 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImaging for All-Day Wearable Smart Glasses
Apr 17, 2025In recent years smart glasses technology has rapidly advanced, opening up entirely new areas for mobile computing. We expect future smart glasses will need to be all-day wearable, adopting a small form factor to meet the requirements of volume, weight, fashionability and social acceptability, which puts significant constraints on the space of possible solutions. Additional challenges arise due to the fact that smart glasses are worn in arbitrary environments while their wearer moves and performs everyday activities. In this paper, we systematically analyze the space of imaging from smart glasses and derive several fundamental limits that govern this imaging domain. We discuss the impact of these limits on achievable image quality and camera module size -- comparing in particular to related devices such as mobile phones. We then propose a novel distributed imaging approach that allows to minimize the size of the individual camera modules when compared to a standard monolithic camera design. Finally, we demonstrate the properties of this novel approach in a series of experiments using synthetic data as well as images captured with two different prototype implementations.
Volumetric Primitives for Modeling and Rendering Scattering and Emissive Media
May 24, 2024



We propose a volumetric representation based on primitives to model scattering and emissive media. Accurate scene representations enabling efficient rendering are essential for many computer graphics applications. General and unified representations that can handle surface and volume-based representations simultaneously, allowing for physically accurate modeling, remain a research challenge. Inspired by recent methods for scene reconstruction that leverage mixtures of 3D Gaussians to model radiance fields, we formalize and generalize the modeling of scattering and emissive media using mixtures of simple kernel-based volumetric primitives. We introduce closed-form solutions for transmittance and free-flight distance sampling for 3D Gaussian kernels, and propose several optimizations to use our method efficiently within any off-the-shelf volumetric path tracer by leveraging ray tracing for efficiently querying the medium. We demonstrate our method as an alternative to other forms of volume modeling (e.g. voxel grid-based representations) for forward and inverse rendering of scattering media. Furthermore, we adapt our method to the problem of radiance field optimization and rendering, and demonstrate comparable performance to the state of the art, while providing additional flexibility in terms of performance and usability.
EgoLifter: Open-world 3D Segmentation for Egocentric Perception
Mar 26, 2024In this paper we present EgoLifter, a novel system that can automatically segment scenes captured from egocentric sensors into a complete decomposition of individual 3D objects. The system is specifically designed for egocentric data where scenes contain hundreds of objects captured from natural (non-scanning) motion. EgoLifter adopts 3D Gaussians as the underlying representation of 3D scenes and objects and uses segmentation masks from the Segment Anything Model (SAM) as weak supervision to learn flexible and promptable definitions of object instances free of any specific object taxonomy. To handle the challenge of dynamic objects in ego-centric videos, we design a transient prediction module that learns to filter out dynamic objects in the 3D reconstruction. The result is a fully automatic pipeline that is able to reconstruct 3D object instances as collections of 3D Gaussians that collectively compose the entire scene. We created a new benchmark on the Aria Digital Twin dataset that quantitatively demonstrates its state-of-the-art performance in open-world 3D segmentation from natural egocentric input. We run EgoLifter on various egocentric activity datasets which shows the promise of the method for 3D egocentric perception at scale.
Recurrent Video Restoration Transformer with Guided Deformable Attention
Jun 05, 2022
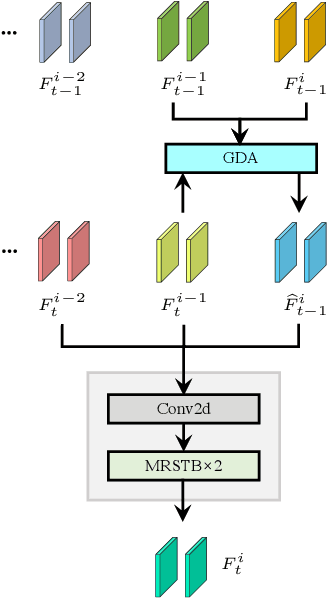
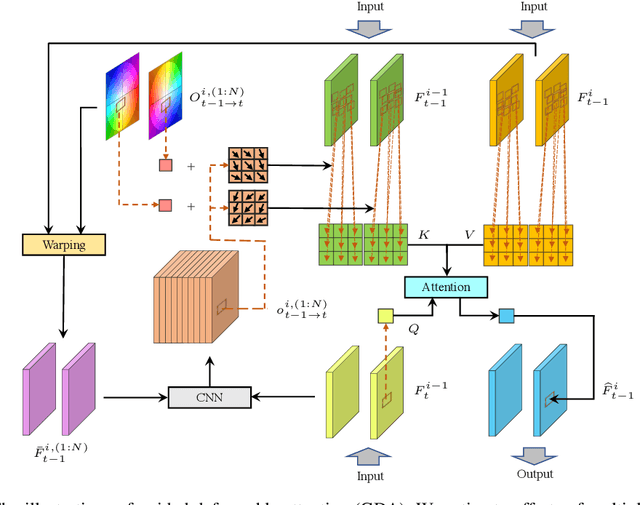
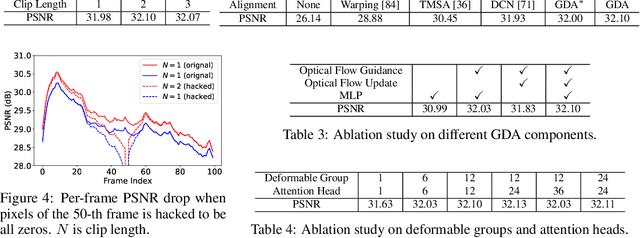
Video restoration aims at restoring multiple high-quality frames from multiple low-quality frames. Existing video restoration methods generally fall into two extreme cases, i.e., they either restore all frames in parallel or restore the video frame by frame in a recurrent way, which would result in different merits and drawbacks. Typically, the former has the advantage of temporal information fusion. However, it suffers from large model size and intensive memory consumption; the latter has a relatively small model size as it shares parameters across frames; however, it lacks long-range dependency modeling ability and parallelizability. In this paper, we attempt to integrate the advantages of the two cases by proposing a recurrent video restoration transformer, namely RVRT. RVRT processes local neighboring frames in parallel within a globally recurrent framework which can achieve a good trade-off between model size, effectiveness, and efficiency. Specifically, RVRT divides the video into multiple clips and uses the previously inferred clip feature to estimate the subsequent clip feature. Within each clip, different frame features are jointly updated with implicit feature aggregation. Across different clips, the guided deformable attention is designed for clip-to-clip alignment, which predicts multiple relevant locations from the whole inferred clip and aggregates their features by the attention mechanism. Extensive experiments on video super-resolution, deblurring, and denoising show that the proposed RVRT achieves state-of-the-art performance on benchmark datasets with balanced model size, testing memory and runtime.
Neural 3D Video Synthesis
Mar 03, 2021



We propose a novel approach for 3D video synthesis that is able to represent multi-view video recordings of a dynamic real-world scene in a compact, yet expressive representation that enables high-quality view synthesis and motion interpolation. Our approach takes the high quality and compactness of static neural radiance fields in a new direction: to a model-free, dynamic setting. At the core of our approach is a novel time-conditioned neural radiance fields that represents scene dynamics using a set of compact latent codes. To exploit the fact that changes between adjacent frames of a video are typically small and locally consistent, we propose two novel strategies for efficient training of our neural network: 1) An efficient hierarchical training scheme, and 2) an importance sampling strategy that selects the next rays for training based on the temporal variation of the input videos. In combination, these two strategies significantly boost the training speed, lead to fast convergence of the training process, and enable high quality results. Our learned representation is highly compact and able to represent a 10 second 30 FPS multi-view video recording by 18 cameras with a model size of just 28MB. We demonstrate that our method can render high-fidelity wide-angle novel views at over 1K resolution, even for highly complex and dynamic scenes. We perform an extensive qualitative and quantitative evaluation that shows that our approach outperforms the current state of the art. We include additional video and information at: https://neural-3d-video.github.io/
The Replica Dataset: A Digital Replica of Indoor Spaces
Jun 13, 2019



We introduce Replica, a dataset of 18 highly photo-realistic 3D indoor scene reconstructions at room and building scale. Each scene consists of a dense mesh, high-resolution high-dynamic-range (HDR) textures, per-primitive semantic class and instance information, and planar mirror and glass reflectors. The goal of Replica is to enable machine learning (ML) research that relies on visually, geometrically, and semantically realistic generative models of the world - for instance, egocentric computer vision, semantic segmentation in 2D and 3D, geometric inference, and the development of embodied agents (virtual robots) performing navigation, instruction following, and question answering. Due to the high level of realism of the renderings from Replica, there is hope that ML systems trained on Replica may transfer directly to real world image and video data. Together with the data, we are releasing a minimal C++ SDK as a starting point for working with the Replica dataset. In addition, Replica is `Habitat-compatible', i.e. can be natively used with AI Habitat for training and testing embodied agents.
Psychlab: A Psychology Laboratory for Deep Reinforcement Learning Agents
Feb 04, 2018


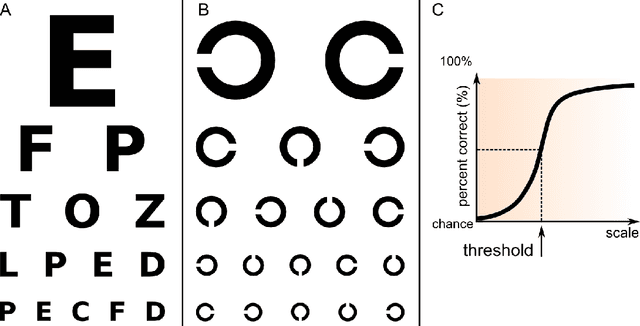
Psychlab is a simulated psychology laboratory inside the first-person 3D game world of DeepMind Lab (Beattie et al. 2016). Psychlab enables implementations of classical laboratory psychological experiments so that they work with both human and artificial agents. Psychlab has a simple and flexible API that enables users to easily create their own tasks. As examples, we are releasing Psychlab implementations of several classical experimental paradigms including visual search, change detection, random dot motion discrimination, and multiple object tracking. We also contribute a study of the visual psychophysics of a specific state-of-the-art deep reinforcement learning agent: UNREAL (Jaderberg et al. 2016). This study leads to the surprising conclusion that UNREAL learns more quickly about larger target stimuli than it does about smaller stimuli. In turn, this insight motivates a specific improvement in the form of a simple model of foveal vision that turns out to significantly boost UNREAL's performance, both on Psychlab tasks, and on standard DeepMind Lab tasks. By open-sourcing Psychlab we hope to facilitate a range of future such studies that simultaneously advance deep reinforcement learning and improve its links with cognitive science.
Grounded Language Learning in a Simulated 3D World
Jun 26, 2017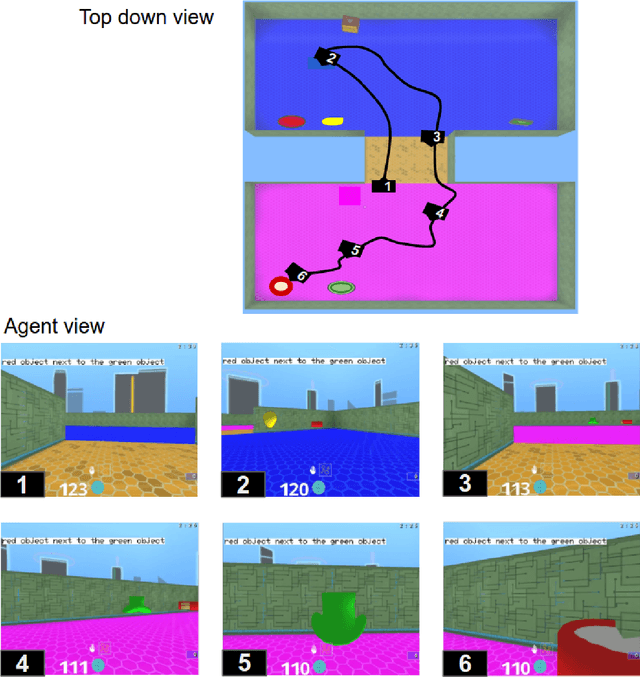

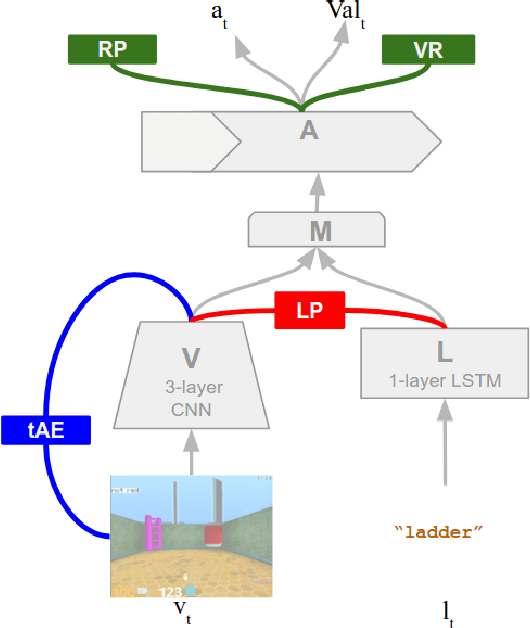
We are increasingly surrounded by artificially intelligent technology that takes decisions and executes actions on our behalf. This creates a pressing need for general means to communicate with, instruct and guide artificial agents, with human language the most compelling means for such communication. To achieve this in a scalable fashion, agents must be able to relate language to the world and to actions; that is, their understanding of language must be grounded and embodied. However, learning grounded language is a notoriously challenging problem in artificial intelligence research. Here we present an agent that learns to interpret language in a simulated 3D environment where it is rewarded for the successful execution of written instructions. Trained via a combination of reinforcement and unsupervised learning, and beginning with minimal prior knowledge, the agent learns to relate linguistic symbols to emergent perceptual representations of its physical surroundings and to pertinent sequences of actions. The agent's comprehension of language extends beyond its prior experience, enabling it to apply familiar language to unfamiliar situations and to interpret entirely novel instructions. Moreover, the speed with which this agent learns new words increases as its semantic knowledge grows. This facility for generalising and bootstrapping semantic knowledge indicates the potential of the present approach for reconciling ambiguous natural language with the complexity of the physical world.
DeepMind Lab
Dec 13, 2016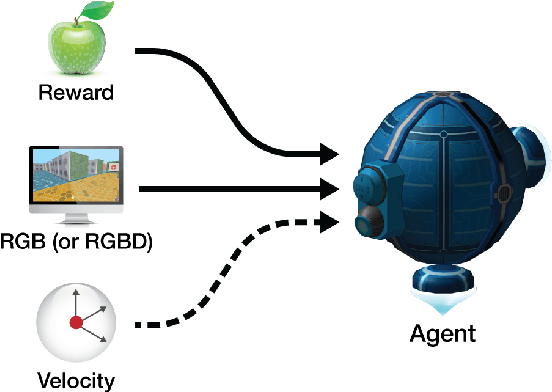
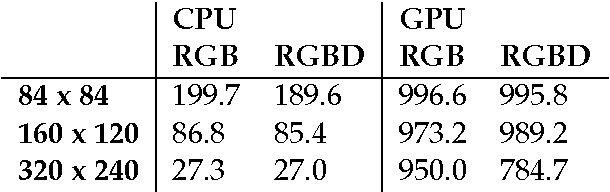
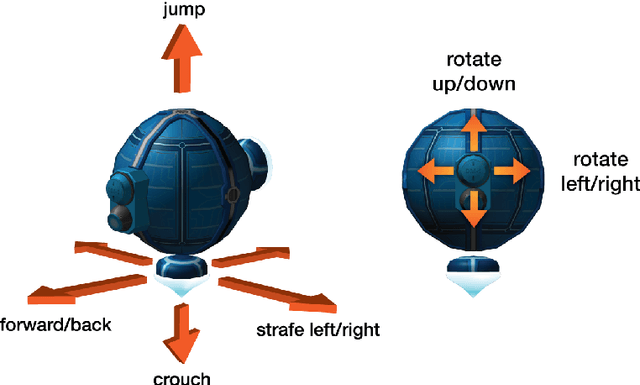

DeepMind Lab is a first-person 3D game platform designed for research and development of general artificial intelligence and machine learning systems. DeepMind Lab can be used to study how autonomous artificial agents may learn complex tasks in large, partially observed, and visually diverse worlds. DeepMind Lab has a simple and flexible API enabling creative task-designs and novel AI-designs to be explored and quickly iterated upon. It is powered by a fast and widely recognised game engine, and tailored for effective use by the research community.