 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Feature Reuse Framework with Texture-adaptive Aggregation for Reference-based Super-Resolution
Jun 02, 2023Reference-based super-resolution (RefSR) has gained considerable success in the field of super-resolution with the addition of high-resolution reference images to reconstruct low-resolution (LR) inputs with more high-frequency details, thereby overcoming some limitations of single image super-resolution (SISR). Previous research in the field of RefSR has mostly focused on two crucial aspects. The first is accurate correspondence matching between the LR and the reference (Ref) image. The second is the effective transfer and aggregation of similar texture information from the Ref images. Nonetheless, an important detail of perceptual loss and adversarial loss has been underestimated, which has a certain adverse effect on texture transfer and reconstruction. In this study, we propose a feature reuse framework that guides the step-by-step texture reconstruction process through different stages, reducing the negative impacts of perceptual and adversarial loss. The feature reuse framework can be used for any RefSR model, and several RefSR approaches have improved their performance after being retrained using our framework. Additionally, we introduce a single image feature embedding module and a texture-adaptive aggregation module. The single image feature embedding module assists in reconstructing the features of the LR inputs itself and effectively lowers the possibility of including irrelevant textures. The texture-adaptive aggregation module dynamically perceives and aggregates texture information between the LR inputs and the Ref images using dynamic filters. This enhances the utilization of the reference texture while reducing reference misuse. The source code is available at https://github.com/Yi-Yang355/FRFSR.
Structure-based Drug Design with Equivariant Diffusion Models
Oct 24, 2022Structure-based drug design (SBDD) aims to design small-molecule ligands that bind with high affinity and specificity to pre-determined protein targets. Traditional SBDD pipelines start with large-scale docking of compound libraries from public databases, thus limiting the exploration of chemical space to existent previously studied regions. Recent machine learning methods approached this problem using an atom-by-atom generation approach, which is computationally expensive. In this paper, we formulate SBDD as a 3D-conditional generation problem and present DiffSBDD, an E(3)-equivariant 3D-conditional diffusion model that generates novel ligands conditioned on protein pockets. Furthermore, we curate a new dataset of experimentally determined binding complex data from Binding MOAD to provide a realistic binding scenario that complements the synthetic CrossDocked dataset. Comprehensive in silico experiments demonstrate the efficiency of DiffSBDD in generating novel and diverse drug-like ligands that engage protein pockets with high binding energies as predicted by in silico docking.
Global Concept-Based Interpretability for Graph Neural Networks via Neuron Analysis
Aug 22, 2022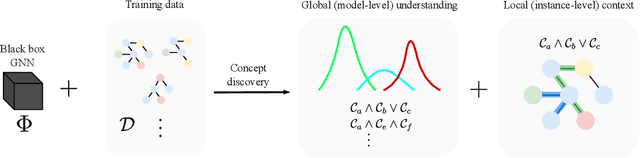
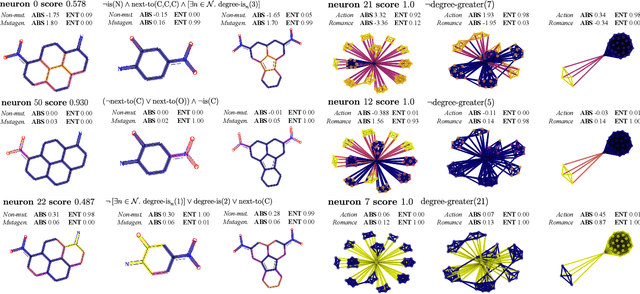
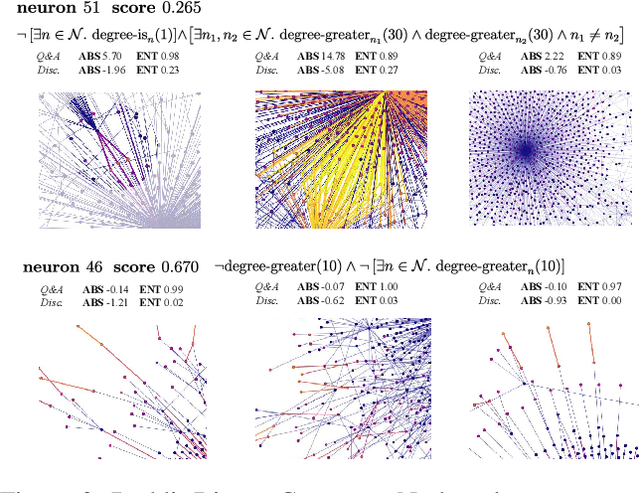
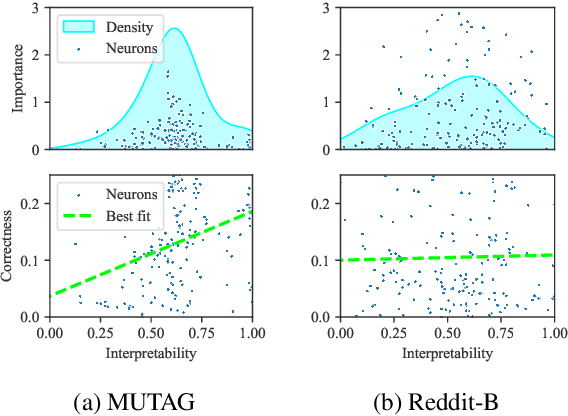
Graph neural networks (GNNs) are highly effective on a variety of graph-related tasks; however, they lack interpretability and transparency. Current explainability approaches are typically local and treat GNNs as black-boxes. They do not look inside the model, inhibiting human trust in the model and explanations. Motivated by the ability of neurons to detect high-level semantic concepts in vision models, we perform a novel analysis on the behaviour of individual GNN neurons to answer questions about GNN interpretability, and propose new metrics for evaluating the interpretability of GNN neurons. We propose a novel approach for producing global explanations for GNNs using neuron-level concepts to enable practitioners to have a high-level view of the model. Specifically, (i) to the best of our knowledge, this is the first work which shows that GNN neurons act as concept detectors and have strong alignment with concepts formulated as logical compositions of node degree and neighbourhood properties; (ii) we quantitatively assess the importance of detected concepts, and identify a trade-off between training duration and neuron-level interpretability; (iii) we demonstrate that our global explainability approach has advantages over the current state-of-the-art -- we can disentangle the explanation into individual interpretable concepts backed by logical descriptions, which reduces potential for bias and improves user-friendliness.
Approximate Latent Force Model Inference
Sep 24, 2021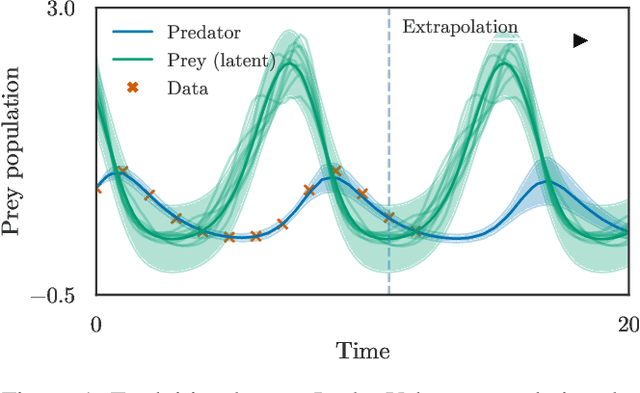

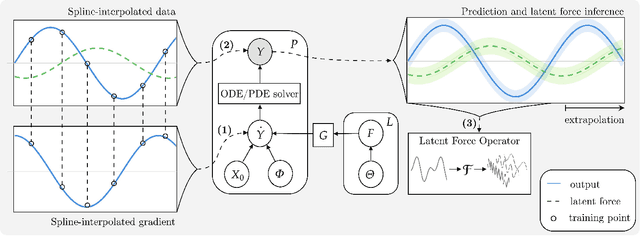
Physically-inspired latent force models offer an interpretable alternative to purely data driven tools for inference in dynamical systems. They carry the structure of differential equations and the flexibility of Gaussian processes, yielding interpretable parameters and dynamics-imposed latent functions. However, the existing inference techniques associated with these models rely on the exact computation of posterior kernel terms which are seldom available in analytical form. Most applications relevant to practitioners, such as Hill equations or diffusion equations, are hence intractable. In this paper, we overcome these computational problems by proposing a variational solution to a general class of non-linear and parabolic partial differential equation latent force models. Further, we show that a neural operator approach can scale our model to thousands of instances, enabling fast, distributed computation. We demonstrate the efficacy and flexibility of our framework by achieving competitive performance on several tasks where the kernels are of varying degrees of tractability.
Logic Explained Networks
Aug 11, 2021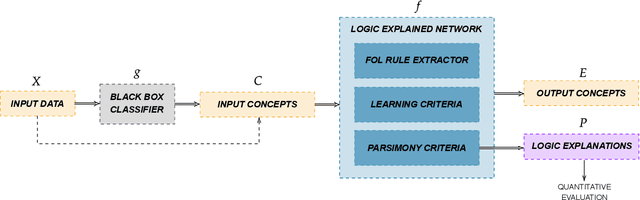

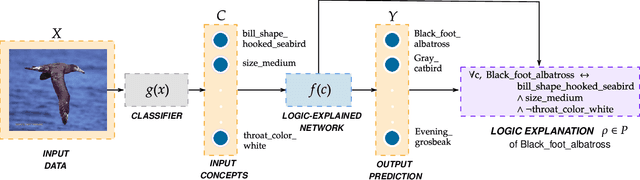

The large and still increasing popularity of deep learning clashes with a major limit of neural network architectures, that consists in their lack of capability in providing human-understandable motivations of their decisions. In situations in which the machine is expected to support the decision of human experts, providing a comprehensible explanation is a feature of crucial importance. The language used to communicate the explanations must be formal enough to be implementable in a machine and friendly enough to be understandable by a wide audience. In this paper, we propose a general approach to Explainable Artificial Intelligence in the case of neural architectures, showing how a mindful design of the networks leads to a family of interpretable deep learning models called Logic Explained Networks (LENs). LENs only require their inputs to be human-understandable predicates, and they provide explanations in terms of simple First-Order Logic (FOL) formulas involving such predicates. LENs are general enough to cover a large number of scenarios. Amongst them, we consider the case in which LENs are directly used as special classifiers with the capability of being explainable, or when they act as additional networks with the role of creating the conditions for making a black-box classifier explainable by FOL formulas. Despite supervised learning problems are mostly emphasized, we also show that LENs can learn and provide explanations in unsupervised learning settings. Experimental results on several datasets and tasks show that LENs may yield better classifications than established white-box models, such as decision trees and Bayesian rule lists, while providing more compact and meaningful explanations.
Entropy-based Logic Explanations of Neural Networks
Jun 22, 2021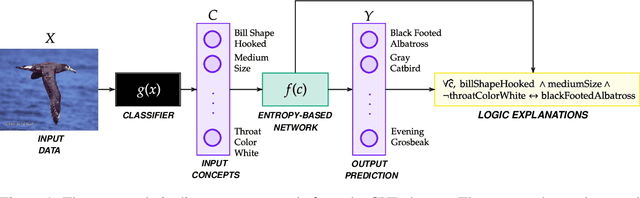
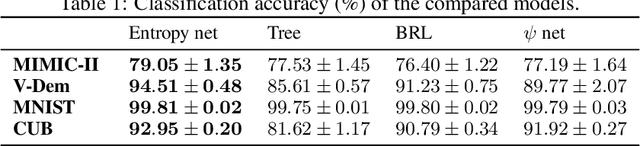
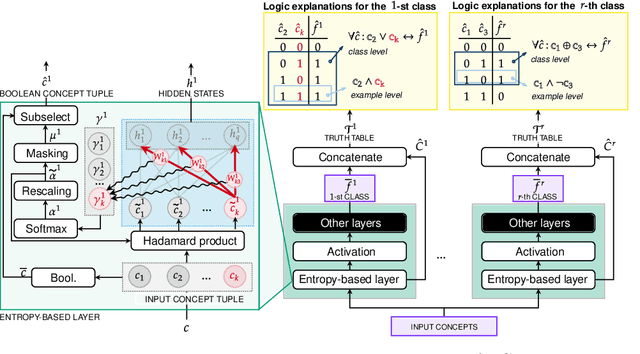
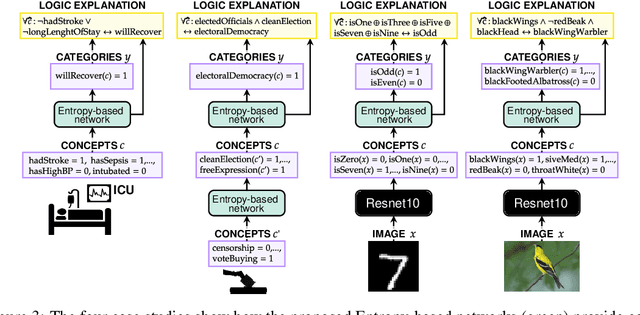
Explainable artificial intelligence has rapidly emerged since lawmakers have started requiring interpretable models for safety-critical domains. Concept-based neural networks have arisen as explainable-by-design methods as they leverage human-understandable symbols (i.e. concepts) to predict class memberships. However, most of these approaches focus on the identification of the most relevant concepts but do not provide concise, formal explanations of how such concepts are leveraged by the classifier to make predictions. In this paper, we propose a novel end-to-end differentiable approach enabling the extraction of logic explanations from neural networks using the formalism of First-Order Logic. The method relies on an entropy-based criterion which automatically identifies the most relevant concepts. We consider four different case studies to demonstrate that: (i) this entropy-based criterion enables the distillation of concise logic explanations in safety-critical domains from clinical data to computer vision; (ii) the proposed approach outperforms state-of-the-art white-box models in terms of classification accuracy.
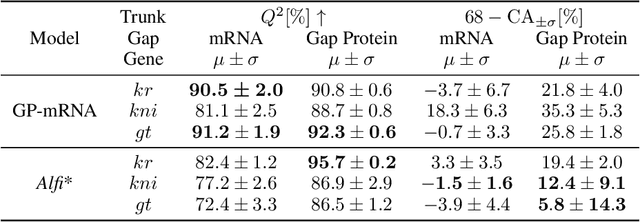
Gene Regulatory Network Inference with Latent Force Models
Oct 06, 2020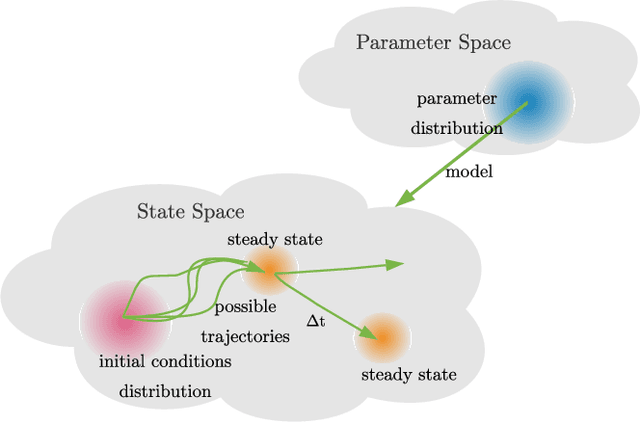

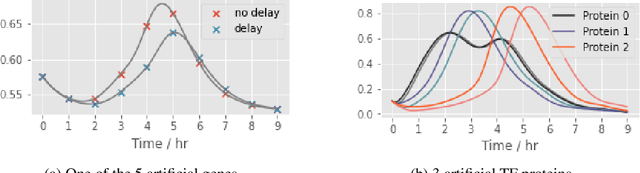
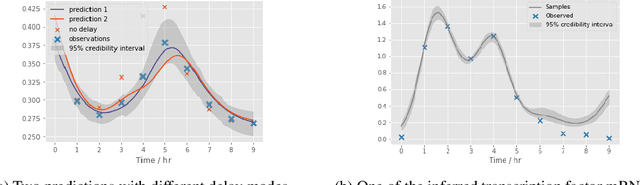
Delays in protein synthesis cause a confounding effect when constructing Gene Regulatory Networks (GRNs) from RNA-sequencing time-series data. Accurate GRNs can be very insightful when modelling development, disease pathways, and drug side-effects. We present a model which incorporates translation delays by combining mechanistic equations and Bayesian approaches to fit to experimental data. This enables greater biological interpretability, and the use of Gaussian processes enables non-linear expressivity through kernels as well as naturally accounting for biological variation.
Graph representation forecasting of patient's medical conditions: towards a digital twin
Sep 17, 2020
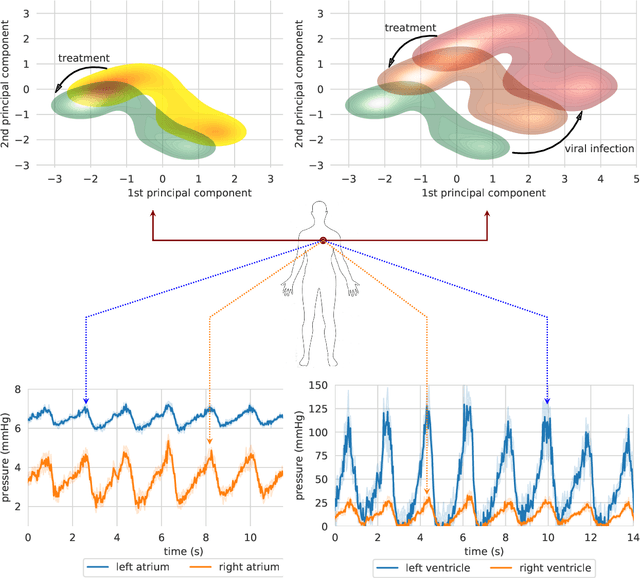
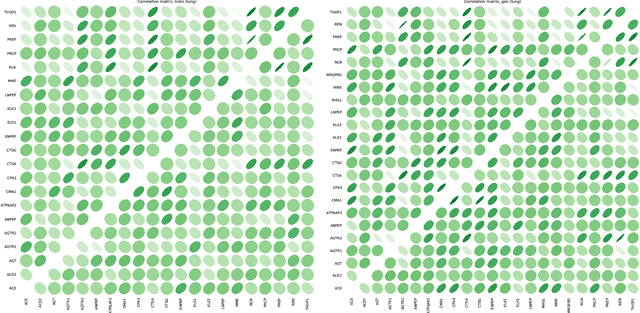
Objective: Modern medicine needs to shift from a wait and react, curative discipline to a preventative, interdisciplinary science aiming at providing personalised, systemic and precise treatment plans to patients. The aim of this work is to present how the integration of machine learning approaches with mechanistic computational modelling could yield a reliable infrastructure to run probabilistic simulations where the entire organism is considered as a whole. Methods: We propose a general framework that composes advanced AI approaches and integrates mathematical modelling in order to provide a panoramic view over current and future physiological conditions. The proposed architecture is based on a graph neural network (GNNs) forecasting clinically relevant endpoints (such as blood pressure) and a generative adversarial network (GANs) providing a proof of concept of transcriptomic integrability. Results: We show the results of the investigation of pathological effects of overexpression of ACE2 across different signalling pathways in multiple tissues on cardiovascular functions. We provide a proof of concept of integrating a large set of composable clinical models using molecular data to drive local and global clinical parameters and derive future trajectories representing the evolution of the physiological state of the patient. Significance: We argue that the graph representation of a computational patient has potential to solve important technological challenges in integrating multiscale computational modelling with AI. We believe that this work represents a step forward towards a healthcare digital twin.
Perturbation theory approach to study the latent space degeneracy of Variational Autoencoders
Jul 10, 2019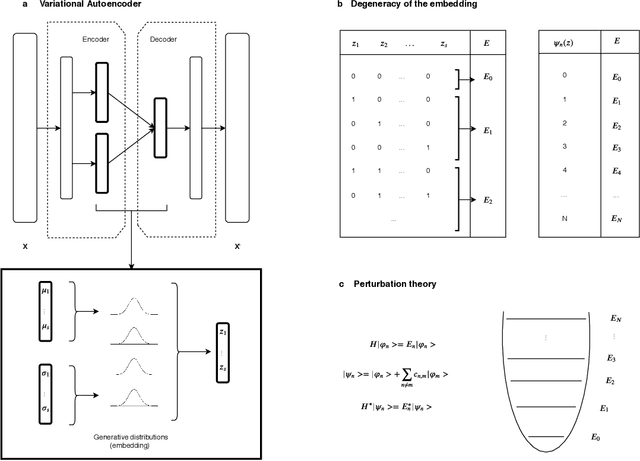
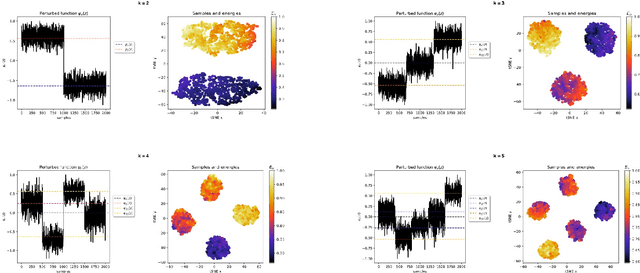
The use of Variational Autoencoders in different Machine Learning tasks has drastically increased in the last years. They have been developed as denoising, clustering and generative tools, highlighting a large potential in a wide range of fields. Their embeddings are able to extract relevant information from highly dimensional inputs, but the converged models can differ significantly and lead to degeneracy on the latent space. We leverage the relation between theoretical physics and machine learning to explain this behaviour, and introduce a new approach to correct for degeneration by using perturbation theory. The re-formulation of the embedding as multi-dimensional generative distribution, allows mapping to a new set of functions and their corresponding energy spectrum. We optimise for a perturbed Hamiltonian, with an additional energy potential that is related to the unobserved topology of the data. Our results show the potential of a new theoretical approach that can be used to interpret the latent space and generative nature of unsupervised learning, while the energy landscapes defined by the perturbations can be further used for modelling and dynamical purposes.
Factorised Neural Relational Inference for Multi-Interaction Systems
May 21, 2019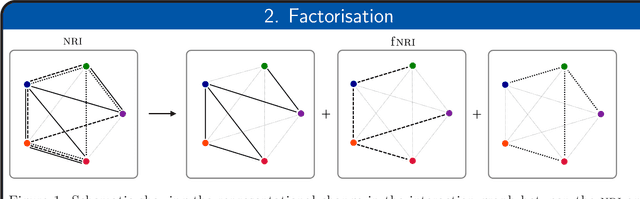
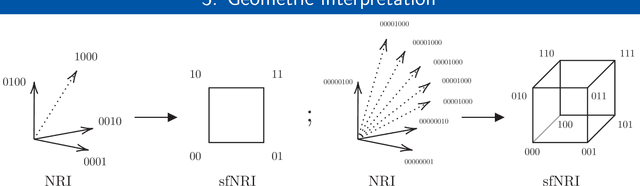
Many complex natural and cultural phenomena are well modelled by systems of simple interactions between particles. A number of architectures have been developed to articulate this kind of structure, both implicitly and explicitly. We consider an unsupervised explicit model, the NRI model, and make a series of representational adaptations and physically motivated changes. Most notably we factorise the inferred latent interaction graph into a multiplex graph, allowing each layer to encode for a different interaction-type. This fNRI model is smaller in size and significantly outperforms the original in both edge and trajectory prediction, establishing a new state-of-the-art. We also present a simplified variant of our model, which demonstrates the NRI's formulation as a variational auto-encoder is not necessary for good performance, and make an adaptation to the NRI's training routine, significantly improving its ability to model complex physical dynamical systems.