 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Formalising Concepts as Grounded Abstractions
Jan 13, 2021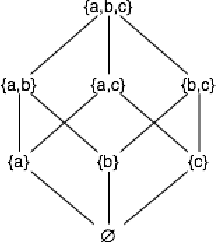
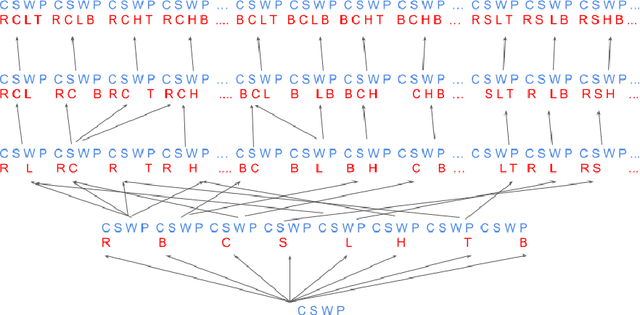
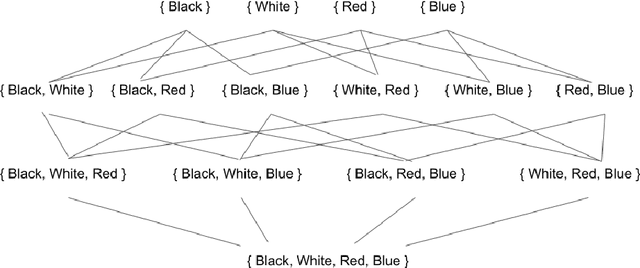
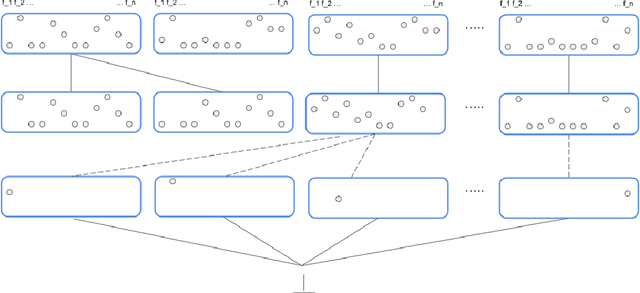
The notion of concept has been studied for centuries, by philosophers, linguists, cognitive scientists, and researchers in artificial intelligence (Margolis & Laurence, 1999). There is a large literature on formal, mathematical models of concepts, including a whole sub-field of AI -- Formal Concept Analysis -- devoted to this topic (Ganter & Obiedkov, 2016). Recently, researchers in machine learning have begun to investigate how methods from representation learning can be used to induce concepts from raw perceptual data (Higgins, Sonnerat, et al., 2018). The goal of this report is to provide a formal account of concepts which is compatible with this latest work in deep learning. The main technical goal of this report is to show how techniques from representation learning can be married with a lattice-theoretic formulation of conceptual spaces. The mathematics of partial orders and lattices is a standard tool for modelling conceptual spaces (Ch.2, Mitchell (1997), Ganter and Obiedkov (2016)); however, there is no formal work that we are aware of which defines a conceptual lattice on top of a representation that is induced using unsupervised deep learning (Goodfellow et al., 2016). The advantages of partially-ordered lattice structures are that these provide natural mechanisms for use in concept discovery algorithms, through the meets and joins of the lattice.
AlignNet: Unsupervised Entity Alignment
Jul 21, 2020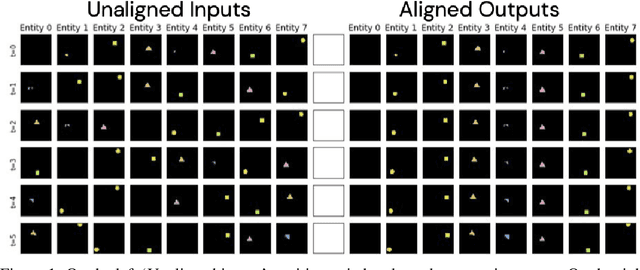

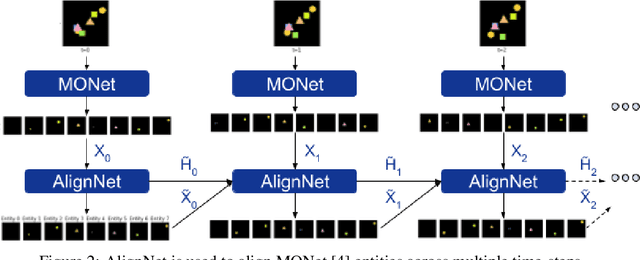
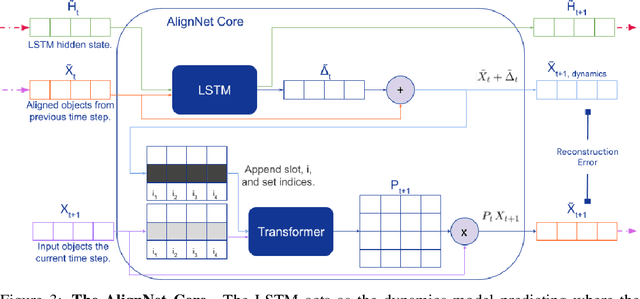
Recently developed deep learning models are able to learn to segment scenes into component objects without supervision. This opens many new and exciting avenues of research, allowing agents to take objects (or entities) as inputs, rather that pixels. Unfortunately, while these models provide excellent segmentation of a single frame, they do not keep track of how objects segmented at one time-step correspond (or align) to those at a later time-step. The alignment (or correspondence) problem has impeded progress towards using object representations in downstream tasks. In this paper we take steps towards solving the alignment problem, presenting the AlignNet, an unsupervised alignment module.
Making Efficient Use of Demonstrations to Solve Hard Exploration Problems
Sep 03, 2019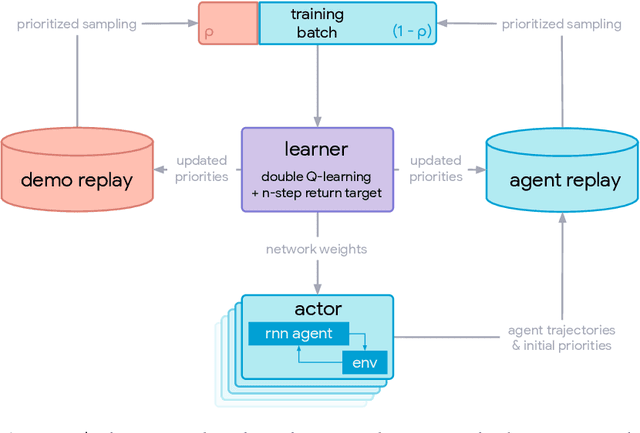
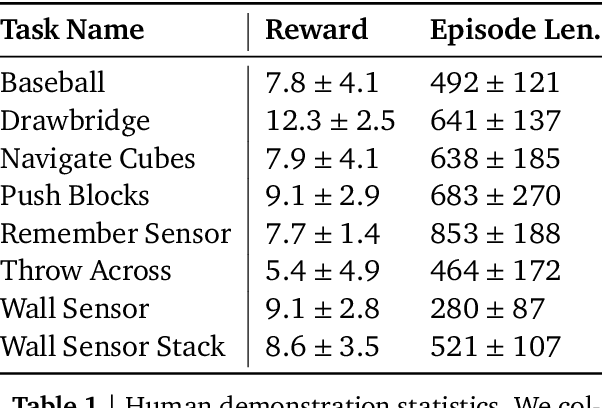
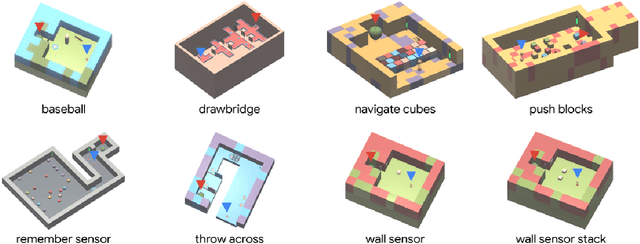
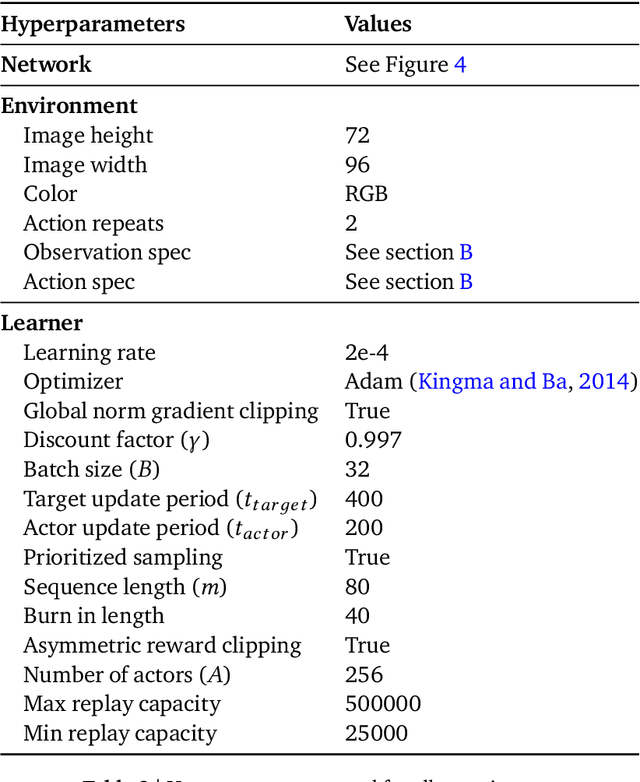
This paper introduces R2D3, an agent that makes efficient use of demonstrations to solve hard exploration problems in partially observable environments with highly variable initial conditions. We also introduce a suite of eight tasks that combine these three properties, and show that R2D3 can solve several of the tasks where other state of the art methods (both with and without demonstrations) fail to see even a single successful trajectory after tens of billions of steps of exploration.