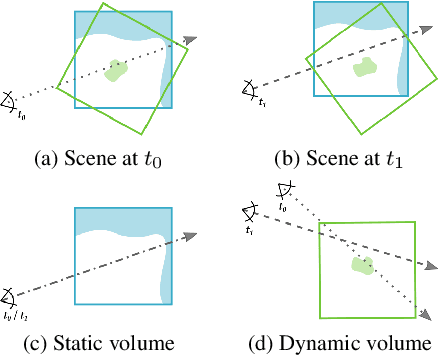
We present STaR, a novel method that performs Self-supervised Tracking and Reconstruction of dynamic scenes with rigid motion from multi-view RGB videos without any manual annotation. Recent work has shown that neural networks are surprisingly effective at the task of compressing many views of a scene into a learned function which maps from a viewing ray to an observed radiance value via volume rendering. Unfortunately, these methods lose all their predictive power once any object in the scene has moved. In this work, we explicitly model rigid motion of objects in the context of neural representations of radiance fields. We show that without any additional human specified supervision, we can reconstruct a dynamic scene with a single rigid object in motion by simultaneously decomposing it into its two constituent parts and encoding each with its own neural representation. We achieve this by jointly optimizing the parameters of two neural radiance fields and a set of rigid poses which align the two fields at each frame. On both synthetic and real world datasets, we demonstrate that our method can render photorealistic novel views, where novelty is measured on both spatial and temporal axes. Our factored representation furthermore enables animation of unseen object motion.
FroDO: From Detections to 3D Objects
May 11, 2020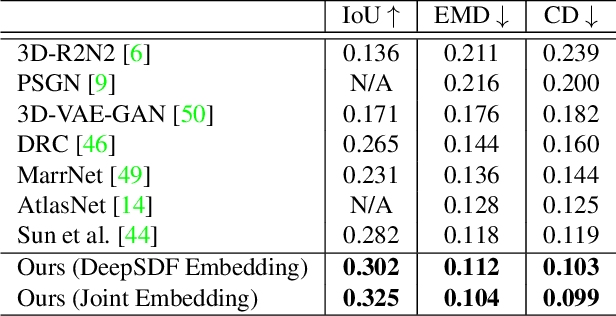


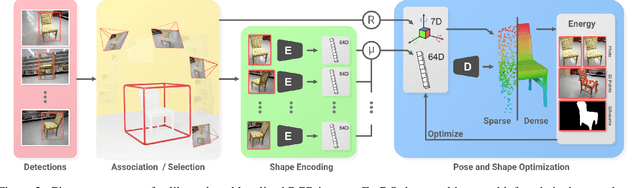
Object-oriented maps are important for scene understanding since they jointly capture geometry and semantics, allow individual instantiation and meaningful reasoning about objects. We introduce FroDO, a method for accurate 3D reconstruction of object instances from RGB video that infers object location, pose and shape in a coarse-to-fine manner. Key to FroDO is to embed object shapes in a novel learnt space that allows seamless switching between sparse point cloud and dense DeepSDF decoding. Given an input sequence of localized RGB frames, FroDO first aggregates 2D detections to instantiate a category-aware 3D bounding box per object. A shape code is regressed using an encoder network before optimizing shape and pose further under the learnt shape priors using sparse and dense shape representations. The optimization uses multi-view geometric, photometric and silhouette losses. We evaluate on real-world datasets, including Pix3D, Redwood-OS, and ScanNet, for single-view, multi-view, and multi-object reconstruction.
Deep Local Shapes: Learning Local SDF Priors for Detailed 3D Reconstruction
Apr 11, 2020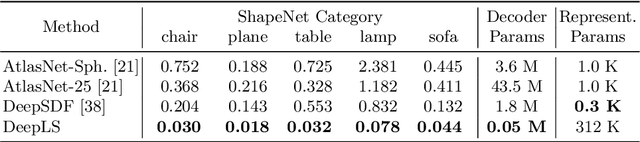
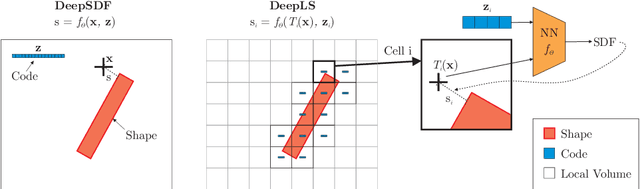

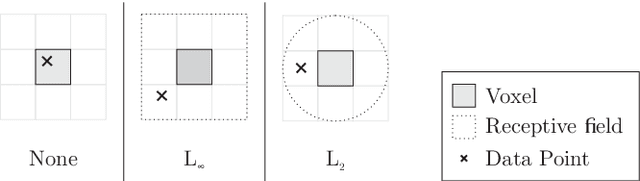
Efficiently reconstructing complex and intricate surfaces at scale is a long-standing goal in machine perception. To address this problem we introduce Deep Local Shapes (DeepLS), a deep shape representation that enables encoding and reconstruction of high-quality 3D shapes without prohibitive memory requirements. DeepLS replaces the dense volumetric signed distance function (SDF) representation used in traditional surface reconstruction systems with a set of locally learned continuous SDFs defined by a neural network, inspired by recent work such as DeepSDF. Unlike DeepSDF, which represents an object-level SDF with a neural network and a single latent code, we store a grid of independent latent codes, each responsible for storing information about surfaces in a small local neighborhood. This decomposition of scenes into local shapes simplifies the prior distribution that the network must learn, and also enables efficient inference. We demonstrate the effectiveness and generalization power of DeepLS by showing object shape encoding and reconstructions of full scenes, where DeepLS delivers high compression, accuracy, and local shape completion.
PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes
May 26, 2018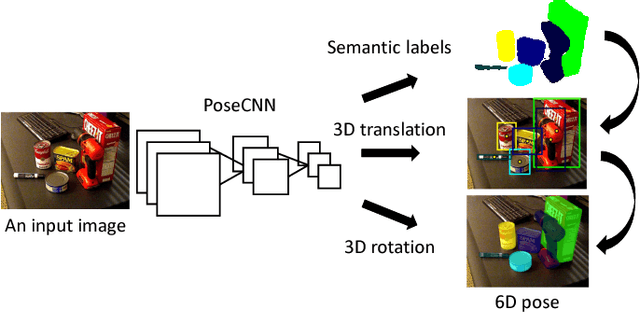
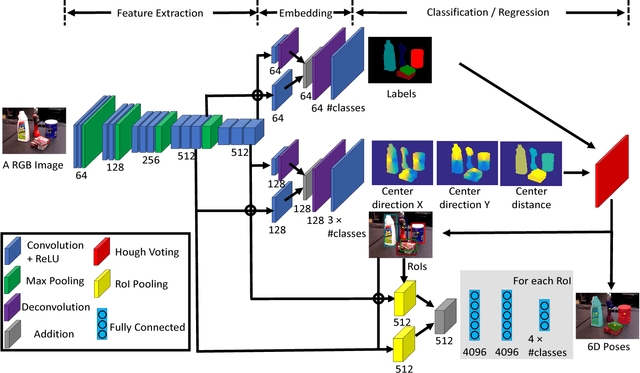
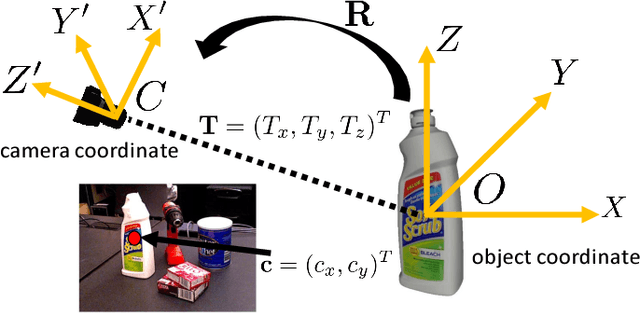
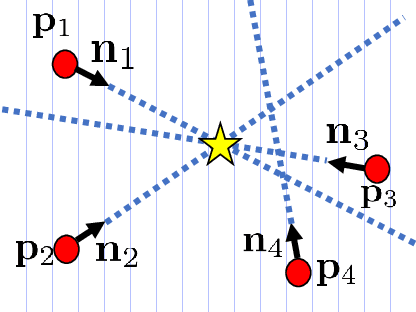
Estimating the 6D pose of known objects is important for robots to interact with the real world. The problem is challenging due to the variety of objects as well as the complexity of a scene caused by clutter and occlusions between objects. In this work, we introduce PoseCNN, a new Convolutional Neural Network for 6D object pose estimation. PoseCNN estimates the 3D translation of an object by localizing its center in the image and predicting its distance from the camera. The 3D rotation of the object is estimated by regressing to a quaternion representation. We also introduce a novel loss function that enables PoseCNN to handle symmetric objects. In addition, we contribute a large scale video dataset for 6D object pose estimation named the YCB-Video dataset. Our dataset provides accurate 6D poses of 21 objects from the YCB dataset observed in 92 videos with 133,827 frames. We conduct extensive experiments on our YCB-Video dataset and the OccludedLINEMOD dataset to show that PoseCNN is highly robust to occlusions, can handle symmetric objects, and provide accurate pose estimation using only color images as input. When using depth data to further refine the poses, our approach achieves state-of-the-art results on the challenging OccludedLINEMOD dataset. Our code and dataset are available at https://rse-lab.cs.washington.edu/projects/posecnn/.
Dynamic High Resolution Deformable Articulated Tracking
Nov 21, 2017

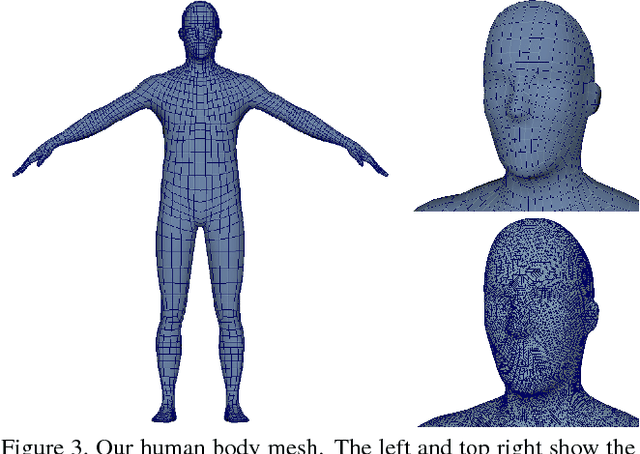
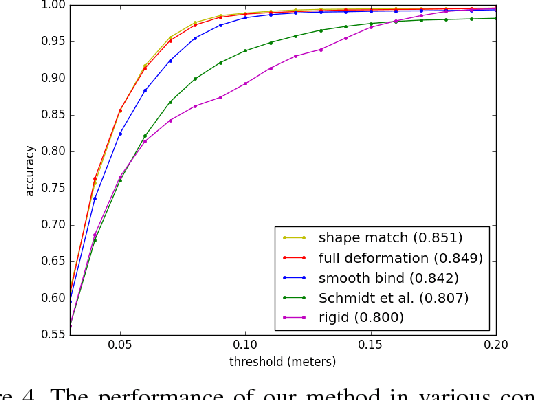
The last several years have seen significant progress in using depth cameras for tracking articulated objects such as human bodies, hands, and robotic manipulators. Most approaches focus on tracking skeletal parameters of a fixed shape model, which makes them insufficient for applications that require accurate estimates of deformable object surfaces. To overcome this limitation, we present a 3D model-based tracking system for articulated deformable objects. Our system is able to track human body pose and high resolution surface contours in real time using a commodity depth sensor and GPU hardware. We implement this as a joint optimization over a skeleton to account for changes in pose, and over the vertices of a high resolution mesh to track the subject's shape. Through experimental results we show that we are able to capture dynamic sub-centimeter surface detail such as folds and wrinkles in clothing. We also show that this shape estimation aids kinematic pose estimation by providing a more accurate target to match against the point cloud. The end result is highly accurate spatiotemporal and semantic information which is well suited for physical human robot interaction as well as virtual and augmented reality systems.