 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Charging Optimization of Inhomogeneous Dicke Quantum Batteries
Nov 15, 2025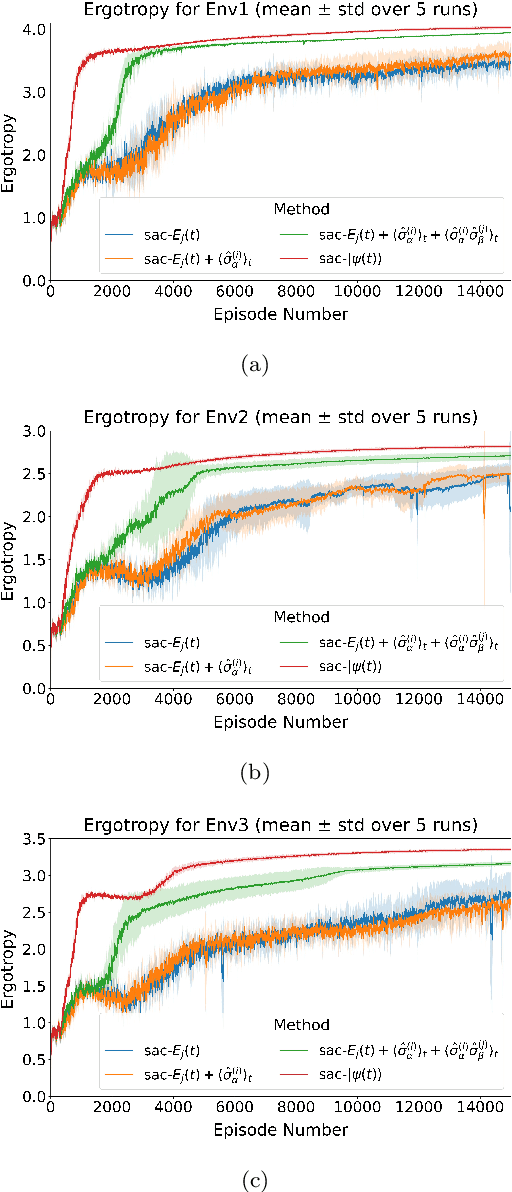
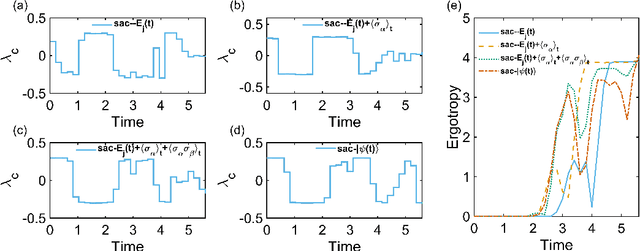
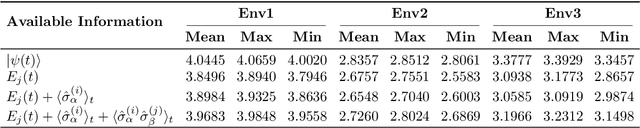
Charging optimization is a key challenge to the implementation of quantum batteries, particularly under inhomogeneity and partial observability. This paper employs reinforcement learning to optimize piecewise-constant charging policies for an inhomogeneous Dicke battery. We systematically compare policies across four observability regimes, from full-state access to experimentally accessible observables (energies of individual two-level systems (TLSs), first-order averages, and second-order correlations). Simulation results demonstrate that full observability yields near-optimal ergotropy with low variability, while under partial observability, access to only single-TLS energies or energies plus first-order averages lags behind the fully observed baseline. However, augmenting partial observations with second-order correlations recovers most of the gap, reaching 94%-98% of the full-state baseline. The learned schedules are nonmyopic, trading temporary plateaus or declines for superior terminal outcomes. These findings highlight a practical route to effective fast-charging protocols under realistic information constraints.
A Memetic Walrus Algorithm with Expert-guided Strategy for Adaptive Curriculum Sequencing
Jun 16, 2025Adaptive Curriculum Sequencing (ACS) is essential for personalized online learning, yet current approaches struggle to balance complex educational constraints and maintain optimization stability. This paper proposes a Memetic Walrus Optimizer (MWO) that enhances optimization performance through three key innovations: (1) an expert-guided strategy with aging mechanism that improves escape from local optima; (2) an adaptive control signal framework that dynamically balances exploration and exploitation; and (3) a three-tier priority mechanism for generating educationally meaningful sequences. We formulate ACS as a multi-objective optimization problem considering concept coverage, time constraints, and learning style compatibility. Experiments on the OULAD dataset demonstrate MWO's superior performance, achieving 95.3% difficulty progression rate (compared to 87.2% in baseline methods) and significantly better convergence stability (standard deviation of 18.02 versus 28.29-696.97 in competing algorithms). Additional validation on benchmark functions confirms MWO's robust optimization capability across diverse scenarios. The results demonstrate MWO's effectiveness in generating personalized learning sequences while maintaining computational efficiency and solution quality.
Towards Class-wise Fair Adversarial Training via Anti-Bias Soft Label Distillation
Jun 10, 2025Adversarial Training (AT) is widely recognized as an effective approach to enhance the adversarial robustness of Deep Neural Networks. As a variant of AT, Adversarial Robustness Distillation (ARD) has shown outstanding performance in enhancing the robustness of small models. However, both AT and ARD face robust fairness issue: these models tend to display strong adversarial robustness against some classes (easy classes) while demonstrating weak adversarial robustness against others (hard classes). This paper explores the underlying factors of this problem and points out the smoothness degree of soft labels for different classes significantly impacts the robust fairness from both empirical observation and theoretical analysis. Based on the above exploration, we propose Anti-Bias Soft Label Distillation (ABSLD) within the Knowledge Distillation framework to enhance the adversarial robust fairness. Specifically, ABSLD adaptively reduces the student's error risk gap between different classes, which is accomplished by adjusting the class-wise smoothness degree of teacher's soft labels during the training process, and the adjustment is managed by assigning varying temperatures to different classes. Additionally, as a label-based approach, ABSLD is highly adaptable and can be integrated with the sample-based methods. Extensive experiments demonstrate ABSLD outperforms state-of-the-art methods on the comprehensive performance of robustness and fairness.
Improving Adversarial Robust Fairness via Anti-Bias Soft Label Distillation
Dec 09, 2023Adversarial Training (AT) has been widely proved to be an effective method to improve the adversarial robustness against adversarial examples for Deep Neural Networks (DNNs). As a variant of AT, Adversarial Robustness Distillation (ARD) has demonstrated its superior performance in improving the robustness of small student models with the guidance of large teacher models. However, both AT and ARD encounter the robust fairness problem: these models exhibit strong robustness when facing part of classes (easy class), but weak robustness when facing others (hard class). In this paper, we give an in-depth analysis of the potential factors and argue that the smoothness degree of samples' soft labels for different classes (i.e., hard class or easy class) will affect the robust fairness of DNN models from both empirical observation and theoretical analysis. Based on the above finding, we propose an Anti-Bias Soft Label Distillation (ABSLD) method to mitigate the adversarial robust fairness problem within the framework of Knowledge Distillation (KD). Specifically, ABSLD adaptively reduces the student's error risk gap between different classes to achieve fairness by adjusting the class-wise smoothness degree of samples' soft labels during the training process, and the smoothness degree of soft labels is controlled by assigning different temperatures in KD to different classes. Extensive experiments demonstrate that ABSLD outperforms state-of-the-art AT, ARD, and robust fairness methods in terms of overall performance of robustness and fairness.
ChatPRCS: A Personalized Support System for English Reading Comprehension based on ChatGPT
Sep 25, 2023



As a common approach to learning English, reading comprehension primarily entails reading articles and answering related questions. However, the complexity of designing effective exercises results in students encountering standardized questions, making it challenging to align with individualized learners' reading comprehension ability. By leveraging the advanced capabilities offered by large language models, exemplified by ChatGPT, this paper presents a novel personalized support system for reading comprehension, referred to as ChatPRCS, based on the Zone of Proximal Development theory. ChatPRCS employs methods including reading comprehension proficiency prediction, question generation, and automatic evaluation, among others, to enhance reading comprehension instruction. First, we develop a new algorithm that can predict learners' reading comprehension abilities using their historical data as the foundation for generating questions at an appropriate level of difficulty. Second, a series of new ChatGPT prompt patterns is proposed to address two key aspects of reading comprehension objectives: question generation, and automated evaluation. These patterns further improve the quality of generated questions. Finally, by integrating personalized ability and reading comprehension prompt patterns, ChatPRCS is systematically validated through experiments. Empirical results demonstrate that it provides learners with high-quality reading comprehension questions that are broadly aligned with expert-crafted questions at a statistical level.
Mitigating the Accuracy-Robustness Trade-off via Multi-Teacher Adversarial Distillation
Jul 11, 2023Adversarial training is a practical approach for improving the robustness of deep neural networks against adversarial attacks. Although bringing reliable robustness, the performance toward clean examples is negatively affected after adversarial training, which means a trade-off exists between accuracy and robustness. Recently, some studies have tried to use knowledge distillation methods in adversarial training, achieving competitive performance in improving the robustness but the accuracy for clean samples is still limited. In this paper, to mitigate the accuracy-robustness trade-off, we introduce the Multi-Teacher Adversarial Robustness Distillation (MTARD) to guide the model's adversarial training process by applying a strong clean teacher and a strong robust teacher to handle the clean examples and adversarial examples, respectively. During the optimization process, to ensure that different teachers show similar knowledge scales, we design the Entropy-Based Balance algorithm to adjust the teacher's temperature and keep the teachers' information entropy consistent. Besides, to ensure that the student has a relatively consistent learning speed from multiple teachers, we propose the Normalization Loss Balance algorithm to adjust the learning weights of different types of knowledge. A series of experiments conducted on public datasets demonstrate that MTARD outperforms the state-of-the-art adversarial training and distillation methods against various adversarial attacks.
A Knowledge-Based Decision Support System for In Vitro Fertilization Treatment
Jan 27, 2022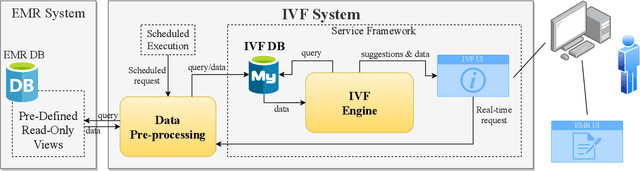
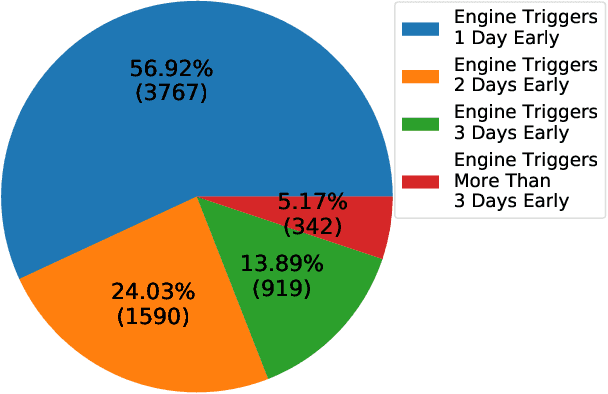
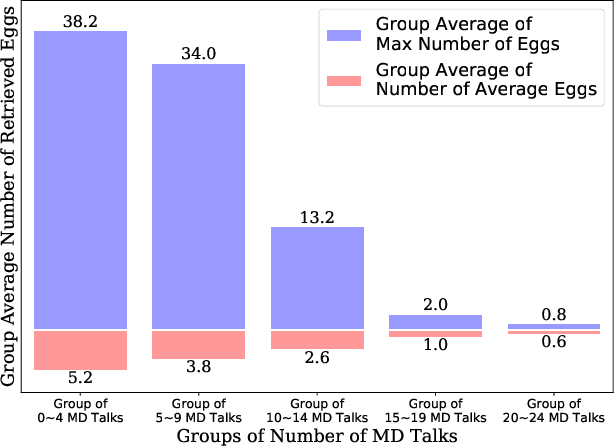
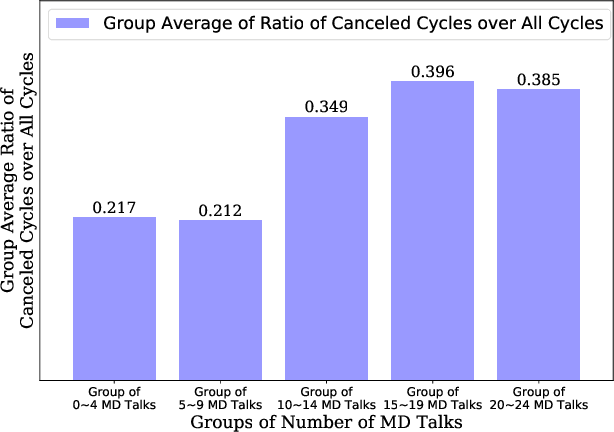
In Vitro Fertilization (IVF) is the most widely used Assisted Reproductive Technology (ART). IVF usually involves controlled ovarian stimulation, oocyte retrieval, fertilization in the laboratory with subsequent embryo transfer. The first two steps correspond with follicular phase of females and ovulation in their menstrual cycle. Therefore, we refer to it as the treatment cycle in our paper. The treatment cycle is crucial because the stimulation medications in IVF treatment are applied directly on patients. In order to optimize the stimulation effects and lower the side effects of the stimulation medications, prompt treatment adjustments are in need. In addition, the quality and quantity of the retrieved oocytes have a significant effect on the outcome of the following procedures. To improve the IVF success rate, we propose a knowledge-based decision support system that can provide medical advice on the treatment protocol and medication adjustment for each patient visit during IVF treatment cycle. Our system is efficient in data processing and light-weighted which can be easily embedded into electronic medical record systems. Moreover, an oocyte retrieval oriented evaluation demonstrates that our system performs well in terms of accuracy of advice for the protocols and medications.