 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Adversarial Robust Fairness via Anti-Bias Soft Label Distillation
Paper and Code
Dec 09, 2023
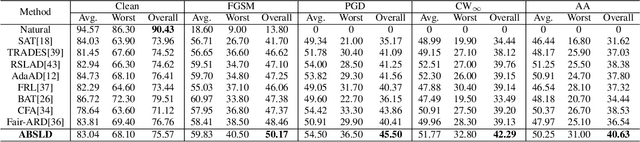


Adversarial Training (AT) has been widely proved to be an effective method to improve the adversarial robustness against adversarial examples for Deep Neural Networks (DNNs). As a variant of AT, Adversarial Robustness Distillation (ARD) has demonstrated its superior performance in improving the robustness of small student models with the guidance of large teacher models. However, both AT and ARD encounter the robust fairness problem: these models exhibit strong robustness when facing part of classes (easy class), but weak robustness when facing others (hard class). In this paper, we give an in-depth analysis of the potential factors and argue that the smoothness degree of samples' soft labels for different classes (i.e., hard class or easy class) will affect the robust fairness of DNN models from both empirical observation and theoretical analysis. Based on the above finding, we propose an Anti-Bias Soft Label Distillation (ABSLD) method to mitigate the adversarial robust fairness problem within the framework of Knowledge Distillation (KD). Specifically, ABSLD adaptively reduces the student's error risk gap between different classes to achieve fairness by adjusting the class-wise smoothness degree of samples' soft labels during the training process, and the smoothness degree of soft labels is controlled by assigning different temperatures in KD to different classes. Extensive experiments demonstrate that ABSLD outperforms state-of-the-art AT, ARD, and robust fairness methods in terms of overall performance of robustness and fairness.