 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Improvement Rate Population Based Training
Sep 28, 2021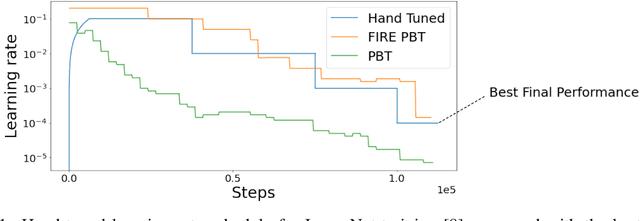
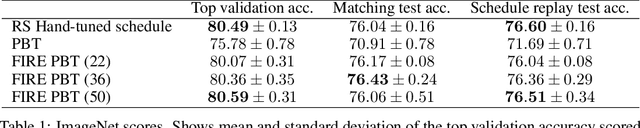
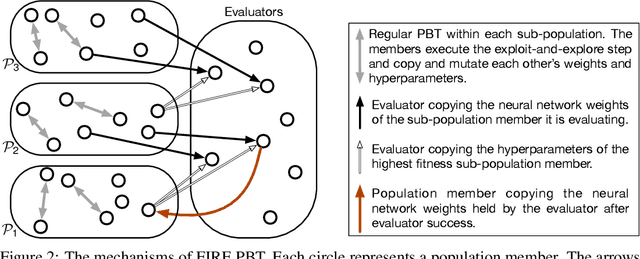
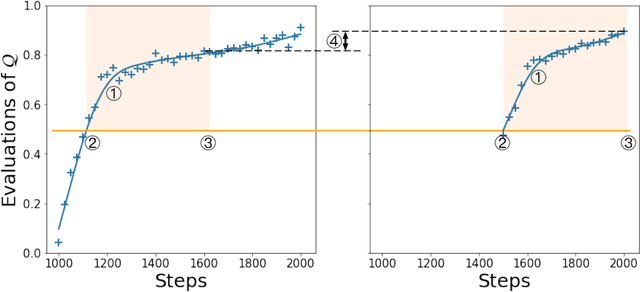
The successful training of neural networks typically involves careful and time consuming hyperparameter tuning. Population Based Training (PBT) has recently been proposed to automate this process. PBT trains a population of neural networks concurrently, frequently mutating their hyperparameters throughout their training. However, the decision mechanisms of PBT are greedy and favour short-term improvements which can, in some cases, lead to poor long-term performance. This paper presents Faster Improvement Rate PBT (FIRE PBT) which addresses this problem. Our method is guided by an assumption: given two neural networks with similar performance and training with similar hyperparameters, the network showing the faster rate of improvement will lead to a better final performance. Using this, we derive a novel fitness metric and use it to make some of the population members focus on long-term performance. Our experiments show that FIRE PBT is able to outperform PBT on the ImageNet benchmark and match the performance of networks that were trained with a hand-tuned learning rate schedule. We apply FIRE PBT to reinforcement learning tasks and show that it leads to faster learning and higher final performance than both PBT and random hyperparameter search.
Open-Ended Learning Leads to Generally Capable Agents
Jul 31, 2021
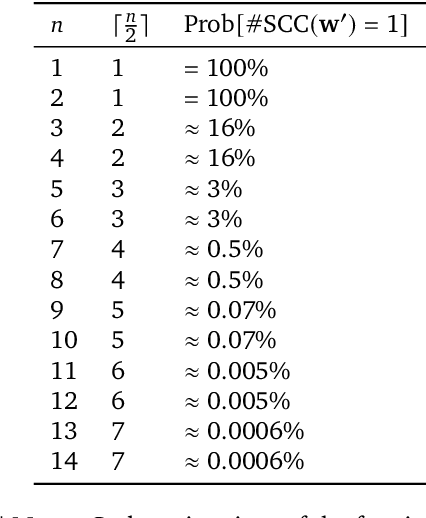
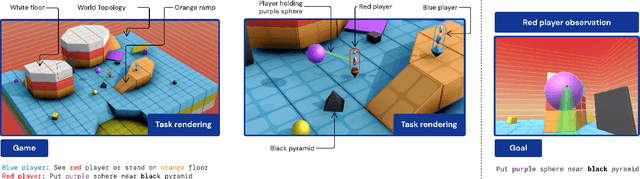

In this work we create agents that can perform well beyond a single, individual task, that exhibit much wider generalisation of behaviour to a massive, rich space of challenges. We define a universe of tasks within an environment domain and demonstrate the ability to train agents that are generally capable across this vast space and beyond. The environment is natively multi-agent, spanning the continuum of competitive, cooperative, and independent games, which are situated within procedurally generated physical 3D worlds. The resulting space is exceptionally diverse in terms of the challenges posed to agents, and as such, even measuring the learning progress of an agent is an open research problem. We propose an iterative notion of improvement between successive generations of agents, rather than seeking to maximise a singular objective, allowing us to quantify progress despite tasks being incomparable in terms of achievable rewards. We show that through constructing an open-ended learning process, which dynamically changes the training task distributions and training objectives such that the agent never stops learning, we achieve consistent learning of new behaviours. The resulting agent is able to score reward in every one of our humanly solvable evaluation levels, with behaviour generalising to many held-out points in the universe of tasks. Examples of this zero-shot generalisation include good performance on Hide and Seek, Capture the Flag, and Tag. Through analysis and hand-authored probe tasks we characterise the behaviour of our agent, and find interesting emergent heuristic behaviours such as trial-and-error experimentation, simple tool use, option switching, and cooperation. Finally, we demonstrate that the general capabilities of this agent could unlock larger scale transfer of behaviour through cheap finetuning.
Perception-Prediction-Reaction Agents for Deep Reinforcement Learning
Jun 26, 2020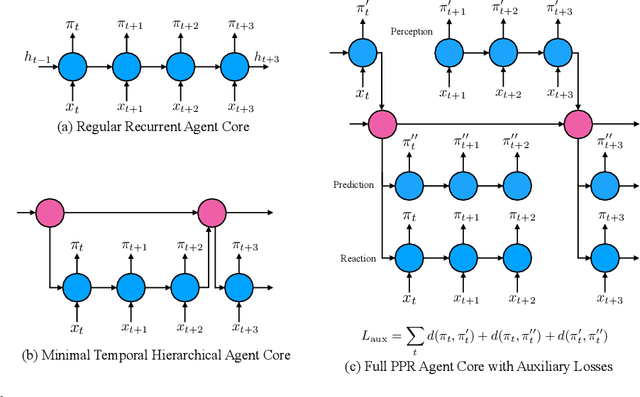

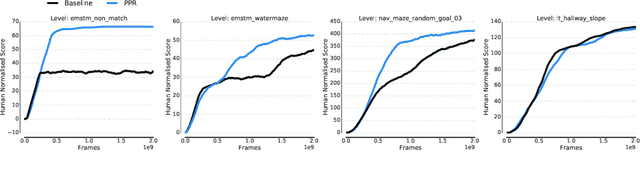
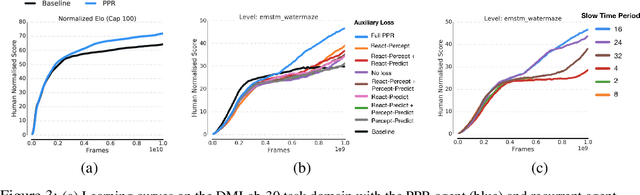
We introduce a new recurrent agent architecture and associated auxiliary losses which improve reinforcement learning in partially observable tasks requiring long-term memory. We employ a temporal hierarchy, using a slow-ticking recurrent core to allow information to flow more easily over long time spans, and three fast-ticking recurrent cores with connections designed to create an information asymmetry. The \emph{reaction} core incorporates new observations with input from the slow core to produce the agent's policy; the \emph{perception} core accesses only short-term observations and informs the slow core; lastly, the \emph{prediction} core accesses only long-term memory. An auxiliary loss regularizes policies drawn from all three cores against each other, enacting the prior that the policy should be expressible from either recent or long-term memory. We present the resulting \emph{Perception-Prediction-Reaction} (PPR) agent and demonstrate its improved performance over a strong LSTM-agent baseline in DMLab-30, particularly in tasks requiring long-term memory. We further show significant improvements in Capture the Flag, an environment requiring agents to acquire a complicated mixture of skills over long time scales. In a series of ablation experiments, we probe the importance of each component of the PPR agent, establishing that the entire, novel combination is necessary for this intriguing result.
Real World Games Look Like Spinning Tops
Apr 20, 2020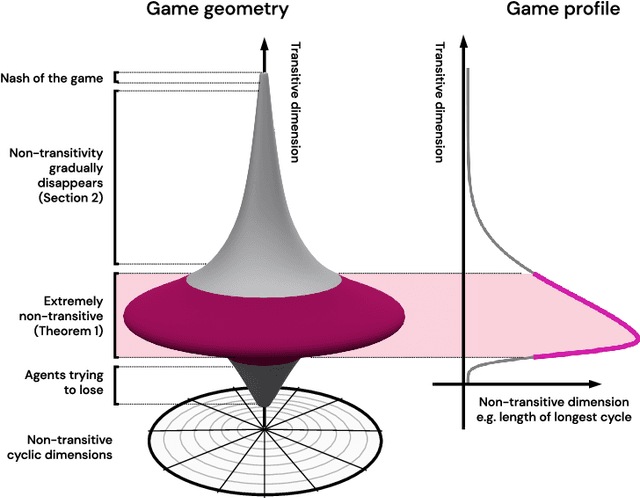
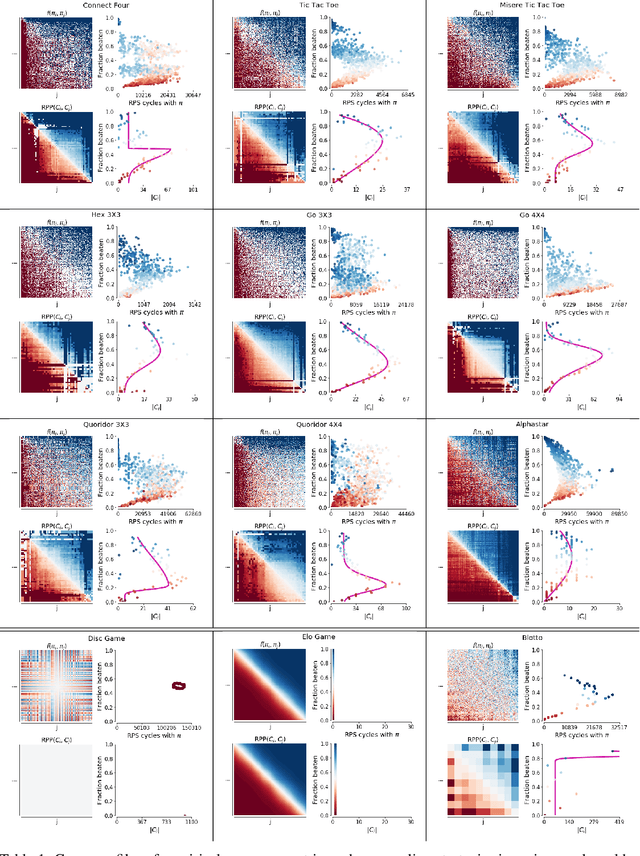
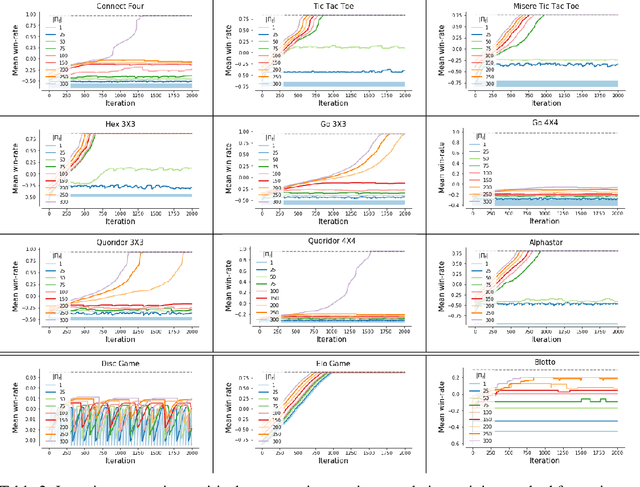
This paper investigates the geometrical properties of real world games (e.g. Tic-Tac-Toe, Go, StarCraft II). We hypothesise that their geometrical structure resemble a spinning top, with the upright axis representing transitive strength, and the radial axis, which corresponds to the number of cycles that exist at a particular transitive strength, representing the non-transitive dimension. We prove the existence of this geometry for a wide class of real world games, exposing their temporal nature. Additionally, we show that this unique structure also has consequences for learning - it clarifies why populations of strategies are necessary for training of agents, and how population size relates to the structure of the game. Finally, we empirically validate these claims by using a selection of nine real world two-player zero-sum symmetric games, showing 1) the spinning top structure is revealed and can be easily re-constructed by using a new method of Nash clustering to measure the interaction between transitive and cyclical strategy behaviour, and 2) the effect that population size has on the convergence in these games.
A Deep Neural Network's Loss Surface Contains Every Low-dimensional Pattern
Jan 02, 2020



The work "Loss Landscape Sightseeing with Multi-Point Optimization" (Skorokhodov and Burtsev, 2019) demonstrated that one can empirically find arbitrary 2D binary patterns inside loss surfaces of popular neural networks. In this paper we prove that: (i) this is a general property of deep universal approximators; and (ii) this property holds for arbitrary smooth patterns, for other dimensionalities, for every dataset, and any neural network that is sufficiently deep and wide. Our analysis predicts not only the existence of all such low-dimensional patterns, but also two other properties that were observed empirically: (i) that it is easy to find these patterns; and (ii) that they transfer to other data-sets (e.g. a test-set).
Stabilizing Transformers for Reinforcement Learning
Oct 13, 2019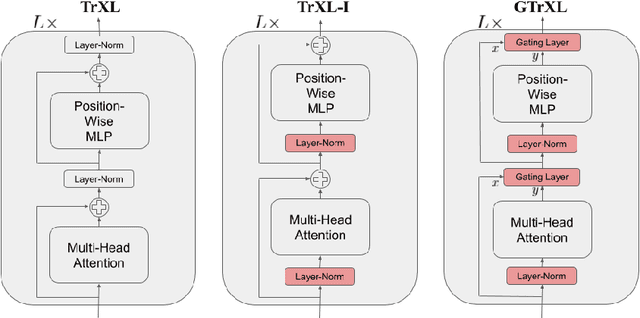
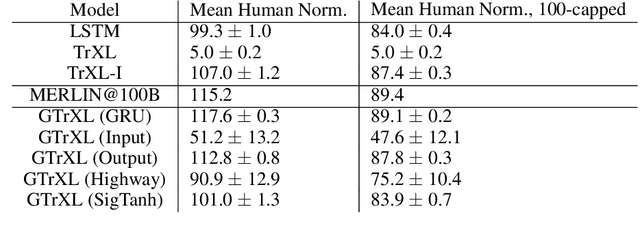
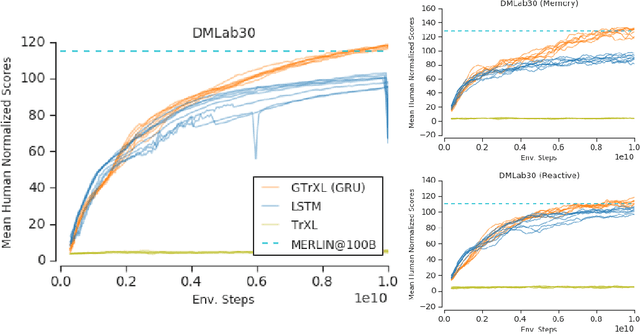
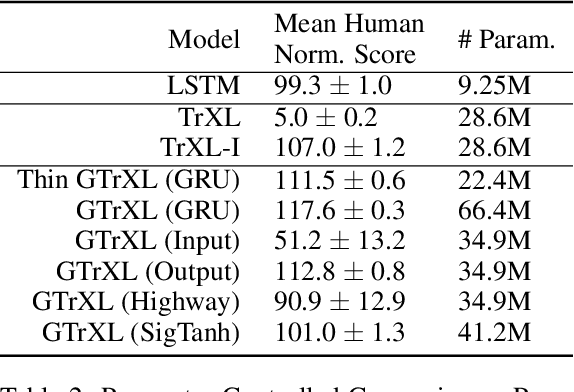
Owing to their ability to both effectively integrate information over long time horizons and scale to massive amounts of data, self-attention architectures have recently shown breakthrough success in natural language processing (NLP), achieving state-of-the-art results in domains such as language modeling and machine translation. Harnessing the transformer's ability to process long time horizons of information could provide a similar performance boost in partially observable reinforcement learning (RL) domains, but the large-scale transformers used in NLP have yet to be successfully applied to the RL setting. In this work we demonstrate that the standard transformer architecture is difficult to optimize, which was previously observed in the supervised learning setting but becomes especially pronounced with RL objectives. We propose architectural modifications that substantially improve the stability and learning speed of the original Transformer and XL variant. The proposed architecture, the Gated Transformer-XL (GTrXL), surpasses LSTMs on challenging memory environments and achieves state-of-the-art results on the multi-task DMLab-30 benchmark suite, exceeding the performance of an external memory architecture. We show that the GTrXL, trained using the same losses, has stability and performance that consistently matches or exceeds a competitive LSTM baseline, including on more reactive tasks where memory is less critical. GTrXL offers an easy-to-train, simple-to-implement but substantially more expressive architectural alternative to the standard multi-layer LSTM ubiquitously used for RL agents in partially observable environments.
Distilling Policy Distillation
Feb 06, 2019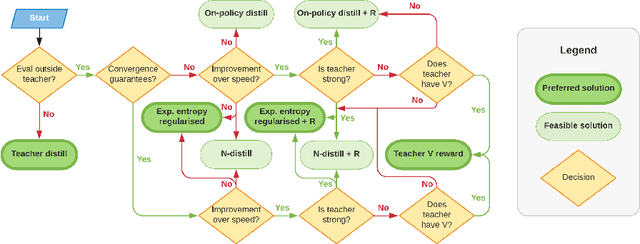


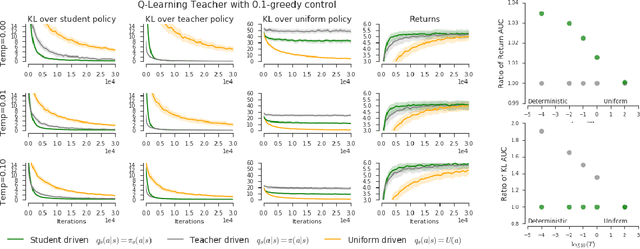
The transfer of knowledge from one policy to another is an important tool in Deep Reinforcement Learning. This process, referred to as distillation, has been used to great success, for example, by enhancing the optimisation of agents, leading to stronger performance faster, on harder domains [26, 32, 5, 8]. Despite the widespread use and conceptual simplicity of distillation, many different formulations are used in practice, and the subtle variations between them can often drastically change the performance and the resulting objective that is being optimised. In this work, we rigorously explore the entire landscape of policy distillation, comparing the motivations and strengths of each variant through theoretical and empirical analysis. Our results point to three distillation techniques, that are preferred depending on specifics of the task. Specifically a newly proposed expected entropy regularised distillation allows for quicker learning in a wide range of situations, while still guaranteeing convergence.
A Generalized Framework for Population Based Training
Feb 05, 2019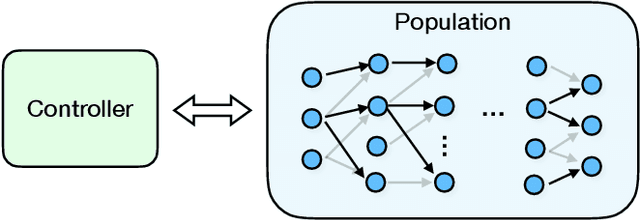
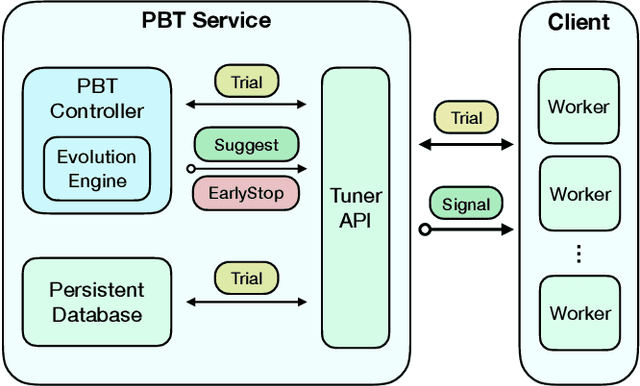

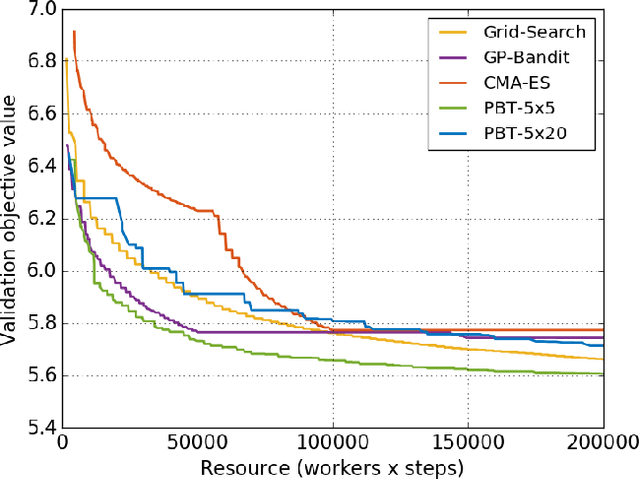
Population Based Training (PBT) is a recent approach that jointly optimizes neural network weights and hyperparameters which periodically copies weights of the best performers and mutates hyperparameters during training. Previous PBT implementations have been synchronized glass-box systems. We propose a general, black-box PBT framework that distributes many asynchronous "trials" (a small number of training steps with warm-starting) across a cluster, coordinated by the PBT controller. The black-box design does not make assumptions on model architectures, loss functions or training procedures. Our system supports dynamic hyperparameter schedules to optimize both differentiable and non-differentiable metrics. We apply our system to train a state-of-the-art WaveNet generative model for human voice synthesis. We show that our PBT system achieves better accuracy, less sensitivity and faster convergence compared to existing methods, given the same computational resource.
Open-ended Learning in Symmetric Zero-sum Games
Jan 23, 2019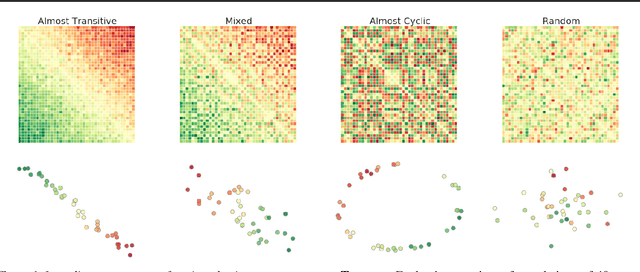
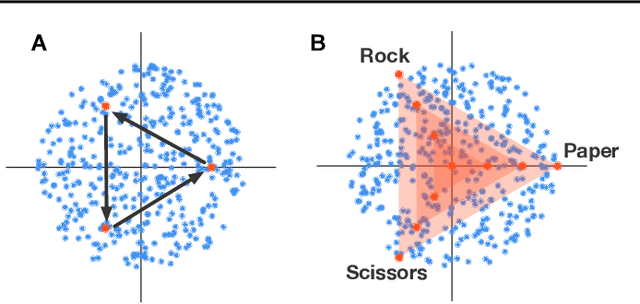

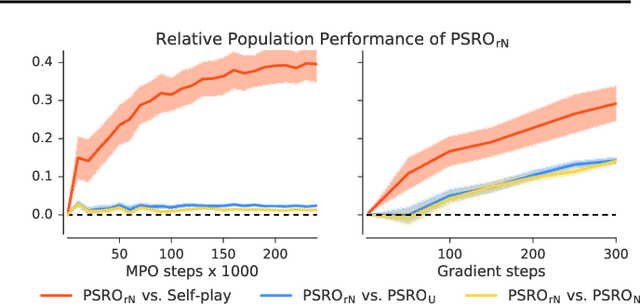
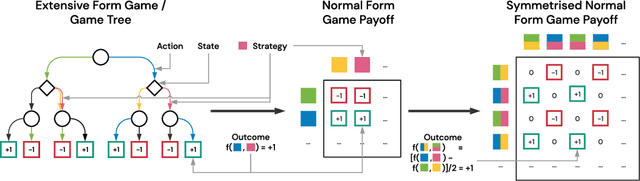
Zero-sum games such as chess and poker are, abstractly, functions that evaluate pairs of agents, for example labeling them `winner' and `loser'. If the game is approximately transitive, then self-play generates sequences of agents of increasing strength. However, nontransitive games, such as rock-paper-scissors, can exhibit strategic cycles, and there is no longer a clear objective -- we want agents to increase in strength, but against whom is unclear. In this paper, we introduce a geometric framework for formulating agent objectives in zero-sum games, in order to construct adaptive sequences of objectives that yield open-ended learning. The framework allows us to reason about population performance in nontransitive games, and enables the development of a new algorithm (rectified Nash response, PSRO_rN) that uses game-theoretic niching to construct diverse populations of effective agents, producing a stronger set of agents than existing algorithms. We apply PSRO_rN to two highly nontransitive resource allocation games and find that PSRO_rN consistently outperforms the existing alternatives.
Human-level performance in first-person multiplayer games with population-based deep reinforcement learning
Jul 03, 2018Recent progress in artificial intelligence through reinforcement learning (RL) has shown great success on increasingly complex single-agent environments and two-player turn-based games. However, the real-world contains multiple agents, each learning and acting independently to cooperate and compete with other agents, and environments reflecting this degree of complexity remain an open challenge. In this work, we demonstrate for the first time that an agent can achieve human-level in a popular 3D multiplayer first-person video game, Quake III Arena Capture the Flag, using only pixels and game points as input. These results were achieved by a novel two-tier optimisation process in which a population of independent RL agents are trained concurrently from thousands of parallel matches with agents playing in teams together and against each other on randomly generated environments. Each agent in the population learns its own internal reward signal to complement the sparse delayed reward from winning, and selects actions using a novel temporally hierarchical representation that enables the agent to reason at multiple timescales. During game-play, these agents display human-like behaviours such as navigating, following, and defending based on a rich learned representation that is shown to encode high-level game knowledge. In an extensive tournament-style evaluation the trained agents exceeded the win-rate of strong human players both as teammates and opponents, and proved far stronger than existing state-of-the-art agents. These results demonstrate a significant jump in the capabilities of artificial agents, bringing us closer to the goal of human-level intelligence.