 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Space of Key-Value-Query Models with Intention
May 17, 2023Attention-based models have been a key element of many recent breakthroughs in deep learning. Two key components of Attention are the structure of its input (which consists of keys, values and queries) and the computations by which these three are combined. In this paper we explore the space of models that share said input structure but are not restricted to the computations of Attention. We refer to this space as Keys-Values-Queries (KVQ) Space. Our goal is to determine whether there are any other stackable models in KVQ Space that Attention cannot efficiently approximate, which we can implement with our current deep learning toolbox and that solve problems that are interesting to the community. Maybe surprisingly, the solution to the standard least squares problem satisfies these properties. A neural network module that is able to compute this solution not only enriches the set of computations that a neural network can represent but is also provably a strict generalisation of Linear Attention. Even more surprisingly the computational complexity of this module is exactly the same as that of Attention, making it a suitable drop in replacement. With this novel connection between classical machine learning (least squares) and modern deep learning (Attention) established we justify a variation of our model which generalises regular Attention in the same way. Both new modules are put to the test an a wide spectrum of tasks ranging from few-shot learning to policy distillation that confirm their real-worlds applicability.
Pick Your Battles: Interaction Graphs as Population-Level Objectives for Strategic Diversity
Oct 08, 2021Strategic diversity is often essential in games: in multi-player games, for example, evaluating a player against a diverse set of strategies will yield a more accurate estimate of its performance. Furthermore, in games with non-transitivities diversity allows a player to cover several winning strategies. However, despite the significance of strategic diversity, training agents that exhibit diverse behaviour remains a challenge. In this paper we study how to construct diverse populations of agents by carefully structuring how individuals within a population interact. Our approach is based on interaction graphs, which control the flow of information between agents during training and can encourage agents to specialise on different strategies, leading to improved overall performance. We provide evidence for the importance of diversity in multi-agent training and analyse the effect of applying different interaction graphs on the training trajectories, diversity and performance of populations in a range of games. This is an extended version of the long abstract published at AAMAS.
Inferring a Continuous Distribution of Atom Coordinates from Cryo-EM Images using VAEs
Jun 26, 2021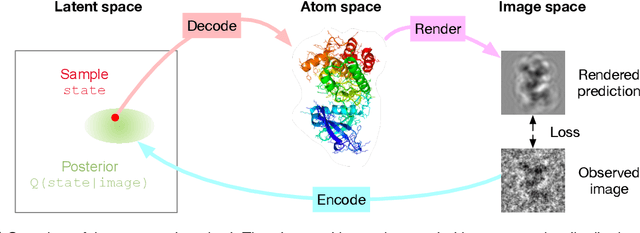
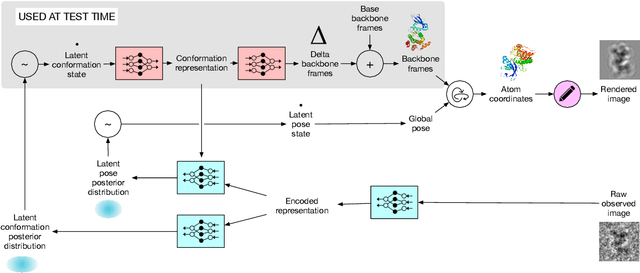
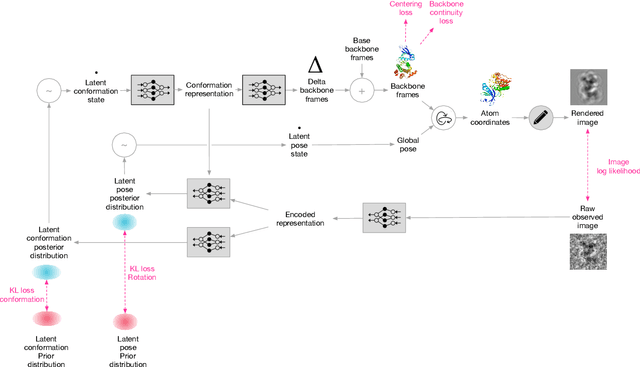
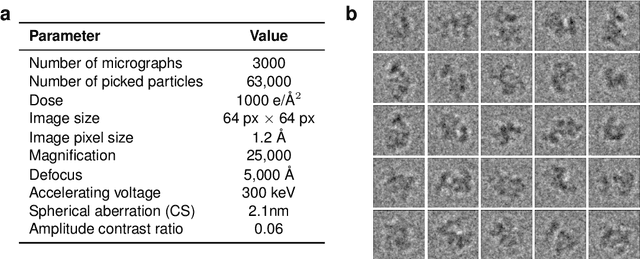
Cryo-electron microscopy (cryo-EM) has revolutionized experimental protein structure determination. Despite advances in high resolution reconstruction, a majority of cryo-EM experiments provide either a single state of the studied macromolecule, or a relatively small number of its conformations. This reduces the effectiveness of the technique for proteins with flexible regions, which are known to play a key role in protein function. Recent methods for capturing conformational heterogeneity in cryo-EM data model it in volume space, making recovery of continuous atomic structures challenging. Here we present a fully deep-learning-based approach using variational auto-encoders (VAEs) to recover a continuous distribution of atomic protein structures and poses directly from picked particle images and demonstrate its efficacy on realistic simulated data. We hope that methods built on this work will allow incorporation of stronger prior information about protein structure and enable better understanding of non-rigid protein structures.
Time-series Imputation of Temporally-occluded Multiagent Trajectories
Jun 08, 2021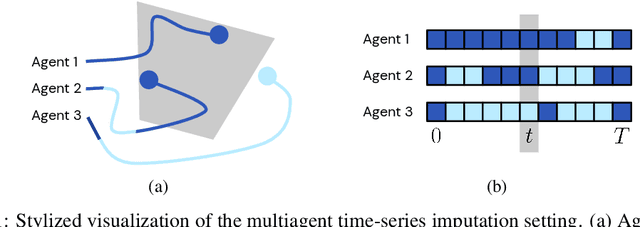
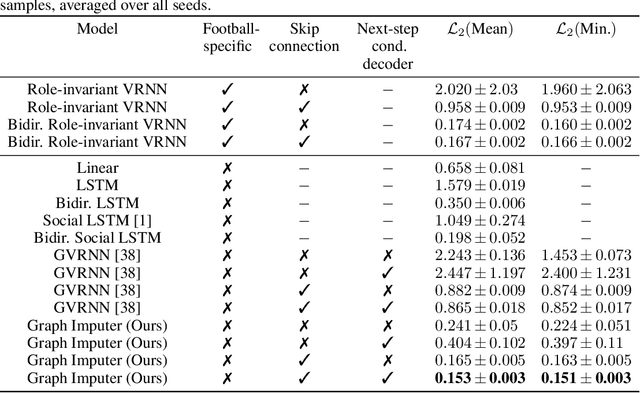


In multiagent environments, several decision-making individuals interact while adhering to the dynamics constraints imposed by the environment. These interactions, combined with the potential stochasticity of the agents' decision-making processes, make such systems complex and interesting to study from a dynamical perspective. Significant research has been conducted on learning models for forward-direction estimation of agent behaviors, for example, pedestrian predictions used for collision-avoidance in self-driving cars. However, in many settings, only sporadic observations of agents may be available in a given trajectory sequence. For instance, in football, subsets of players may come in and out of view of broadcast video footage, while unobserved players continue to interact off-screen. In this paper, we study the problem of multiagent time-series imputation, where available past and future observations of subsets of agents are used to estimate missing observations for other agents. Our approach, called the Graph Imputer, uses forward- and backward-information in combination with graph networks and variational autoencoders to enable learning of a distribution of imputed trajectories. We evaluate our approach on a dataset of football matches, using a projective camera module to train and evaluate our model for the off-screen player state estimation setting. We illustrate that our method outperforms several state-of-the-art approaches, including those hand-crafted for football.
Game Plan: What AI can do for Football, and What Football can do for AI
Nov 18, 2020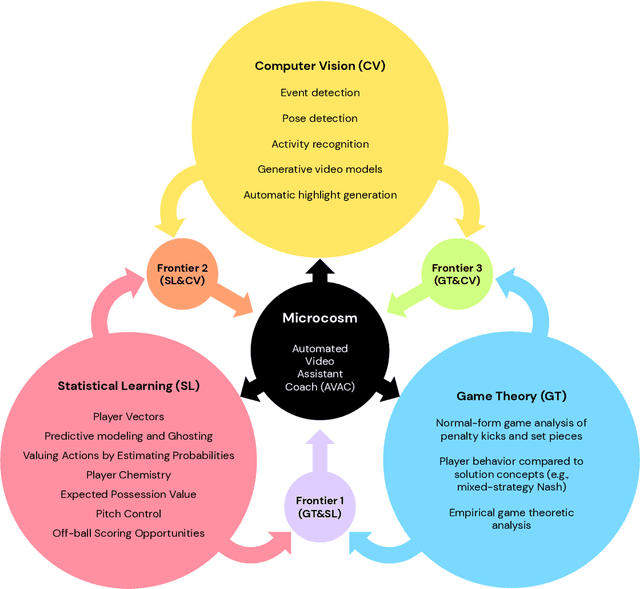



The rapid progress in artificial intelligence (AI) and machine learning has opened unprecedented analytics possibilities in various team and individual sports, including baseball, basketball, and tennis. More recently, AI techniques have been applied to football, due to a huge increase in data collection by professional teams, increased computational power, and advances in machine learning, with the goal of better addressing new scientific challenges involved in the analysis of both individual players' and coordinated teams' behaviors. The research challenges associated with predictive and prescriptive football analytics require new developments and progress at the intersection of statistical learning, game theory, and computer vision. In this paper, we provide an overarching perspective highlighting how the combination of these fields, in particular, forms a unique microcosm for AI research, while offering mutual benefits for professional teams, spectators, and broadcasters in the years to come. We illustrate that this duality makes football analytics a game changer of tremendous value, in terms of not only changing the game of football itself, but also in terms of what this domain can mean for the field of AI. We review the state-of-the-art and exemplify the types of analysis enabled by combining the aforementioned fields, including illustrative examples of counterfactual analysis using predictive models, and the combination of game-theoretic analysis of penalty kicks with statistical learning of player attributes. We conclude by highlighting envisioned downstream impacts, including possibilities for extensions to other sports (real and virtual).
AlignNet: Unsupervised Entity Alignment
Jul 21, 2020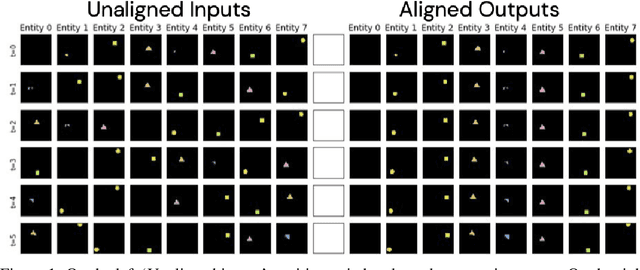

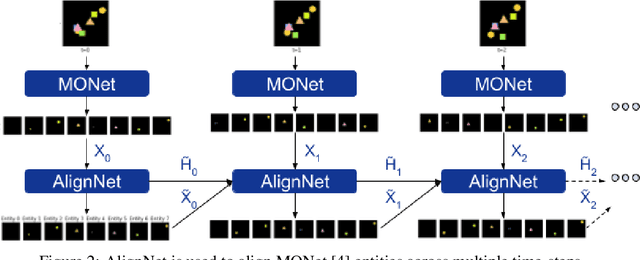
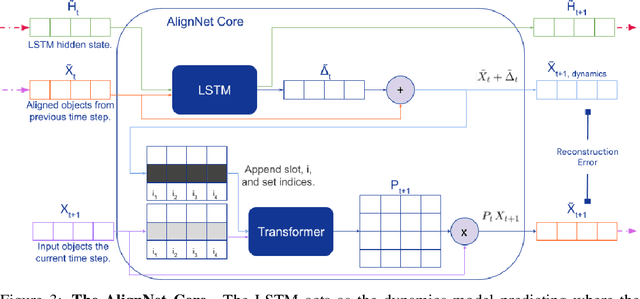
Recently developed deep learning models are able to learn to segment scenes into component objects without supervision. This opens many new and exciting avenues of research, allowing agents to take objects (or entities) as inputs, rather that pixels. Unfortunately, while these models provide excellent segmentation of a single frame, they do not keep track of how objects segmented at one time-step correspond (or align) to those at a later time-step. The alignment (or correspondence) problem has impeded progress towards using object representations in downstream tasks. In this paper we take steps towards solving the alignment problem, presenting the AlignNet, an unsupervised alignment module.
Minimax Theorem for Latent Games or: How I Learned to Stop Worrying about Mixed-Nash and Love Neural Nets
Feb 14, 2020
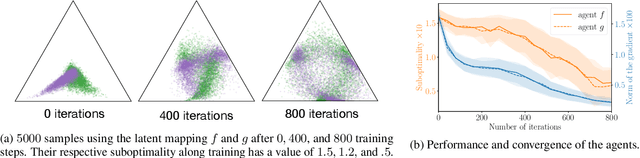
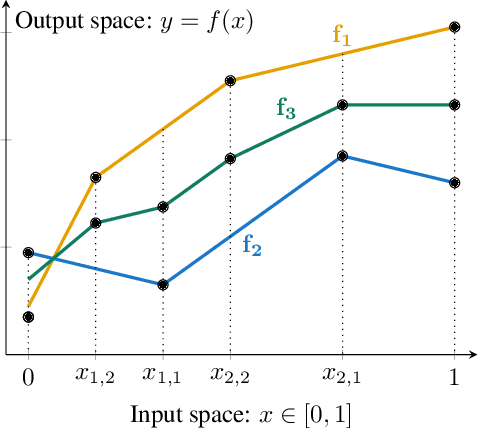
Adversarial training, a special case of multi-objective optimization, is an increasingly useful tool in machine learning. For example, two-player zero-sum games are important for generative modeling (GANs) and for mastering games like Go or Poker via self-play. A classic result in Game Theory states that one must mix strategies, as pure equilibria may not exist. Surprisingly, machine learning practitioners typically train a \emph{single} pair of agents -- instead of a pair of mixtures -- going against Nash's principle. Our main contribution is a notion of limited-capacity-equilibrium for which, as capacity grows, optimal agents -- not mixtures -- can learn increasingly expressive and realistic behaviors. We define \emph{latent games}, a new class of game where agents are mappings that transform latent distributions. Examples include generators in GANs, which transform Gaussian noise into distributions on images, and StarCraft II agents, which transform sampled build orders into policies. We show that minimax equilibria in latent games can be approximated by a \emph{single} pair of dense neural networks. Finally, we apply our latent game approach to solve differentiable Blotto, a game with an infinite strategy space.
A Neural Architecture for Designing Truthful and Efficient Auctions
Jul 11, 2019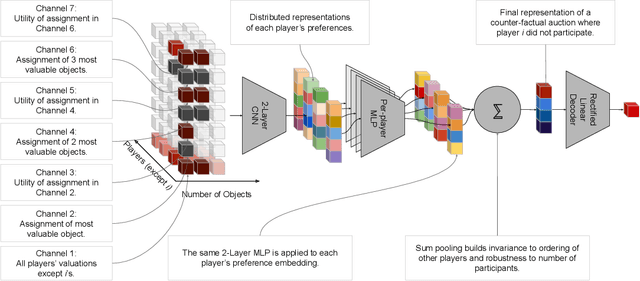
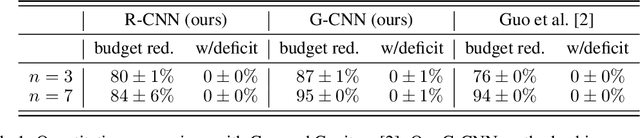
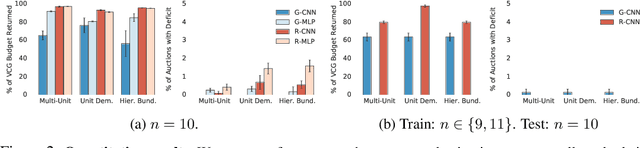
Auctions are protocols to allocate goods to buyers who have preferences over them, and collect payments in return. Economists have invested significant effort in designing auction rules that result in allocations of the goods that are desirable for the group as a whole. However, for settings where participants' valuations of the items on sale are their private information, the rules of the auction must deter buyers from misreporting their preferences, so as to maximize their own utility, since misreported preferences hinder the ability for the auctioneer to allocate goods to those who want them most. Manual auction design has yielded excellent mechanisms for specific settings, but requires significant effort when tackling new domains. We propose a deep learning based approach to automatically design auctions in a wide variety of domains, shifting the design work from human to machine. We assume that participants' valuations for the items for sale are independently sampled from an unknown but fixed distribution. Our system receives a data-set consisting of such valuation samples, and outputs an auction rule encoding the desired incentive structure. We focus on producing truthful and efficient auctions that minimize the economic burden on participants. We evaluate the auctions designed by our framework on well-studied domains, such as multi-unit and combinatorial auctions, showing that they outperform known auction designs in terms of the economic burden placed on participants.
An Explicitly Relational Neural Network Architecture
May 24, 2019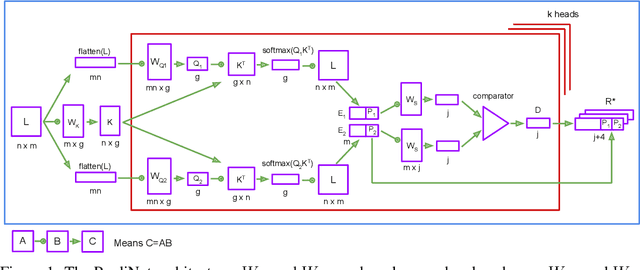
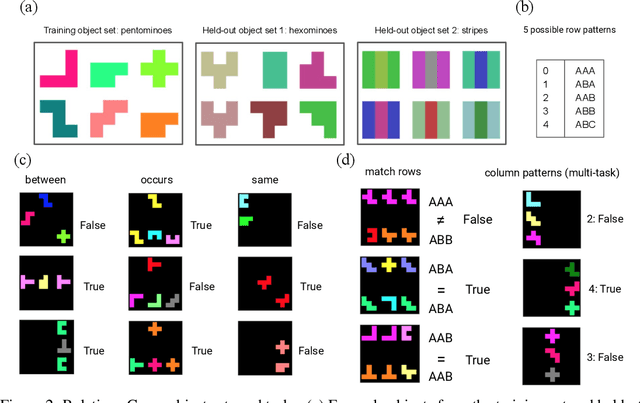
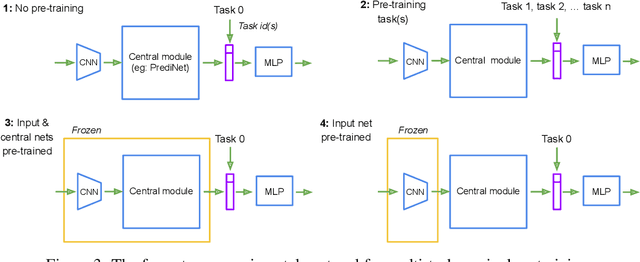
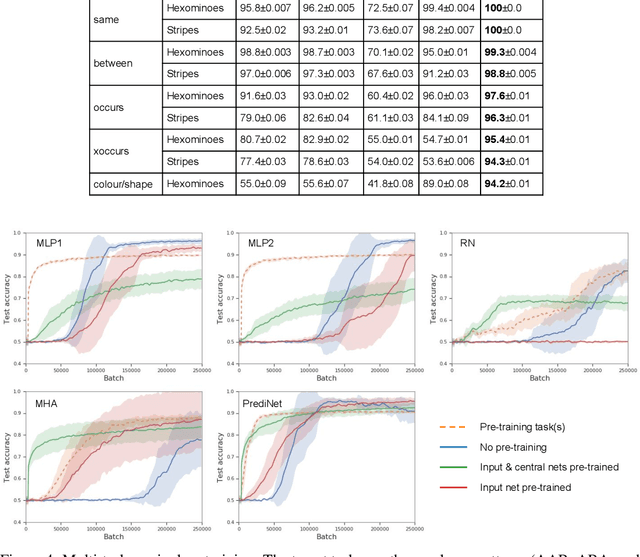
With a view to bridging the gap between deep learning and symbolic AI, we present a novel end-to-end neural network architecture that learns to form propositional representations with an explicitly relational structure from raw pixel data. In order to evaluate and analyse the architecture, we introduce a family of simple visual relational reasoning tasks of varying complexity. We show that the proposed architecture, when pre-trained on a curriculum of such tasks, learns to generate reusable representations that better facilitate subsequent learning on previously unseen tasks when compared to a number of baseline architectures. The workings of a successfully trained model are visualised to shed some light on how the architecture functions.
Meta-Learning surrogate models for sequential decision making
Mar 28, 2019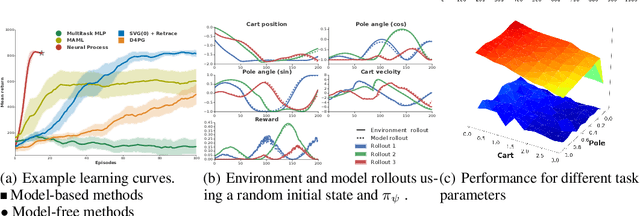

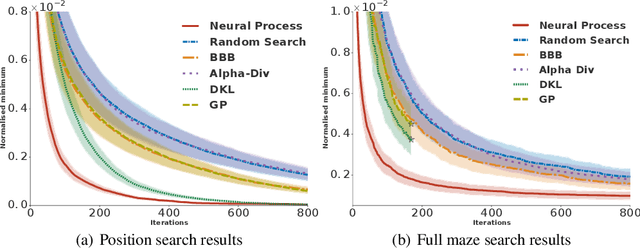
Meta-learning methods leverage past experience to learn data-driven inductive biases from related problems, increasing learning efficiency on new tasks. This ability renders them particularly suitable for sequential decision making with limited experience. Within this problem family, we argue for the use of such approaches in the study of model-based approaches to Bayesian Optimisation, contextual bandits and Reinforcement Learning. We approach the problem by learning distributions over functions using Neural Processes (NPs), a recently introduced probabilistic meta-learning method. This allows the treatment of model uncertainty to tackle the exploration/exploitation dilemma. We show that NPs are suitable for sequential decision making on a diverse set of domains, including adversarial task search, recommender systems and model-based reinforcement learning.