 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential-informed Sample Selection Accelerates Multimodal Contrastive Learning
Jul 17, 2025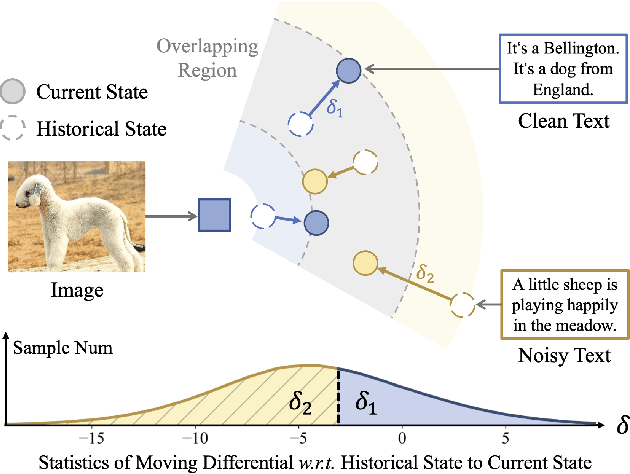
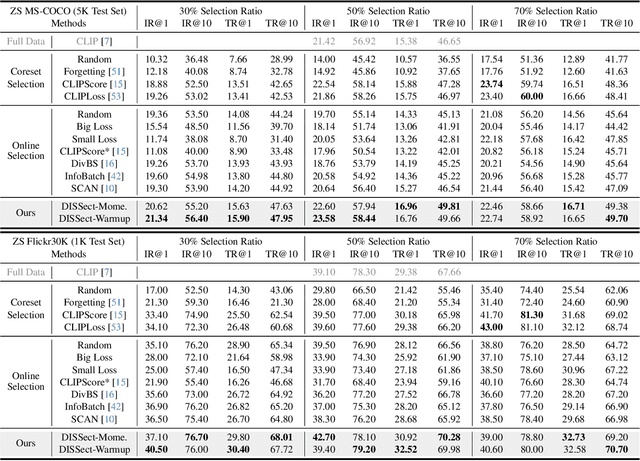
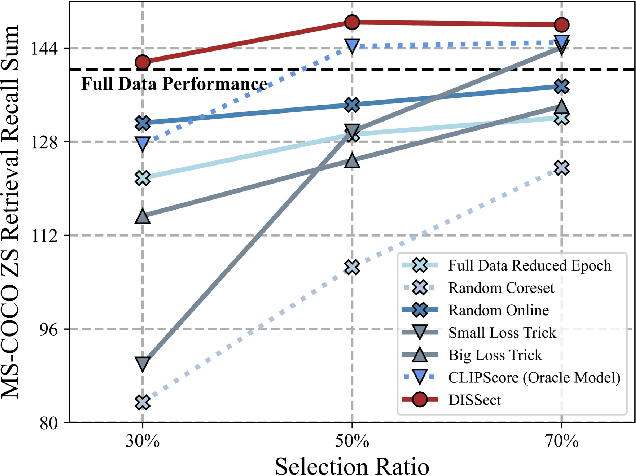
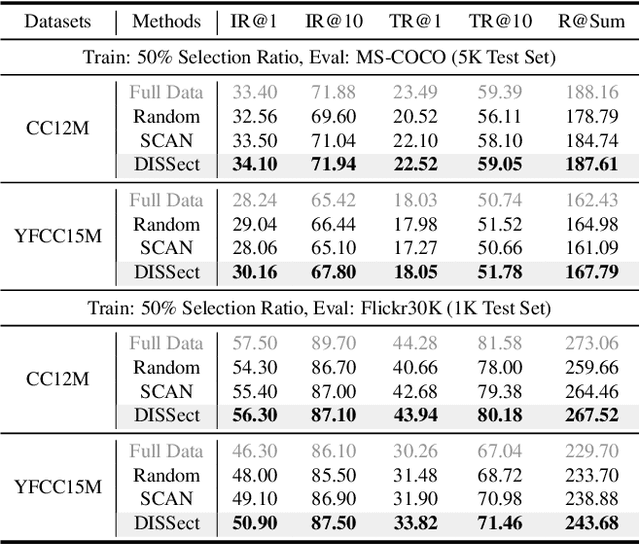
The remarkable success of contrastive-learning-based multimodal models has been greatly driven by training on ever-larger datasets with expensive compute consumption. Sample selection as an alternative efficient paradigm plays an important direction to accelerate the training process. However, recent advances on sample selection either mostly rely on an oracle model to offline select a high-quality coreset, which is limited in the cold-start scenarios, or focus on online selection based on real-time model predictions, which has not sufficiently or efficiently considered the noisy correspondence. To address this dilemma, we propose a novel Differential-Informed Sample Selection (DISSect) method, which accurately and efficiently discriminates the noisy correspondence for training acceleration. Specifically, we rethink the impact of noisy correspondence on contrastive learning and propose that the differential between the predicted correlation of the current model and that of a historical model is more informative to characterize sample quality. Based on this, we construct a robust differential-based sample selection and analyze its theoretical insights. Extensive experiments on three benchmark datasets and various downstream tasks demonstrate the consistent superiority of DISSect over current state-of-the-art methods. Source code is available at: https://github.com/MediaBrain-SJTU/DISSect.
Active Sampling for Node Attribute Completion on Graphs
Jan 14, 2025
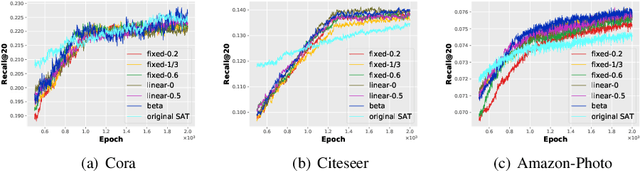


Node attribute, a type of crucial information for graph analysis, may be partially or completely missing for certain nodes in real world applications. Restoring the missing attributes is expected to benefit downstream graph learning. Few attempts have been made on node attribute completion, but a novel framework called Structure-attribute Transformer (SAT) was recently proposed by using a decoupled scheme to leverage structures and attributes. SAT ignores the differences in contributing to the learning schedule and finding a practical way to model the different importance of nodes with observed attributes is challenging. This paper proposes a novel AcTive Sampling algorithm (ATS) to restore missing node attributes. The representativeness and uncertainty of each node's information are first measured based on graph structure, representation similarity and learning bias. To select nodes as train samples in the next optimization step, a weighting scheme controlled by Beta distribution is then introduced to linearly combine the two properties. Extensive experiments on four public benchmark datasets and two downstream tasks have shown the superiority of ATS in node attribute completion.
Adaptify: A Refined Adaptation Scheme for Frame Classification in Atrophic Gastritis Videos
Aug 17, 2024Atrophic gastritis is a significant risk factor for developing gastric cancer. The incorporation of machine learning algorithms can efficiently elevate the possibility of accurately detecting atrophic gastritis. Nevertheless, when the trained model is applied in real-life circumstances, its output is often not consistently reliable. In this paper, we propose Adaptify, an adaptation scheme in which the model assimilates knowledge from its own classification decisions. Our proposed approach includes keeping the primary model constant, while simultaneously running and updating the auxiliary model. By integrating the knowledge gleaned by the auxiliary model into the primary model and merging their outputs, we have observed a notable improvement in output stability and consistency compared to relying solely on either the main model or the auxiliary model.
R2P: A Deep Learning Model from mmWave Radar to Point Cloud
Jul 21, 2022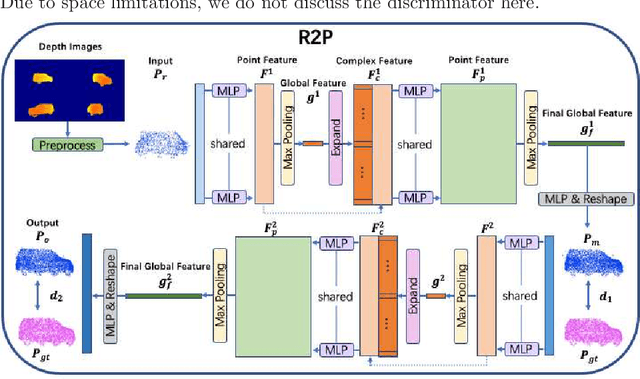
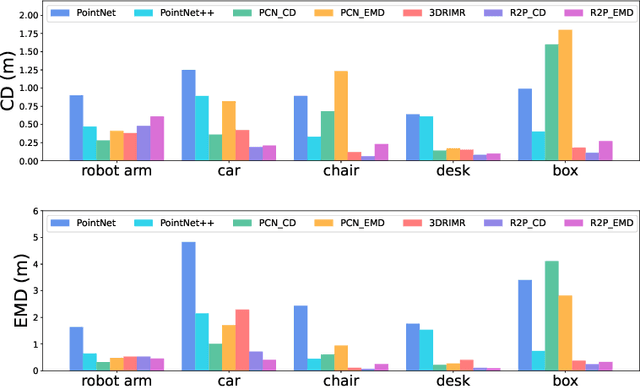

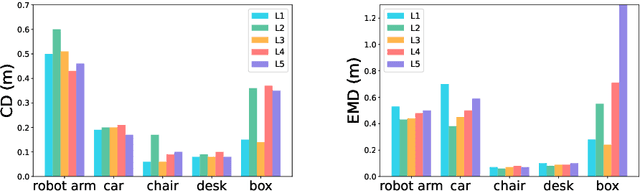
Recent research has shown the effectiveness of mmWave radar sensing for object detection in low visibility environments, which makes it an ideal technique in autonomous navigation systems. In this paper, we introduce Radar to Point Cloud (R2P), a deep learning model that generates smooth, dense, and highly accurate point cloud representation of a 3D object with fine geometry details, based on rough and sparse point clouds with incorrect points obtained from mmWave radar. These input point clouds are converted from the 2D depth images that are generated from raw mmWave radar sensor data, characterized by inconsistency, and orientation and shape errors. R2P utilizes an architecture of two sequential deep learning encoder-decoder blocks to extract the essential features of those radar-based input point clouds of an object when observed from multiple viewpoints, and to ensure the internal consistency of a generated output point cloud and its accurate and detailed shape reconstruction of the original object. We implement R2P to replace Stage 2 of our recently proposed 3DRIMR (3D Reconstruction and Imaging via mmWave Radar) system. Our experiments demonstrate the significant performance improvement of R2P over the popular existing methods such as PointNet, PCN, and the original 3DRIMR design.
Dual-CLVSA: a Novel Deep Learning Approach to Predict Financial Markets with Sentiment Measurements
Jan 27, 2022



It is a challenging task to predict financial markets. The complexity of this task is mainly due to the interaction between financial markets and market participants, who are not able to keep rational all the time, and often affected by emotions such as fear and ecstasy. Based on the state-of-the-art approach particularly for financial market predictions, a hybrid convolutional LSTM Based variational sequence-to-sequence model with attention (CLVSA), we propose a novel deep learning approach, named dual-CLVSA, to predict financial market movement with both trading data and the corresponding social sentiment measurements, each through a separate sequence-to-sequence channel. We evaluate the performance of our approach with backtesting on historical trading data of SPDR SP 500 Trust ETF over eight years. The experiment results show that dual-CLVSA can effectively fuse the two types of data, and verify that sentiment measurements are not only informative for financial market predictions, but they also contain extra profitable features to boost the performance of our predicting system.
A Knowledge-Based Decision Support System for In Vitro Fertilization Treatment
Jan 27, 2022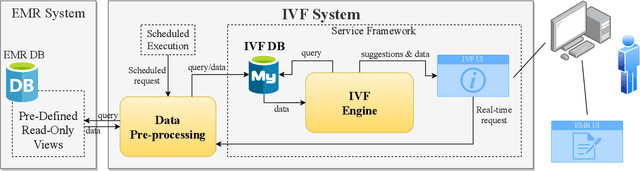
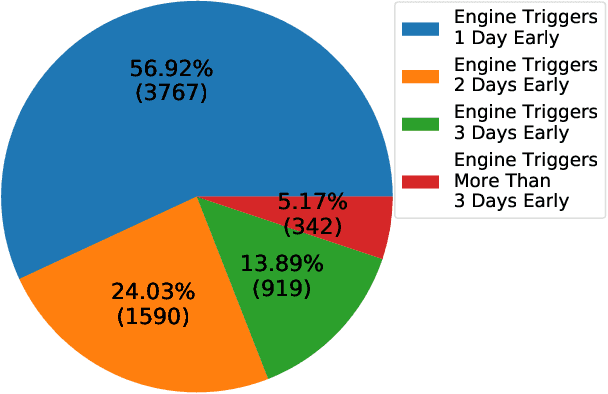
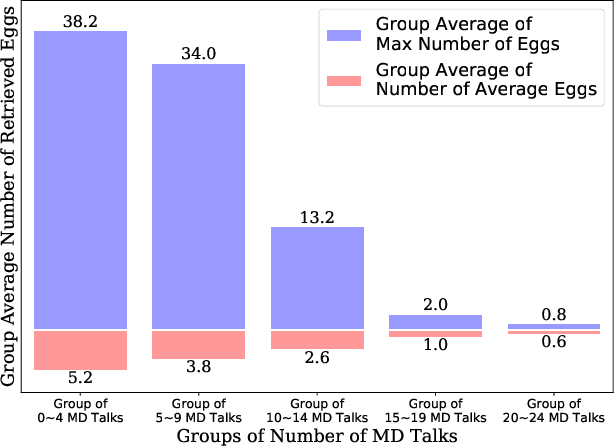
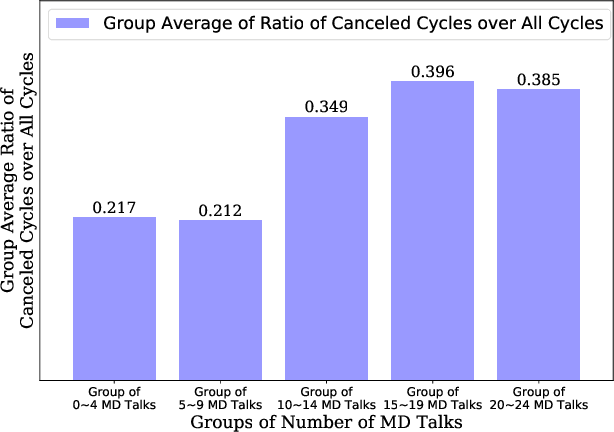
In Vitro Fertilization (IVF) is the most widely used Assisted Reproductive Technology (ART). IVF usually involves controlled ovarian stimulation, oocyte retrieval, fertilization in the laboratory with subsequent embryo transfer. The first two steps correspond with follicular phase of females and ovulation in their menstrual cycle. Therefore, we refer to it as the treatment cycle in our paper. The treatment cycle is crucial because the stimulation medications in IVF treatment are applied directly on patients. In order to optimize the stimulation effects and lower the side effects of the stimulation medications, prompt treatment adjustments are in need. In addition, the quality and quantity of the retrieved oocytes have a significant effect on the outcome of the following procedures. To improve the IVF success rate, we propose a knowledge-based decision support system that can provide medical advice on the treatment protocol and medication adjustment for each patient visit during IVF treatment cycle. Our system is efficient in data processing and light-weighted which can be easily embedded into electronic medical record systems. Moreover, an oocyte retrieval oriented evaluation demonstrates that our system performs well in terms of accuracy of advice for the protocols and medications.
DeepPoint: A Deep Learning Model for 3D Reconstruction in Point Clouds via mmWave Radar
Sep 19, 2021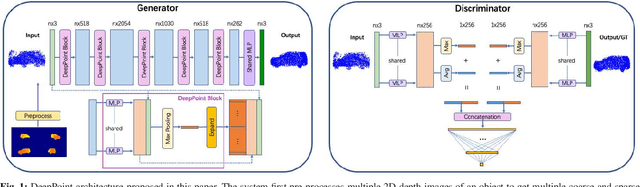
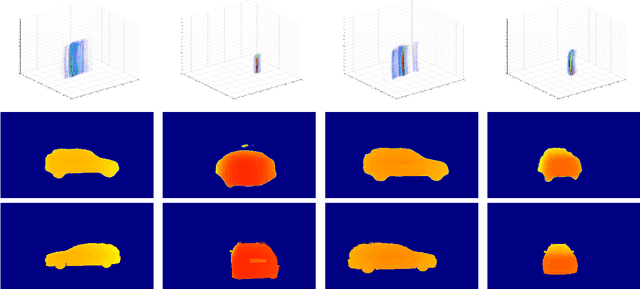

Recent research has shown that mmWave radar sensing is effective for object detection in low visibility environments, which makes it an ideal technique in autonomous navigation systems such as autonomous vehicles. However, due to the characteristics of radar signals such as sparsity, low resolution, specularity, and high noise, it is still quite challenging to reconstruct 3D object shapes via mmWave radar sensing. Built on our recent proposed 3DRIMR (3D Reconstruction and Imaging via mmWave Radar), we introduce in this paper DeepPoint, a deep learning model that generates 3D objects in point cloud format that significantly outperforms the original 3DRIMR design. The model adopts a conditional Generative Adversarial Network (GAN) based deep neural network architecture. It takes as input the 2D depth images of an object generated by 3DRIMR's Stage 1, and outputs smooth and dense 3D point clouds of the object. The model consists of a novel generator network that utilizes a sequence of DeepPoint blocks or layers to extract essential features of the union of multiple rough and sparse input point clouds of an object when observed from various viewpoints, given that those input point clouds may contain many incorrect points due to the imperfect generation process of 3DRIMR's Stage 1. The design of DeepPoint adopts a deep structure to capture the global features of input point clouds, and it relies on an optimally chosen number of DeepPoint blocks and skip connections to achieve performance improvement over the original 3DRIMR design. Our experiments have demonstrated that this model significantly outperforms the original 3DRIMR and other standard techniques in reconstructing 3D objects.
CLVSA: A Convolutional LSTM Based Variational Sequence-to-Sequence Model with Attention for Predicting Trends of Financial Markets
Apr 08, 2021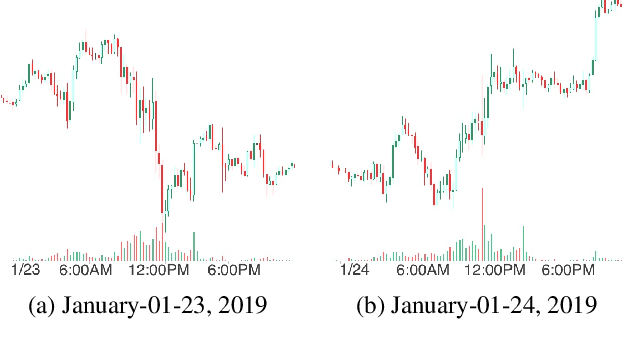

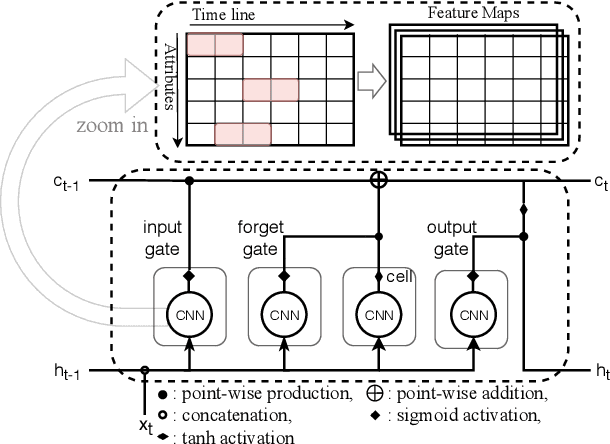
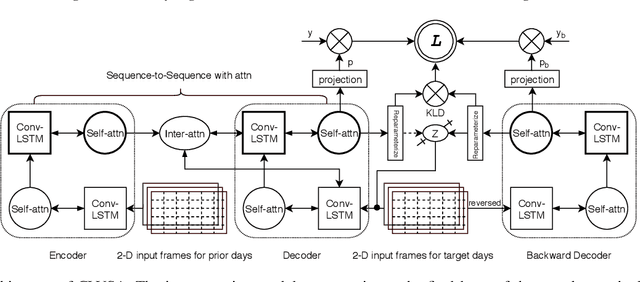
Financial markets are a complex dynamical system. The complexity comes from the interaction between a market and its participants, in other words, the integrated outcome of activities of the entire participants determines the markets trend, while the markets trend affects activities of participants. These interwoven interactions make financial markets keep evolving. Inspired by stochastic recurrent models that successfully capture variability observed in natural sequential data such as speech and video, we propose CLVSA, a hybrid model that consists of stochastic recurrent networks, the sequence-to-sequence architecture, the self- and inter-attention mechanism, and convolutional LSTM units to capture variationally underlying features in raw financial trading data. Our model outperforms basic models, such as convolutional neural network, vanilla LSTM network, and sequence-to-sequence model with attention, based on backtesting results of six futures from January 2010 to December 2017. Our experimental results show that, by introducing an approximate posterior, CLVSA takes advantage of an extra regularizer based on the Kullback-Leibler divergence to prevent itself from overfitting traps.
Financial Markets Prediction with Deep Learning
Apr 05, 2021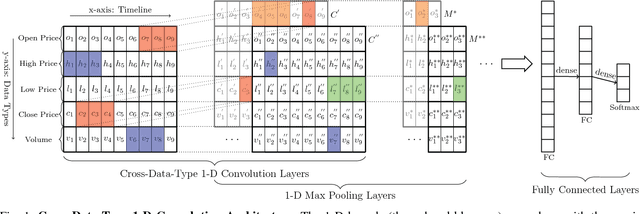
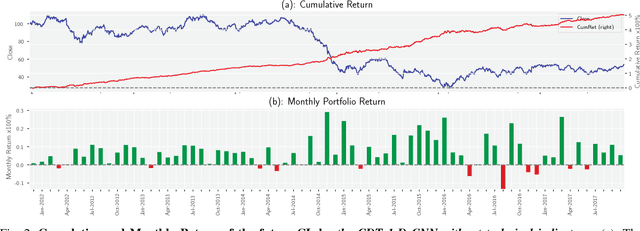
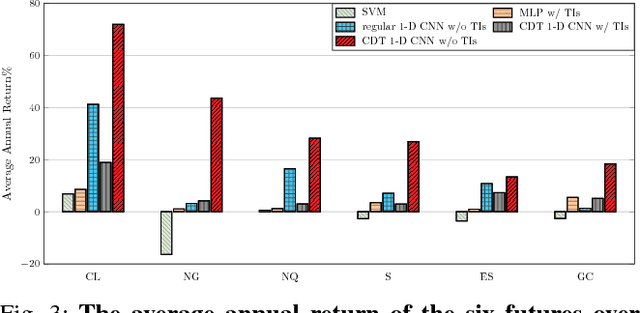
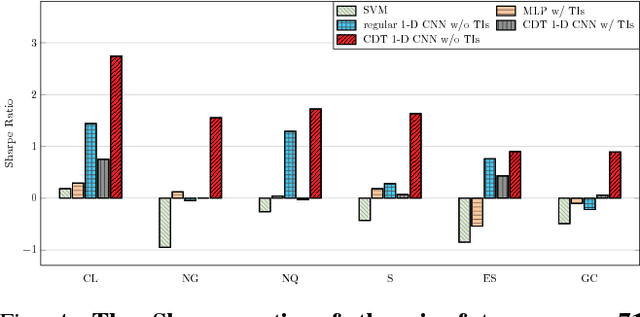
Financial markets are difficult to predict due to its complex systems dynamics. Although there have been some recent studies that use machine learning techniques for financial markets prediction, they do not offer satisfactory performance on financial returns. We propose a novel one-dimensional convolutional neural networks (CNN) model to predict financial market movement. The customized one-dimensional convolutional layers scan financial trading data through time, while different types of data, such as prices and volume, share parameters (kernels) with each other. Our model automatically extracts features instead of using traditional technical indicators and thus can avoid biases caused by selection of technical indicators and pre-defined coefficients in technical indicators. We evaluate the performance of our prediction model with strictly backtesting on historical trading data of six futures from January 2010 to October 2017. The experiment results show that our CNN model can effectively extract more generalized and informative features than traditional technical indicators, and achieves more robust and profitable financial performance than previous machine learning approaches.
Colorectal Polyp Detection in Real-world Scenario: Design and Experiment Study
Jan 11, 2021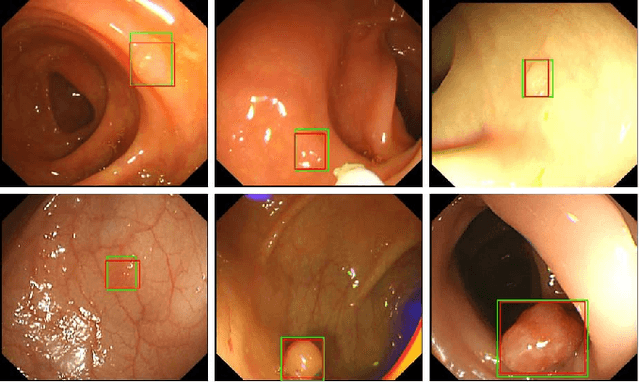
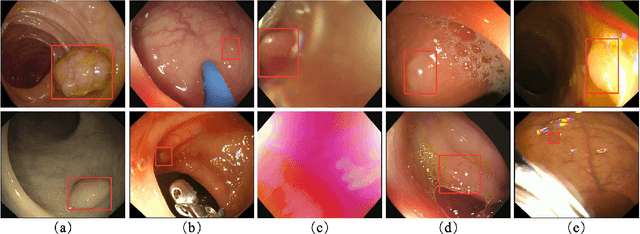


Colorectal polyps are abnormal tissues growing on the intima of the colon or rectum with a high risk of developing into colorectal cancer, the third leading cause of cancer death worldwide. Early detection and removal of colon polyps via colonoscopy have proved to be an effective approach to prevent colorectal cancer. Recently, various CNN-based computer-aided systems have been developed to help physicians detect polyps. However, these systems do not perform well in real-world colonoscopy operations due to the significant difference between images in a real colonoscopy and those in the public datasets. Unlike the well-chosen clear images with obvious polyps in the public datasets, images from a colonoscopy are often blurry and contain various artifacts such as fluid, debris, bubbles, reflection, specularity, contrast, saturation, and medical instruments, with a wide variety of polyps of different sizes, shapes, and textures. All these factors pose a significant challenge to effective polyp detection in a colonoscopy. To this end, we collect a private dataset that contains 7,313 images from 224 complete colonoscopy procedures. This dataset represents realistic operation scenarios and thus can be used to better train the models and evaluate a system's performance in practice. We propose an integrated system architecture to address the unique challenges for polyp detection. Extensive experiments results show that our system can effectively detect polyps in a colonoscopy with excellent performance in real time.