 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Generation of Parameterised Quantum Circuits from Large Texts
May 19, 2025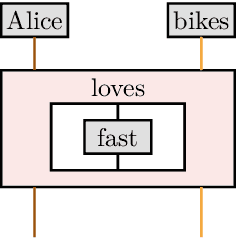
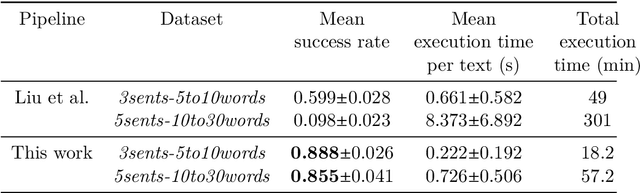
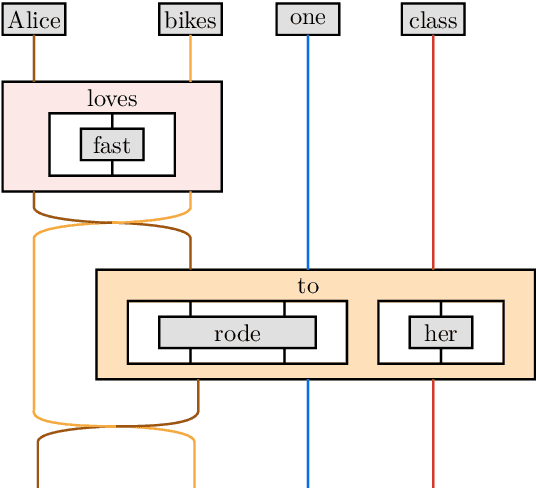

Quantum approaches to natural language processing (NLP) are redefining how linguistic information is represented and processed. While traditional hybrid quantum-classical models rely heavily on classical neural networks, recent advancements propose a novel framework, DisCoCirc, capable of directly encoding entire documents as parameterised quantum circuits (PQCs), besides enjoying some additional interpretability and compositionality benefits. Following these ideas, this paper introduces an efficient methodology for converting large-scale texts into quantum circuits using tree-like representations of pregroup diagrams. Exploiting the compositional parallels between language and quantum mechanics, grounded in symmetric monoidal categories, our approach enables faithful and efficient encoding of syntactic and discourse relationships in long and complex texts (up to 6410 words in our experiments) to quantum circuits. The developed system is provided to the community as part of the augmented open-source quantum NLP package lambeq Gen II.
Peptide Binding Classification on Quantum Computers
Nov 27, 2023



We conduct an extensive study on using near-term quantum computers for a task in the domain of computational biology. By constructing quantum models based on parameterised quantum circuits we perform sequence classification on a task relevant to the design of therapeutic proteins, and find competitive performance with classical baselines of similar scale. To study the effect of noise, we run some of the best-performing quantum models with favourable resource requirements on emulators of state-of-the-art noisy quantum processors. We then apply error mitigation methods to improve the signal. We further execute these quantum models on the Quantinuum H1-1 trapped-ion quantum processor and observe very close agreement with noiseless exact simulation. Finally, we perform feature attribution methods and find that the quantum models indeed identify sensible relationships, at least as well as the classical baselines. This work constitutes the first proof-of-concept application of near-term quantum computing to a task critical to the design of therapeutic proteins, opening the route toward larger-scale applications in this and related fields, in line with the hardware development roadmaps of near-term quantum technologies.
lambeq: An Efficient High-Level Python Library for Quantum NLP
Oct 08, 2021


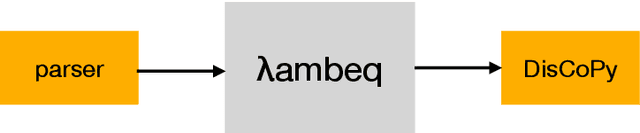
We present lambeq, the first high-level Python library for Quantum Natural Language Processing (QNLP). The open-source toolkit offers a detailed hierarchy of modules and classes implementing all stages of a pipeline for converting sentences to string diagrams, tensor networks, and quantum circuits ready to be used on a quantum computer. lambeq supports syntactic parsing, rewriting and simplification of string diagrams, ansatz creation and manipulation, as well as a number of compositional models for preparing quantum-friendly representations of sentences, employing various degrees of syntax sensitivity. We present the generic architecture and describe the most important modules in detail, demonstrating the usage with illustrative examples. Further, we test the toolkit in practice by using it to perform a number of experiments on simple NLP tasks, implementing both classical and quantum pipelines.
A CCG-Based Version of the DisCoCat Framework
May 24, 2021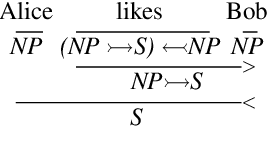
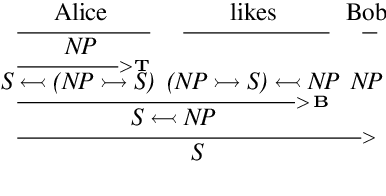
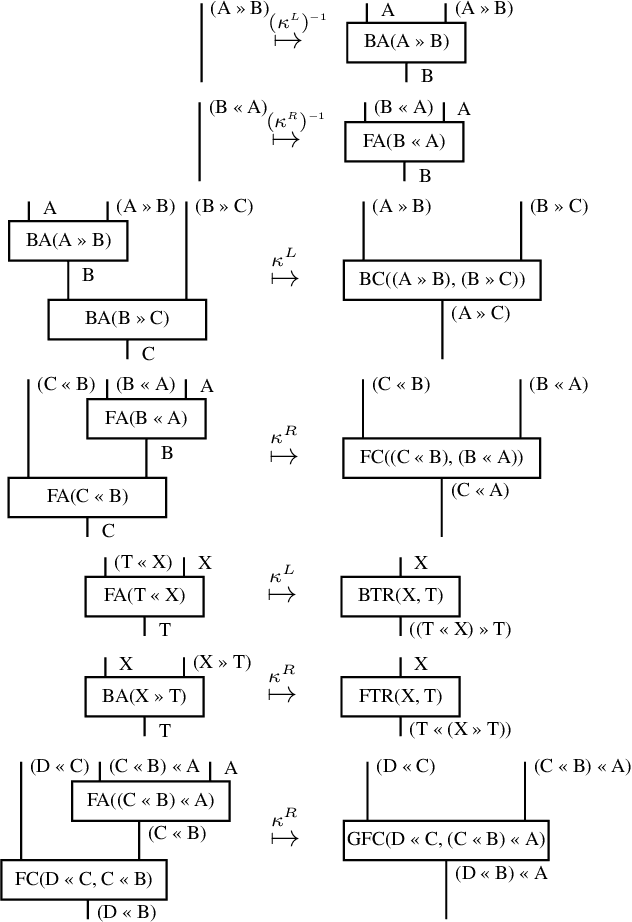
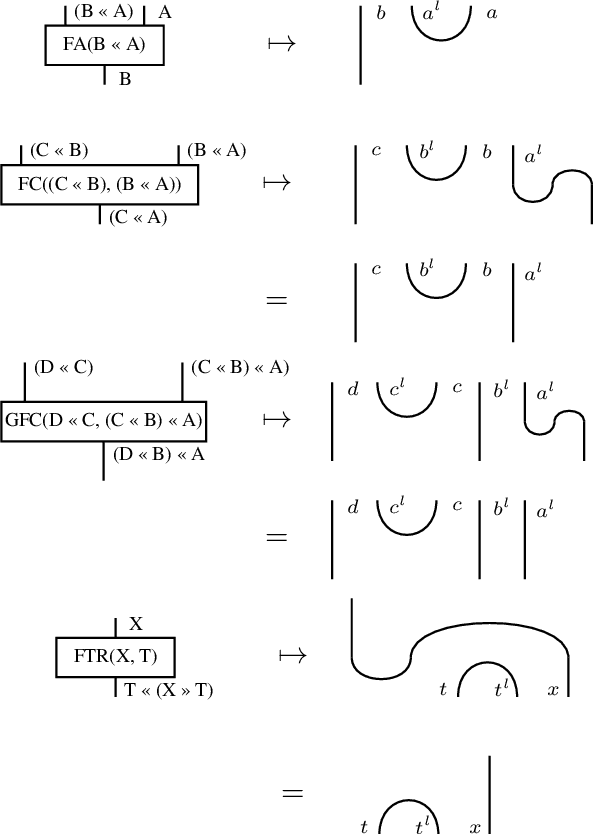
While the DisCoCat model (Coecke et al., 2010) has been proved a valuable tool for studying compositional aspects of language at the level of semantics, its strong dependency on pregroup grammars poses important restrictions: first, it prevents large-scale experimentation due to the absence of a pregroup parser; and second, it limits the expressibility of the model to context-free grammars. In this paper we solve these problems by reformulating DisCoCat as a passage from Combinatory Categorial Grammar (CCG) to a category of semantics. We start by showing that standard categorial grammars can be expressed as a biclosed category, where all rules emerge as currying/uncurrying the identity; we then proceed to model permutation-inducing rules by exploiting the symmetry of the compact closed category encoding the word meaning. We provide a proof of concept for our method, converting "Alice in Wonderland" into DisCoCat form, a corpus that we make available to the community.
QNLP in Practice: Running Compositional Models of Meaning on a Quantum Computer
Feb 25, 2021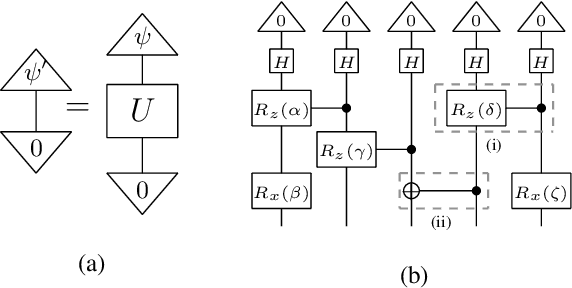

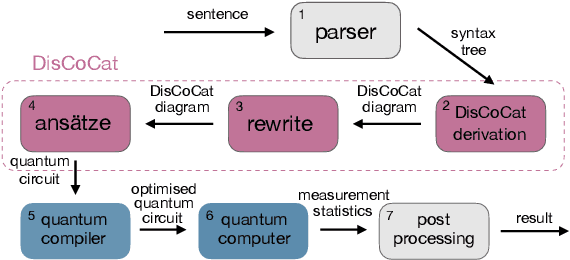
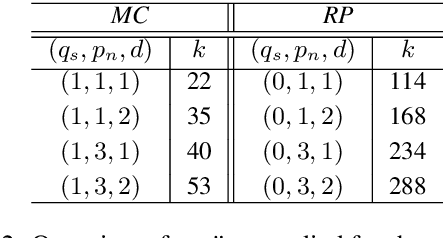
Quantum Natural Language Processing (QNLP) deals with the design and implementation of NLP models intended to be run on quantum hardware. In this paper, we present results on the first NLP experiments conducted on Noisy Intermediate-Scale Quantum (NISQ) computers for datasets of size >= 100 sentences. Exploiting the formal similarity of the compositional model of meaning by Coecke et al. (2010) with quantum theory, we create representations for sentences that have a natural mapping to quantum circuits. We use these representations to implement and successfully train two NLP models that solve simple sentence classification tasks on quantum hardware. We describe in detail the main principles, the process and challenges of these experiments, in a way accessible to NLP researchers, thus paving the way for practical Quantum Natural Language Processing.
Conversational Semantic Parsing for Dialog State Tracking
Oct 24, 2020
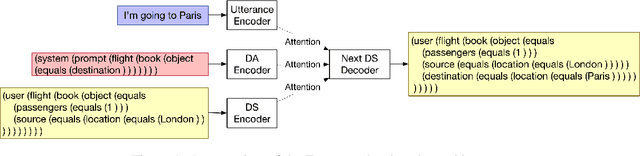

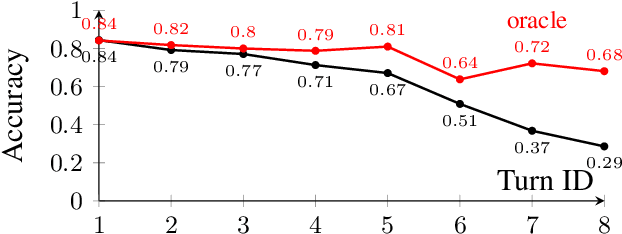
We consider a new perspective on dialog state tracking (DST), the task of estimating a user's goal through the course of a dialog. By formulating DST as a semantic parsing task over hierarchical representations, we can incorporate semantic compositionality, cross-domain knowledge sharing and co-reference. We present TreeDST, a dataset of 27k conversations annotated with tree-structured dialog states and system acts. We describe an encoder-decoder framework for DST with hierarchical representations, which leads to 20% improvement over state-of-the-art DST approaches that operate on a flat meaning space of slot-value pairs.
Unseen Word Representation by Aligning Heterogeneous Lexical Semantic Spaces
Nov 12, 2018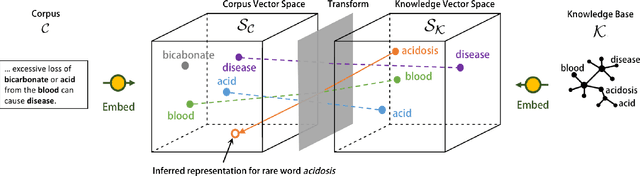

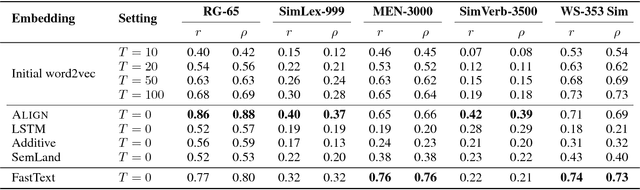
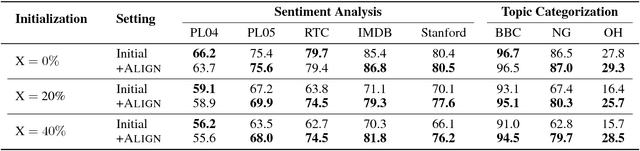
Word embedding techniques heavily rely on the abundance of training data for individual words. Given the Zipfian distribution of words in natural language texts, a large number of words do not usually appear frequently or at all in the training data. In this paper we put forward a technique that exploits the knowledge encoded in lexical resources, such as WordNet, to induce embeddings for unseen words. Our approach adapts graph embedding and cross-lingual vector space transformation techniques in order to merge lexical knowledge encoded in ontologies with that derived from corpus statistics. We show that the approach can provide consistent performance improvements across multiple evaluation benchmarks: in-vitro, on multiple rare word similarity datasets, and in-vivo, in two downstream text classification tasks.
Proceedings of the 2018 Workshop on Compositional Approaches in Physics, NLP, and Social Sciences
Nov 06, 2018The ability to compose parts to form a more complex whole, and to analyze a whole as a combination of elements, is desirable across disciplines. This workshop bring together researchers applying compositional approaches to physics, NLP, cognitive science, and game theory. Within NLP, a long-standing aim is to represent how words can combine to form phrases and sentences. Within the framework of distributional semantics, words are represented as vectors in vector spaces. The categorical model of Coecke et al. [2010], inspired by quantum protocols, has provided a convincing account of compositionality in vector space models of NLP. There is furthermore a history of vector space models in cognitive science. Theories of categorization such as those developed by Nosofsky [1986] and Smith et al. [1988] utilise notions of distance between feature vectors. More recently G\"ardenfors [2004, 2014] has developed a model of concepts in which conceptual spaces provide geometric structures, and information is represented by points, vectors and regions in vector spaces. The same compositional approach has been applied to this formalism, giving conceptual spaces theory a richer model of compositionality than previously [Bolt et al., 2018]. Compositional approaches have also been applied in the study of strategic games and Nash equilibria. In contrast to classical game theory, where games are studied monolithically as one global object, compositional game theory works bottom-up by building large and complex games from smaller components. Such an approach is inherently difficult since the interaction between games has to be considered. Research into categorical compositional methods for this field have recently begun [Ghani et al., 2018]. Moreover, the interaction between the three disciplines of cognitive science, linguistics and game theory is a fertile ground for research. Game theory in cognitive science is a well-established area [Camerer, 2011]. Similarly game theoretic approaches have been applied in linguistics [J\"ager, 2008]. Lastly, the study of linguistics and cognitive science is intimately intertwined [Smolensky and Legendre, 2006, Jackendoff, 2007]. Physics supplies compositional approaches via vector spaces and categorical quantum theory, allowing the interplay between the three disciplines to be examined.
Sentence Entailment in Compositional Distributional Semantics
Oct 09, 2018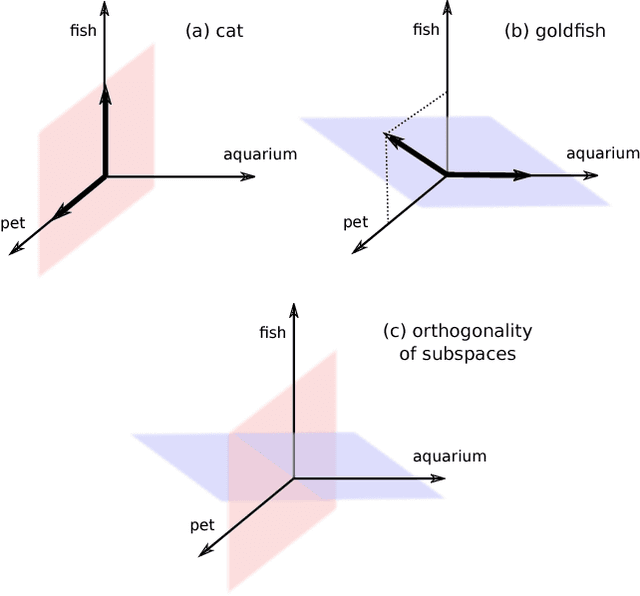
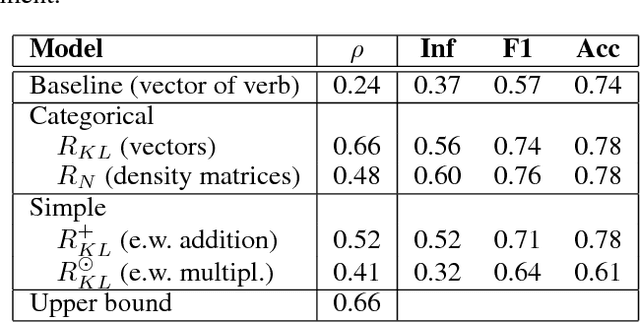

Distributional semantic models provide vector representations for words by gathering co-occurrence frequencies from corpora of text. Compositional distributional models extend these from words to phrases and sentences. In categorical compositional distributional semantics, phrase and sentence representations are functions of their grammatical structure and representations of the words therein. In this setting, grammatical structures are formalised by morphisms of a compact closed category and meanings of words are formalised by objects of the same category. These can be instantiated in the form of vectors or density matrices. This paper concerns the applications of this model to phrase and sentence level entailment. We argue that entropy-based distances of vectors and density matrices provide a good candidate to measure word-level entailment, show the advantage of density matrices over vectors for word level entailments, and prove that these distances extend compositionally from words to phrases and sentences. We exemplify our theoretical constructions on real data and a toy entailment dataset and provide preliminary experimental evidence.
* 8 pages, 1 figure, 2 tables, short version presented in the International Symposium on Artificial Intelligence and Mathematics (ISAIM), 2016
Card-660: Cambridge Rare Word Dataset - a Reliable Benchmark for Infrequent Word Representation Models
Aug 28, 2018



Rare word representation has recently enjoyed a surge of interest, owing to the crucial role that effective handling of infrequent words can play in accurate semantic understanding. However, there is a paucity of reliable benchmarks for evaluation and comparison of these techniques. We show in this paper that the only existing benchmark (the Stanford Rare Word dataset) suffers from low-confidence annotations and limited vocabulary; hence, it does not constitute a solid comparison framework. In order to fill this evaluation gap, we propose CAmbridge Rare word Dataset (Card-660), an expert-annotated word similarity dataset which provides a highly reliable, yet challenging, benchmark for rare word representation techniques. Through a set of experiments we show that even the best mainstream word embeddings, with millions of words in their vocabularies, are unable to achieve performances higher than 0.43 (Pearson correlation) on the dataset, compared to a human-level upperbound of 0.90. We release the dataset and the annotation materials at https://pilehvar.github.io/card-660/.