 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated near-term quantum algorithm discovery for molecular ground states
Mar 27, 2026Designing quantum algorithms is a complex and counterintuitive task, making it an ideal candidate for AI-driven algorithm discovery. To this end, we employ the Hive, an AI platform for program synthesis, which utilises large language models to drive a highly distributed evolutionary process for discovering new algorithms. We focus on the ground state problem in quantum chemistry, and discover efficient quantum heuristic algorithms that solve it for molecules LiH, H2O, and F2 while exhibiting significant reductions in quantum resources relative to state-of-the-art near-term quantum algorithms. Further, we perform an interpretability study on the discovered algorithms and identify the key functions responsible for the efficiency gains. Finally, we benchmark the Hive-discovered circuits on the Quantinuum System Model H2 quantum computer and identify minimum system requirements for chemical precision. We envision that this novel approach to quantum algorithm discovery applies to other domains beyond chemistry, as well as to designing quantum algorithms for fault-tolerant quantum computers.
Learning Complex Word Embeddings in Classical and Quantum Spaces
Dec 18, 2024



We present a variety of methods for training complex-valued word embeddings, based on the classical Skip-gram model, with a straightforward adaptation simply replacing the real-valued vectors with arbitrary vectors of complex numbers. In a more "physically-inspired" approach, the vectors are produced by parameterised quantum circuits (PQCs), which are unitary transformations resulting in normalised vectors which have a probabilistic interpretation. We develop a complex-valued version of the highly optimised C code version of Skip-gram, which allows us to easily produce complex embeddings trained on a 3.8B-word corpus for a vocabulary size of over 400k, for which we are then able to train a separate PQC for each word. We evaluate the complex embeddings on a set of standard similarity and relatedness datasets, for some models obtaining results competitive with the classical baseline. We find that, while training the PQCs directly tends to harm performance, the quantum word embeddings from the two-stage process perform as well as the classical Skip-gram embeddings with comparable numbers of parameters. This enables a highly scalable route to learning embeddings in complex spaces which scales with the size of the vocabulary rather than the size of the training corpus. In summary, we demonstrate how to produce a large set of high-quality word embeddings for use in complex-valued and quantum-inspired NLP models, and for exploring potential advantage in quantum NLP models.
Towards Compositional Interpretability for XAI
Jun 25, 2024Artificial intelligence (AI) is currently based largely on black-box machine learning models which lack interpretability. The field of eXplainable AI (XAI) strives to address this major concern, being critical in high-stakes areas such as the finance, legal and health sectors. We present an approach to defining AI models and their interpretability based on category theory. For this we employ the notion of a compositional model, which sees a model in terms of formal string diagrams which capture its abstract structure together with its concrete implementation. This comprehensive view incorporates deterministic, probabilistic and quantum models. We compare a wide range of AI models as compositional models, including linear and rule-based models, (recurrent) neural networks, transformers, VAEs, and causal and DisCoCirc models. Next we give a definition of interpretation of a model in terms of its compositional structure, demonstrating how to analyse the interpretability of a model, and using this to clarify common themes in XAI. We find that what makes the standard 'intrinsically interpretable' models so transparent is brought out most clearly diagrammatically. This leads us to the more general notion of compositionally-interpretable (CI) models, which additionally include, for instance, causal, conceptual space, and DisCoCirc models. We next demonstrate the explainability benefits of CI models. Firstly, their compositional structure may allow the computation of other quantities of interest, and may facilitate inference from the model to the modelled phenomenon by matching its structure. Secondly, they allow for diagrammatic explanations for their behaviour, based on influence constraints, diagram surgery and rewrite explanations. Finally, we discuss many future directions for the approach, raising the question of how to learn such meaningfully structured models in practice.
Enhancing Surgical Performance in Cardiothoracic Surgery with Innovations from Computer Vision and Artificial Intelligence: A Narrative Review
Feb 17, 2024When technical requirements are high, and patient outcomes are critical, opportunities for monitoring and improving surgical skills via objective motion analysis feedback may be particularly beneficial. This narrative review synthesises work on technical and non-technical surgical skills, collaborative task performance, and pose estimation to illustrate new opportunities to advance cardiothoracic surgical performance with innovations from computer vision and artificial intelligence. These technological innovations are critically evaluated in terms of the benefits they could offer the cardiothoracic surgical community, and any barriers to the uptake of the technology are elaborated upon. Like some other specialities, cardiothoracic surgery has relatively few opportunities to benefit from tools with data capture technology embedded within them (as with robotic-assisted laparoscopic surgery, for example). In such cases, pose estimation techniques that allow for movement tracking across a conventional operating field without using specialist equipment or markers offer considerable potential. With video data from either simulated or real surgical procedures, these tools can (1) provide insight into the development of expertise and surgical performance over a surgeon's career, (2) provide feedback to trainee surgeons regarding areas for improvement, (3) provide the opportunity to investigate what aspects of skill may be linked to patient outcomes which can (4) inform the aspects of surgical skill which should be focused on within training or mentoring programmes. Classifier or assessment algorithms that use artificial intelligence to 'learn' what expertise is from expert surgical evaluators could further assist educators in determining if trainees meet competency thresholds.
Peptide Binding Classification on Quantum Computers
Nov 27, 2023



We conduct an extensive study on using near-term quantum computers for a task in the domain of computational biology. By constructing quantum models based on parameterised quantum circuits we perform sequence classification on a task relevant to the design of therapeutic proteins, and find competitive performance with classical baselines of similar scale. To study the effect of noise, we run some of the best-performing quantum models with favourable resource requirements on emulators of state-of-the-art noisy quantum processors. We then apply error mitigation methods to improve the signal. We further execute these quantum models on the Quantinuum H1-1 trapped-ion quantum processor and observe very close agreement with noiseless exact simulation. Finally, we perform feature attribution methods and find that the quantum models indeed identify sensible relationships, at least as well as the classical baselines. This work constitutes the first proof-of-concept application of near-term quantum computing to a task critical to the design of therapeutic proteins, opening the route toward larger-scale applications in this and related fields, in line with the hardware development roadmaps of near-term quantum technologies.
Formalising and Learning a Quantum Model of Concepts
Feb 07, 2023

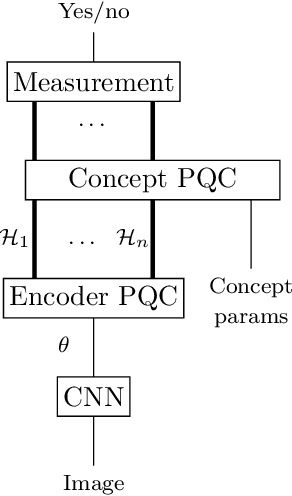
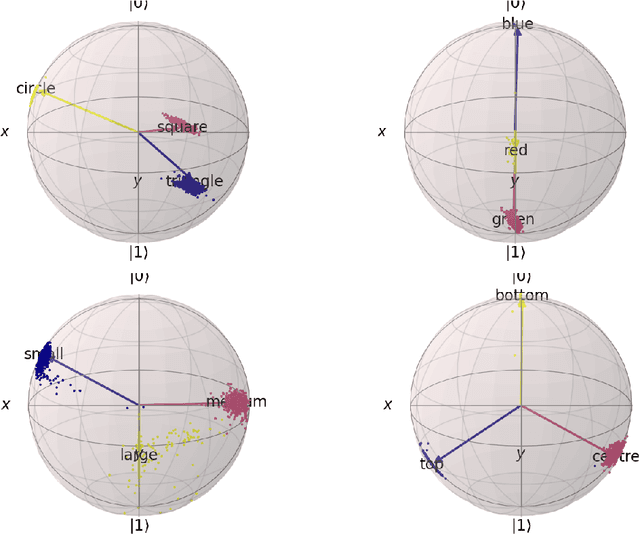
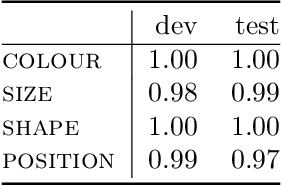
In this report we present a new modelling framework for concepts based on quantum theory, and demonstrate how the conceptual representations can be learned automatically from data. A contribution of the work is a thorough category-theoretic formalisation of our framework. We claim that the use of category theory, and in particular the use of string diagrams to describe quantum processes, helps elucidate some of the most important features of our quantum approach to concept modelling. Our approach builds upon Gardenfors' classical framework of conceptual spaces, in which cognition is modelled geometrically through the use of convex spaces, which in turn factorise in terms of simpler spaces called domains. We show how concepts from the domains of shape, colour, size and position can be learned from images of simple shapes, where individual images are represented as quantum states and concepts as quantum effects. Concepts are learned by a hybrid classical-quantum network trained to perform concept classification, where the classical image processing is carried out by a convolutional neural network and the quantum representations are produced by a parameterised quantum circuit. We also use discarding to produce mixed effects, which can then be used to learn concepts which only apply to a subset of the domains, and show how entanglement (together with discarding) can be used to capture interesting correlations across domains. Finally, we consider the question of whether our quantum models of concepts can be considered conceptual spaces in the Gardenfors sense.
The Conceptual VAE
Mar 21, 2022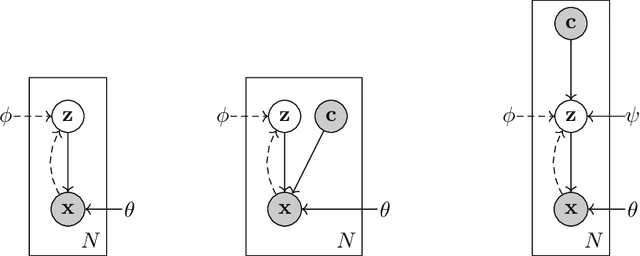
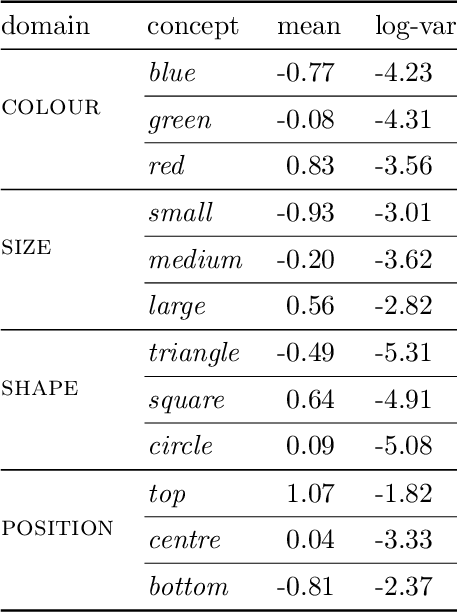
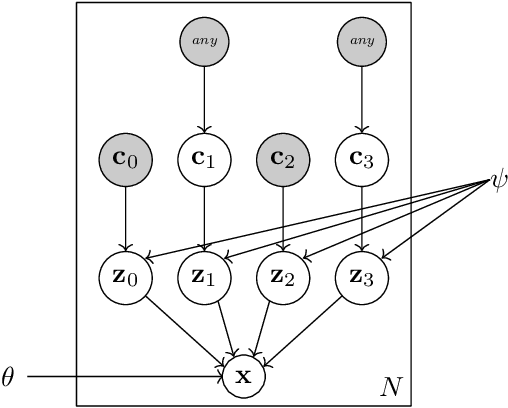
In this report we present a new model of concepts, based on the framework of variational autoencoders, which is designed to have attractive properties such as factored conceptual domains, and at the same time be learnable from data. The model is inspired by, and closely related to, the Beta-VAE model of concepts, but is designed to be more closely connected with language, so that the names of concepts form part of the graphical model. We provide evidence that our model -- which we call the Conceptual VAE -- is able to learn interpretable conceptual representations from simple images of coloured shapes together with the corresponding concept labels. We also show how the model can be used as a concept classifier, and how it can be adapted to learn from fewer labels per instance. Finally, we formally relate our model to Gardenfors' theory of conceptual spaces, showing how the Gaussians we use to represent concepts can be formalised in terms of "fuzzy concepts" in such a space.
lambeq: An Efficient High-Level Python Library for Quantum NLP
Oct 08, 2021


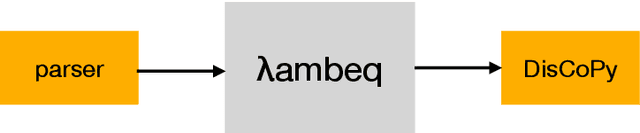
We present lambeq, the first high-level Python library for Quantum Natural Language Processing (QNLP). The open-source toolkit offers a detailed hierarchy of modules and classes implementing all stages of a pipeline for converting sentences to string diagrams, tensor networks, and quantum circuits ready to be used on a quantum computer. lambeq supports syntactic parsing, rewriting and simplification of string diagrams, ansatz creation and manipulation, as well as a number of compositional models for preparing quantum-friendly representations of sentences, employing various degrees of syntax sensitivity. We present the generic architecture and describe the most important modules in detail, demonstrating the usage with illustrative examples. Further, we test the toolkit in practice by using it to perform a number of experiments on simple NLP tasks, implementing both classical and quantum pipelines.
Something Old, Something New: Grammar-based CCG Parsing with Transformer Models
Sep 28, 2021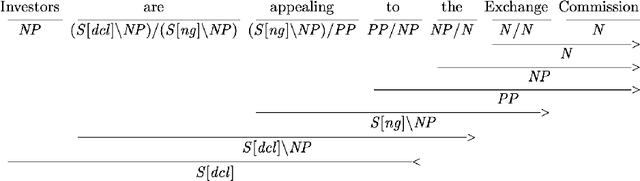
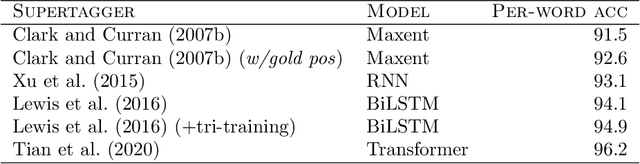


This report describes the parsing problem for Combinatory Categorial Grammar (CCG), showing how a combination of Transformer-based neural models and a symbolic CCG grammar can lead to substantial gains over existing approaches. The report also documents a 20-year research program, showing how NLP methods have evolved over this time. The staggering accuracy improvements provided by neural models for CCG parsing can be seen as a reflection of the improvements seen in NLP more generally. The report provides a minimal introduction to CCG and CCG parsing, with many pointers to the relevant literature. It then describes the CCG supertagging problem, and some recent work from Tian et al. (2020) which applies Transformer-based models to supertagging with great effect. I use this existing model to develop a CCG multitagger, which can serve as a front-end to an existing CCG parser. Simply using this new multitagger provides substantial gains in parsing accuracy. I then show how a Transformer-based model from the parsing literature can be combined with the grammar-based CCG parser, setting a new state-of-the-art for the CCGbank parsing task of almost 93% F-score for labelled dependencies, with complete sentence accuracies of over 50%.
Imitating Interactive Intelligence
Jan 21, 2021
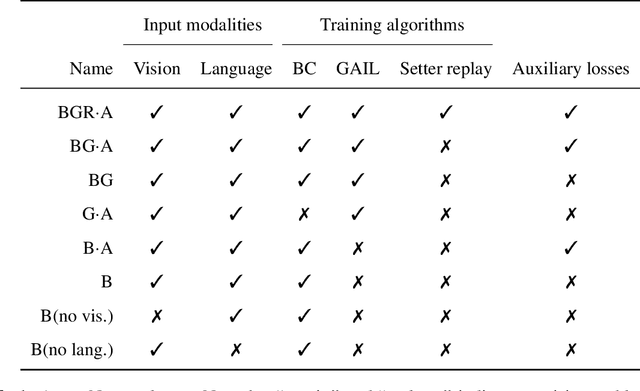
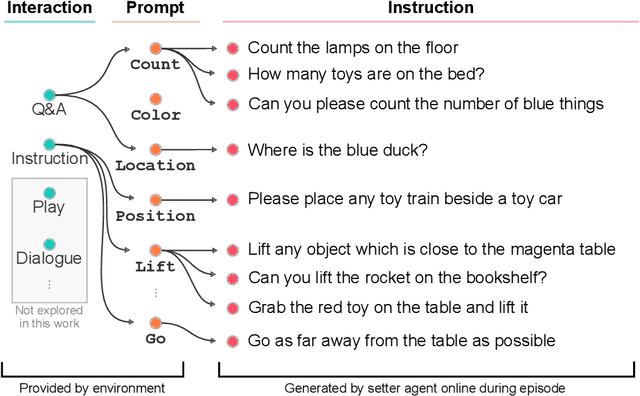
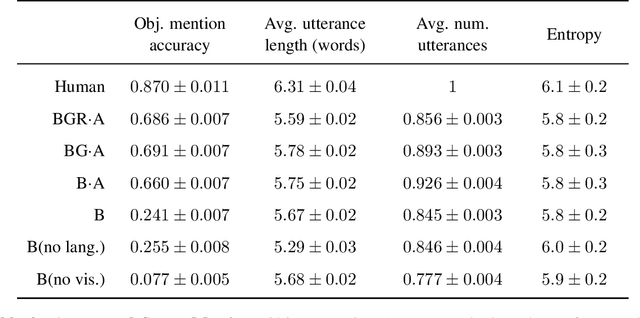
A common vision from science fiction is that robots will one day inhabit our physical spaces, sense the world as we do, assist our physical labours, and communicate with us through natural language. Here we study how to design artificial agents that can interact naturally with humans using the simplification of a virtual environment. This setting nevertheless integrates a number of the central challenges of artificial intelligence (AI) research: complex visual perception and goal-directed physical control, grounded language comprehension and production, and multi-agent social interaction. To build agents that can robustly interact with humans, we would ideally train them while they interact with humans. However, this is presently impractical. Therefore, we approximate the role of the human with another learned agent, and use ideas from inverse reinforcement learning to reduce the disparities between human-human and agent-agent interactive behaviour. Rigorously evaluating our agents poses a great challenge, so we develop a variety of behavioural tests, including evaluation by humans who watch videos of agents or interact directly with them. These evaluations convincingly demonstrate that interactive training and auxiliary losses improve agent behaviour beyond what is achieved by supervised learning of actions alone. Further, we demonstrate that agent capabilities generalise beyond literal experiences in the dataset. Finally, we train evaluation models whose ratings of agents agree well with human judgement, thus permitting the evaluation of new agent models without additional effort. Taken together, our results in this virtual environment provide evidence that large-scale human behavioural imitation is a promising tool to create intelligent, interactive agents, and the challenge of reliably evaluating such agents is possible to surmount.