 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiplicative-Additive Constrained Models:Toward Joint Visualization of Interactive and Independent Effects
Sep 26, 2025Interpretability is one of the considerations when applying machine learning to high-stakes fields such as healthcare that involve matters of life safety. Generalized Additive Models (GAMs) enhance interpretability by visualizing shape functions. Nevertheless, to preserve interpretability, GAMs omit higher-order interaction effects (beyond pairwise interactions), which imposes significant constraints on their predictive performance. We observe that Curve Ergodic Set Regression (CESR), a multiplicative model, naturally enables the visualization of its shape functions and simultaneously incorporates both interactions among all features and individual feature effects. Nevertheless, CESR fails to demonstrate superior performance compared to GAMs. We introduce Multiplicative-Additive Constrained Models (MACMs), which augment CESR with an additive part to disentangle the intertwined coefficients of its interactive and independent terms, thus effectively broadening the hypothesis space. The model is composed of a multiplicative part and an additive part, whose shape functions can both be naturally visualized, thereby assisting users in interpreting how features participate in the decision-making process. Consequently, MACMs constitute an improvement over both CESR and GAMs. The experimental results indicate that neural network-based MACMs significantly outperform both CESR and the current state-of-the-art GAMs in terms of predictive performance.
Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards
Oct 08, 2018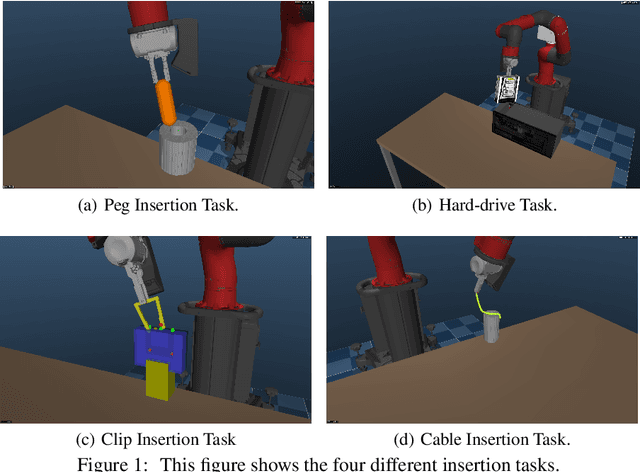

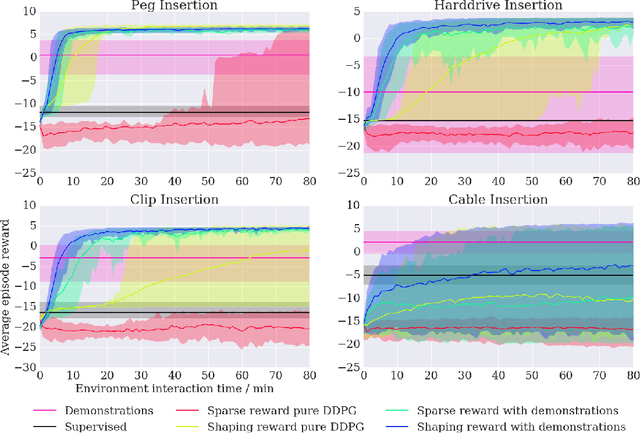
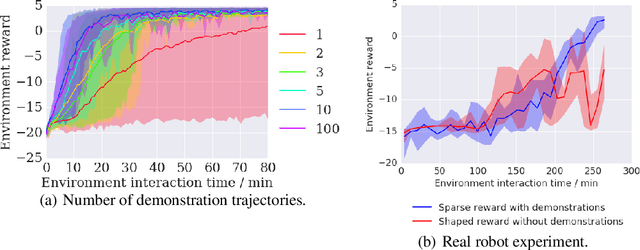
We propose a general and model-free approach for Reinforcement Learning (RL) on real robotics with sparse rewards. We build upon the Deep Deterministic Policy Gradient (DDPG) algorithm to use demonstrations. Both demonstrations and actual interactions are used to fill a replay buffer and the sampling ratio between demonstrations and transitions is automatically tuned via a prioritized replay mechanism. Typically, carefully engineered shaping rewards are required to enable the agents to efficiently explore on high dimensional control problems such as robotics. They are also required for model-based acceleration methods relying on local solvers such as iLQG (e.g. Guided Policy Search and Normalized Advantage Function). The demonstrations replace the need for carefully engineered rewards, and reduce the exploration problem encountered by classical RL approaches in these domains. Demonstrations are collected by a robot kinesthetically force-controlled by a human demonstrator. Results on four simulated insertion tasks show that DDPG from demonstrations out-performs DDPG, and does not require engineered rewards. Finally, we demonstrate the method on a real robotics task consisting of inserting a clip (flexible object) into a rigid object.
Grounded Language Learning in a Simulated 3D World
Jun 26, 2017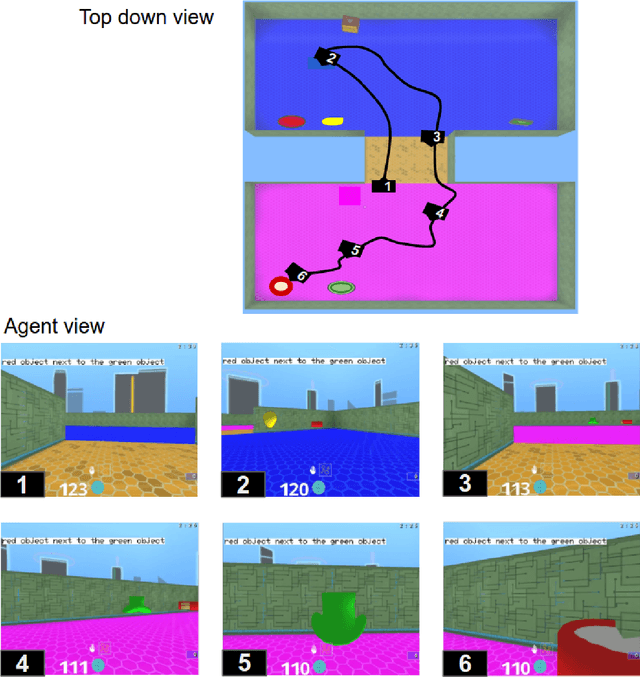

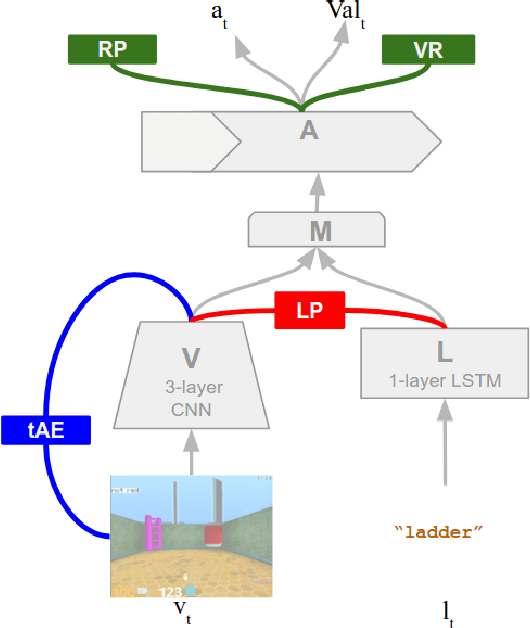
We are increasingly surrounded by artificially intelligent technology that takes decisions and executes actions on our behalf. This creates a pressing need for general means to communicate with, instruct and guide artificial agents, with human language the most compelling means for such communication. To achieve this in a scalable fashion, agents must be able to relate language to the world and to actions; that is, their understanding of language must be grounded and embodied. However, learning grounded language is a notoriously challenging problem in artificial intelligence research. Here we present an agent that learns to interpret language in a simulated 3D environment where it is rewarded for the successful execution of written instructions. Trained via a combination of reinforcement and unsupervised learning, and beginning with minimal prior knowledge, the agent learns to relate linguistic symbols to emergent perceptual representations of its physical surroundings and to pertinent sequences of actions. The agent's comprehension of language extends beyond its prior experience, enabling it to apply familiar language to unfamiliar situations and to interpret entirely novel instructions. Moreover, the speed with which this agent learns new words increases as its semantic knowledge grows. This facility for generalising and bootstrapping semantic knowledge indicates the potential of the present approach for reconciling ambiguous natural language with the complexity of the physical world.
Latent Predictor Networks for Code Generation
Jun 08, 2016
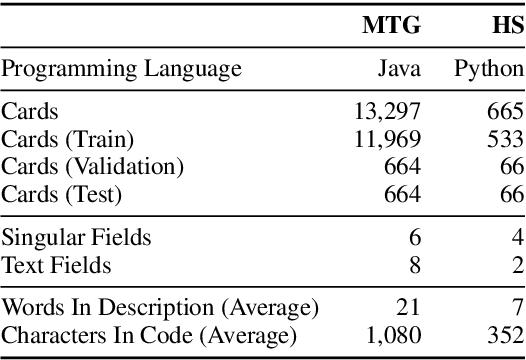


Many language generation tasks require the production of text conditioned on both structured and unstructured inputs. We present a novel neural network architecture which generates an output sequence conditioned on an arbitrary number of input functions. Crucially, our approach allows both the choice of conditioning context and the granularity of generation, for example characters or tokens, to be marginalised, thus permitting scalable and effective training. Using this framework, we address the problem of generating programming code from a mixed natural language and structured specification. We create two new data sets for this paradigm derived from the collectible trading card games Magic the Gathering and Hearthstone. On these, and a third preexisting corpus, we demonstrate that marginalising multiple predictors allows our model to outperform strong benchmarks.