 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Deep Information Synthesis
Feb 24, 2026Large language model (LLM)-based agents are increasingly used to solve complex tasks involving tool use, such as web browsing, code execution, and data analysis. However, current evaluation benchmarks do not adequately assess their ability to solve real-world tasks that require synthesizing information from multiple sources and inferring insights beyond simple fact retrieval. To address this, we introduce DEEPSYNTH, a novel benchmark designed to evaluate agents on realistic, time-consuming problems that combine information gathering, synthesis, and structured reasoning to produce insights. DEEPSYNTH contains 120 tasks collected across 7 domains and data sources covering 67 countries. DEEPSYNTH is constructed using a multi-stage data collection pipeline that requires annotators to collect official data sources, create hypotheses, perform manual analysis, and design tasks with verifiable answers. When evaluated on DEEPSYNTH, 11 state-of-the-art LLMs and deep research agents achieve a maximum F1 score of 8.97 and 17.5 on the LLM-judge metric, underscoring the difficulty of the benchmark. Our analysis reveals that current agents struggle with hallucinations and reasoning over large information spaces, highlighting DEEPSYNTH as a crucial benchmark for guiding future research.
Autoencoding Conditional Neural Processes for Representation Learning
May 29, 2023
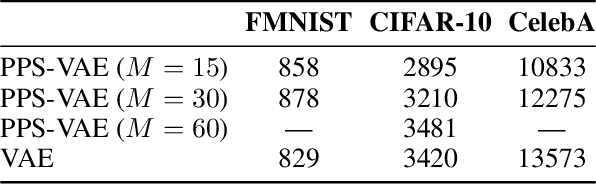
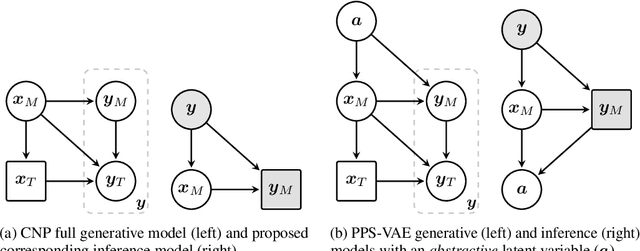
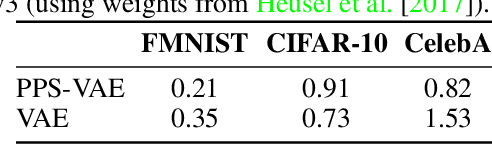
Conditional neural processes (CNPs) are a flexible and efficient family of models that learn to learn a stochastic process from observations. In the visual domain, they have seen particular application in contextual image completion - observing pixel values at some locations to predict a distribution over values at other unobserved locations. However, the choice of pixels in learning such a CNP is typically either random or derived from a simple statistical measure (e.g. pixel variance). Here, we turn the problem on its head and ask: which pixels would a CNP like to observe? That is, which pixels allow fitting CNP, and do such pixels tell us something about the underlying image? Viewing the context provided to the CNP as fixed-size latent representations, we construct an amortised variational framework, Partial Pixel Space Variational Autoencoder (PPS-VAE), for predicting this context simultaneously with learning a CNP. We evaluate PPS-VAE on a set of vision datasets, and find that not only is it possible to learn context points while also fitting CNPs, but that their spatial arrangement and values provides strong signal for the information contained in the image - evaluated through the lens of classification. We believe the PPS-VAE provides a promising avenue to explore learning interpretable and effective visual representations.
StrAE: Autoencoding for Pre-Trained Embeddings using Explicit Structure
May 09, 2023This work explores the utility of explicit structure for representation learning in NLP by developing StrAE -- an autoencoding framework that faithfully leverages sentence structure to learn multi-level node embeddings in an unsupervised fashion. We use StrAE to train models across different types of sentential structure and objectives, including a novel contrastive loss over structure, and evaluate the learnt embeddings on a series of both intrinsic and extrinsic tasks. Our experiments indicate that leveraging explicit structure through StrAE leads to improved embeddings over prior work, and that our novel contrastive objective over structure outperforms the standard cross-entropy objective. Moreover, in contrast to findings from prior work that weakly leverages structure, we find that being completely faithful to structure does enable disambiguation between types of structure based on the corresponding model's performance. As further evidence of StrAE's utility, we develop a simple proof-of-concept approach to simultaneously induce structure while learning embeddings, rather than being given structure, and find that performance is comparable to that of the best-performing models where structure is given. Finally, we contextualise these results by comparing StrAE against standard unstructured baselines learnt in similar settings, and show that faithfully leveraging explicit structure can be beneficial in lexical and sentence-level semantics.
Unsupervised Representation Disentanglement of Text: An Evaluation on Synthetic Datasets
Jun 07, 2021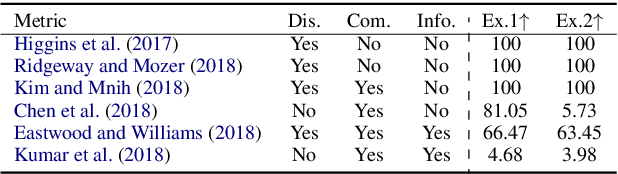
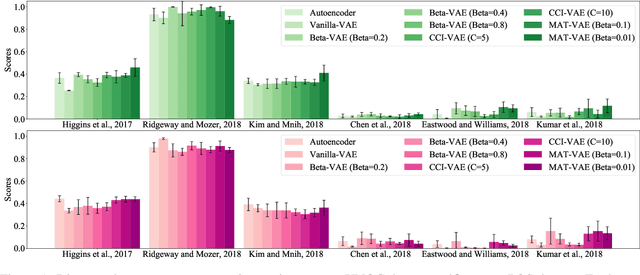

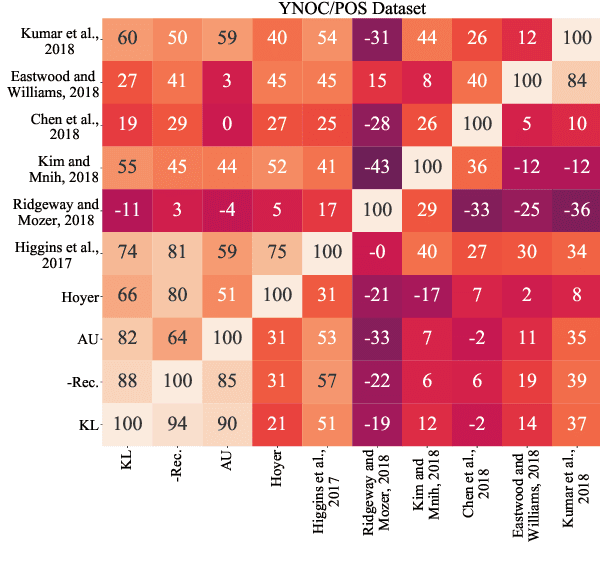
To highlight the challenges of achieving representation disentanglement for text domain in an unsupervised setting, in this paper we select a representative set of successfully applied models from the image domain. We evaluate these models on 6 disentanglement metrics, as well as on downstream classification tasks and homotopy. To facilitate the evaluation, we propose two synthetic datasets with known generative factors. Our experiments highlight the existing gap in the text domain and illustrate that certain elements such as representation sparsity (as an inductive bias), or representation coupling with the decoder could impact disentanglement. To the best of our knowledge, our work is the first attempt on the intersection of unsupervised representation disentanglement and text, and provides the experimental framework and datasets for examining future developments in this direction.
Hierarchical Sparse Variational Autoencoder for Text Encoding
Sep 25, 2020
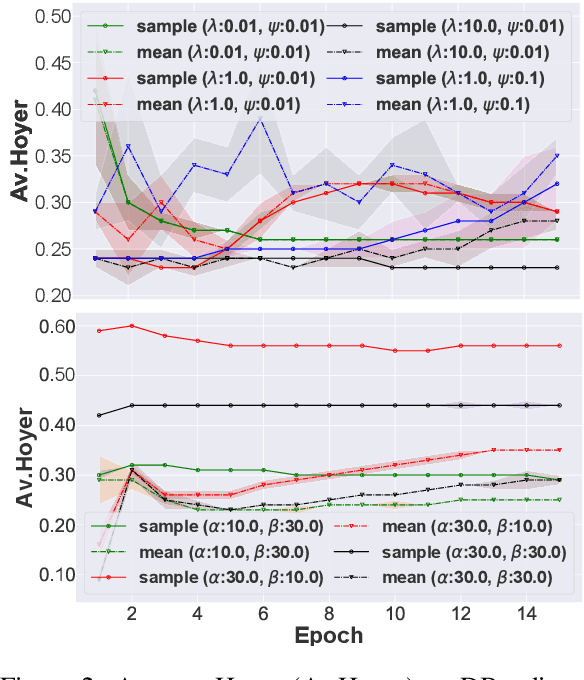

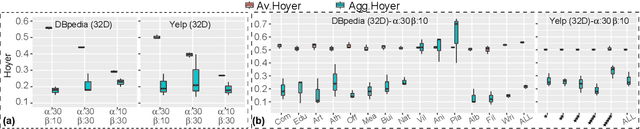
In this paper we focus on unsupervised representation learning and propose a novel framework, Hierarchical Sparse Variational Autoencoder (HSVAE), that imposes sparsity on sentence representations via direct optimisation of Evidence Lower Bound (ELBO). Our experimental results illustrate that HSVAE is flexible and adapts nicely to the underlying characteristics of the corpus which is reflected by the level of sparsity and its distributional patterns.
On the Importance of the Kullback-Leibler Divergence Term in Variational Autoencoders for Text Generation
Sep 30, 2019
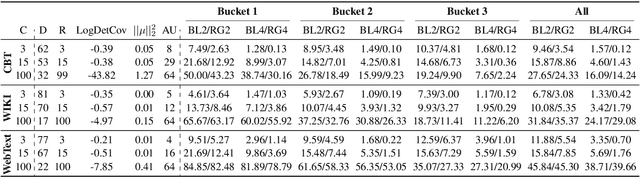
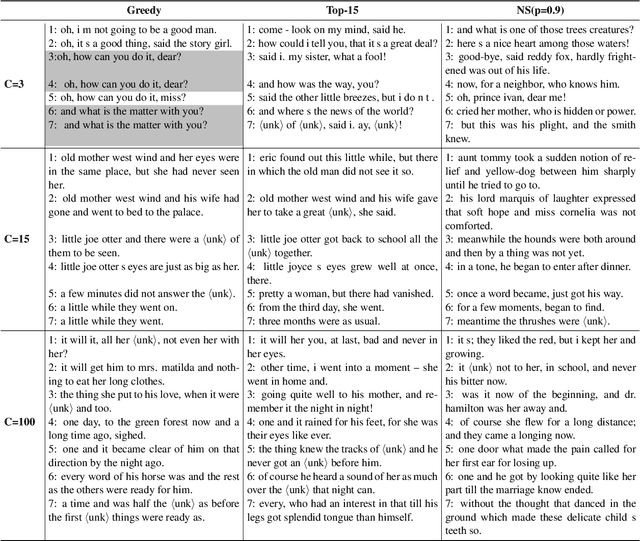
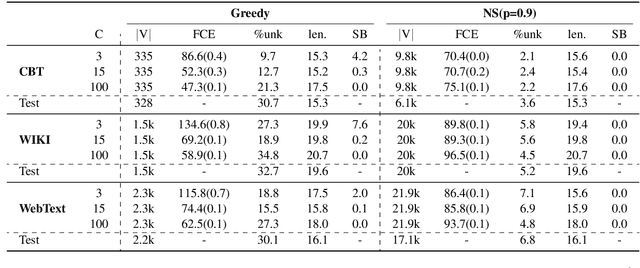
Variational Autoencoders (VAEs) are known to suffer from learning uninformative latent representation of the input due to issues such as approximated posterior collapse, or entanglement of the latent space. We impose an explicit constraint on the Kullback-Leibler (KL) divergence term inside the VAE objective function. While the explicit constraint naturally avoids posterior collapse, we use it to further understand the significance of the KL term in controlling the information transmitted through the VAE channel. Within this framework, we explore different properties of the estimated posterior distribution, and highlight the trade-off between the amount of information encoded in a latent code during training, and the generative capacity of the model.
Generating Knowledge Graph Paths from Textual Definitions using Sequence-to-Sequence Models
Apr 05, 2019
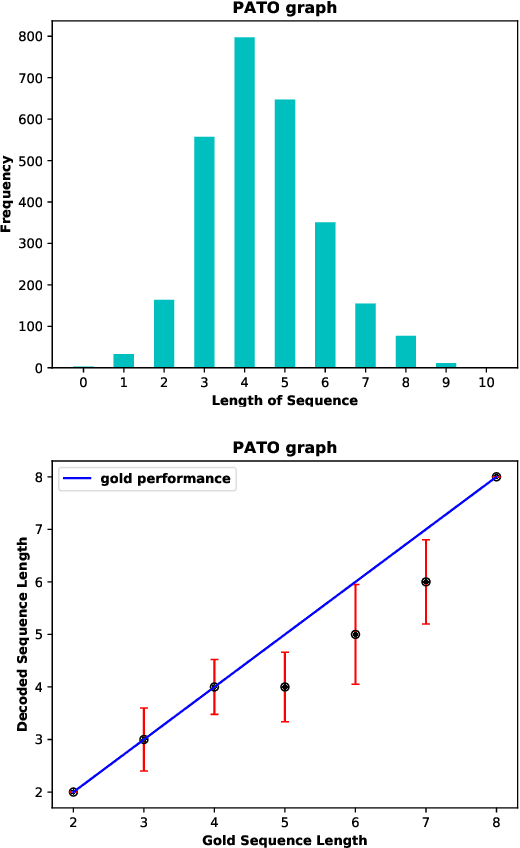
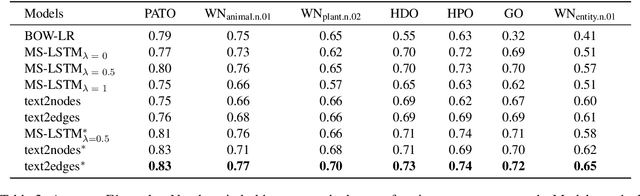

We present a novel method for mapping unrestricted text to knowledge graph entities by framing the task as a sequence-to-sequence problem. Specifically, given the encoded state of an input text, our decoder directly predicts paths in the knowledge graph, starting from the root and ending at the target node following hypernym-hyponym relationships. In this way, and in contrast to other text-to-entity mapping systems, our model outputs hierarchically structured predictions that are fully interpretable in the context of the underlying ontology, in an end-to-end manner. We present a proof-of-concept experiment with encouraging results, comparable to those of state-of-the-art systems.
Unseen Word Representation by Aligning Heterogeneous Lexical Semantic Spaces
Nov 12, 2018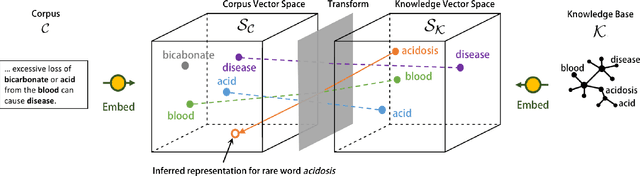

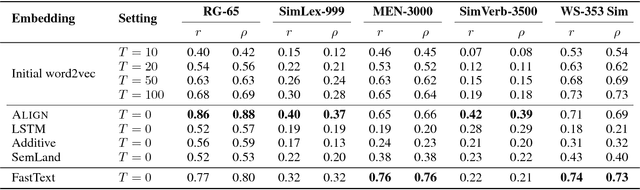
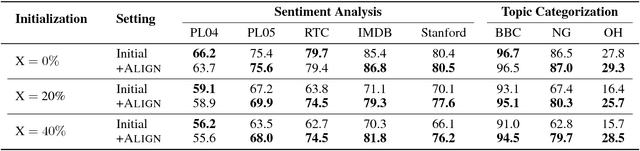
Word embedding techniques heavily rely on the abundance of training data for individual words. Given the Zipfian distribution of words in natural language texts, a large number of words do not usually appear frequently or at all in the training data. In this paper we put forward a technique that exploits the knowledge encoded in lexical resources, such as WordNet, to induce embeddings for unseen words. Our approach adapts graph embedding and cross-lingual vector space transformation techniques in order to merge lexical knowledge encoded in ontologies with that derived from corpus statistics. We show that the approach can provide consistent performance improvements across multiple evaluation benchmarks: in-vitro, on multiple rare word similarity datasets, and in-vivo, in two downstream text classification tasks.
Card-660: Cambridge Rare Word Dataset - a Reliable Benchmark for Infrequent Word Representation Models
Aug 28, 2018



Rare word representation has recently enjoyed a surge of interest, owing to the crucial role that effective handling of infrequent words can play in accurate semantic understanding. However, there is a paucity of reliable benchmarks for evaluation and comparison of these techniques. We show in this paper that the only existing benchmark (the Stanford Rare Word dataset) suffers from low-confidence annotations and limited vocabulary; hence, it does not constitute a solid comparison framework. In order to fill this evaluation gap, we propose CAmbridge Rare word Dataset (Card-660), an expert-annotated word similarity dataset which provides a highly reliable, yet challenging, benchmark for rare word representation techniques. Through a set of experiments we show that even the best mainstream word embeddings, with millions of words in their vocabularies, are unable to achieve performances higher than 0.43 (Pearson correlation) on the dataset, compared to a human-level upperbound of 0.90. We release the dataset and the annotation materials at https://pilehvar.github.io/card-660/.
Learning Rare Word Representations using Semantic Bridging
Jul 24, 2017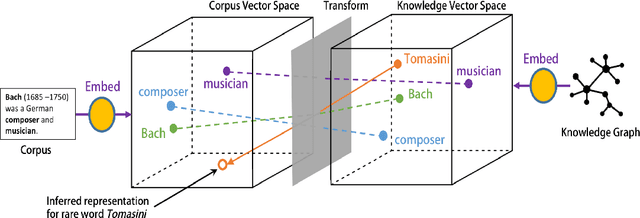

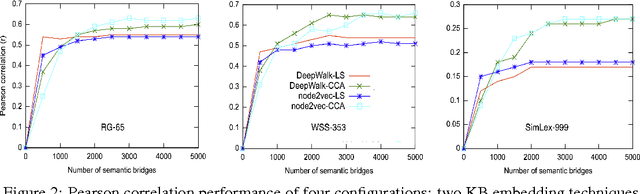

We propose a methodology that adapts graph embedding techniques (DeepWalk (Perozzi et al., 2014) and node2vec (Grover and Leskovec, 2016)) as well as cross-lingual vector space mapping approaches (Least Squares and Canonical Correlation Analysis) in order to merge the corpus and ontological sources of lexical knowledge. We also perform comparative analysis of the used algorithms in order to identify the best combination for the proposed system. We then apply this to the task of enhancing the coverage of an existing word embedding's vocabulary with rare and unseen words. We show that our technique can provide considerable extra coverage (over 99%), leading to consistent performance gain (around 10% absolute gain is achieved with w2v-gn-500K cf.\S 3.3) on the Rare Word Similarity dataset.