 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-label feature selection based on binary hashing learning and dynamic graph constraints
Mar 18, 2025



Multi-label learning poses significant challenges in extracting reliable supervisory signals from the label space. Existing approaches often employ continuous pseudo-labels to replace binary labels, improving supervisory information representation. However, these methods can introduce noise from irrelevant labels and lead to unreliable graph structures. To overcome these limitations, this study introduces a novel multi-label feature selection method called Binary Hashing and Dynamic Graph Constraint (BHDG), the first method to integrate binary hashing into multi-label learning. BHDG utilizes low-dimensional binary hashing codes as pseudo-labels to reduce noise and improve representation robustness. A dynamically constrained sample projection space is constructed based on the graph structure of these binary pseudo-labels, enhancing the reliability of the dynamic graph. To further enhance pseudo-label quality, BHDG incorporates label graph constraints and inner product minimization within the sample space. Additionally, an $l_{2,1}$-norm regularization term is added to the objective function to facilitate the feature selection process. The augmented Lagrangian multiplier (ALM) method is employed to optimize binary variables effectively. Comprehensive experiments on 10 benchmark datasets demonstrate that BHDG outperforms ten state-of-the-art methods across six evaluation metrics. BHDG achieves the highest overall performance ranking, surpassing the next-best method by an average of at least 2.7 ranks per metric, underscoring its effectiveness and robustness in multi-label feature selection.
Out-of-Distribution Detection on Graphs: A Survey
Feb 12, 2025Graph machine learning has witnessed rapid growth, driving advancements across diverse domains. However, the in-distribution assumption, where training and testing data share the same distribution, often breaks in real-world scenarios, leading to degraded model performance under distribution shifts. This challenge has catalyzed interest in graph out-of-distribution (GOOD) detection, which focuses on identifying graph data that deviates from the distribution seen during training, thereby enhancing model robustness. In this paper, we provide a rigorous definition of GOOD detection and systematically categorize existing methods into four types: enhancement-based, reconstruction-based, information propagation-based, and classification-based approaches. We analyze the principles and mechanisms of each approach and clarify the distinctions between GOOD detection and related fields, such as graph anomaly detection, outlier detection, and GOOD generalization. Beyond methodology, we discuss practical applications and theoretical foundations, highlighting the unique challenges posed by graph data. Finally, we discuss the primary challenges and propose future directions to advance this emerging field. The repository of this survey is available at https://github.com/ca1man-2022/Awesome-GOOD-Detection.
ChatPRCS: A Personalized Support System for English Reading Comprehension based on ChatGPT
Sep 25, 2023



As a common approach to learning English, reading comprehension primarily entails reading articles and answering related questions. However, the complexity of designing effective exercises results in students encountering standardized questions, making it challenging to align with individualized learners' reading comprehension ability. By leveraging the advanced capabilities offered by large language models, exemplified by ChatGPT, this paper presents a novel personalized support system for reading comprehension, referred to as ChatPRCS, based on the Zone of Proximal Development theory. ChatPRCS employs methods including reading comprehension proficiency prediction, question generation, and automatic evaluation, among others, to enhance reading comprehension instruction. First, we develop a new algorithm that can predict learners' reading comprehension abilities using their historical data as the foundation for generating questions at an appropriate level of difficulty. Second, a series of new ChatGPT prompt patterns is proposed to address two key aspects of reading comprehension objectives: question generation, and automated evaluation. These patterns further improve the quality of generated questions. Finally, by integrating personalized ability and reading comprehension prompt patterns, ChatPRCS is systematically validated through experiments. Empirical results demonstrate that it provides learners with high-quality reading comprehension questions that are broadly aligned with expert-crafted questions at a statistical level.
A Feature Reuse Framework with Texture-adaptive Aggregation for Reference-based Super-Resolution
Jun 02, 2023Reference-based super-resolution (RefSR) has gained considerable success in the field of super-resolution with the addition of high-resolution reference images to reconstruct low-resolution (LR) inputs with more high-frequency details, thereby overcoming some limitations of single image super-resolution (SISR). Previous research in the field of RefSR has mostly focused on two crucial aspects. The first is accurate correspondence matching between the LR and the reference (Ref) image. The second is the effective transfer and aggregation of similar texture information from the Ref images. Nonetheless, an important detail of perceptual loss and adversarial loss has been underestimated, which has a certain adverse effect on texture transfer and reconstruction. In this study, we propose a feature reuse framework that guides the step-by-step texture reconstruction process through different stages, reducing the negative impacts of perceptual and adversarial loss. The feature reuse framework can be used for any RefSR model, and several RefSR approaches have improved their performance after being retrained using our framework. Additionally, we introduce a single image feature embedding module and a texture-adaptive aggregation module. The single image feature embedding module assists in reconstructing the features of the LR inputs itself and effectively lowers the possibility of including irrelevant textures. The texture-adaptive aggregation module dynamically perceives and aggregates texture information between the LR inputs and the Ref images using dynamic filters. This enhances the utilization of the reference texture while reducing reference misuse. The source code is available at https://github.com/Yi-Yang355/FRFSR.
On the Approximation Lower Bound for Neural Nets with Random Weights
Aug 19, 2020

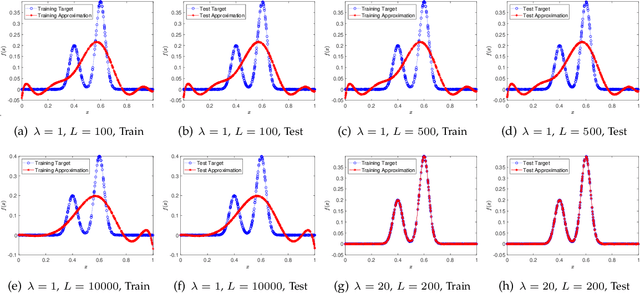
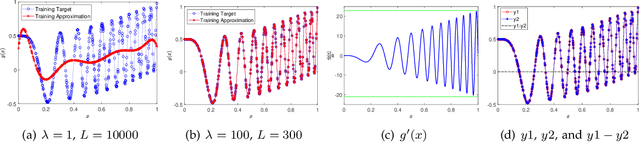
A random net is a shallow neural network where the hidden layer is frozen with random assignment and the output layer is trained by convex optimization. Using random weights for a hidden layer is an effective method to avoid the inevitable non-convexity in standard gradient descent learning. It has recently been adopted in the study of deep learning theory. Here, we investigate the expressive power of random nets. We show that, despite the well-known fact that a shallow neural network is a universal approximator, a random net cannot achieve zero approximation error even for smooth functions. In particular, we prove that for a class of smooth functions, if the proposal distribution is compactly supported, then a lower bound is positive. Based on the ridgelet analysis and harmonic analysis for neural networks, the proof uses the Plancherel theorem and an estimate for the truncated tail of the parameter distribution. We corroborate our theoretical results with various simulation studies, and generally two main take-home messages are offered: (i) Not any distribution for selecting random weights is feasible to build a universal approximator; (ii) A suitable assignment of random weights exists but to some degree is associated with the complexity of the target function.