 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Body-Aware 3D Shape Generative Models
Dec 16, 2021

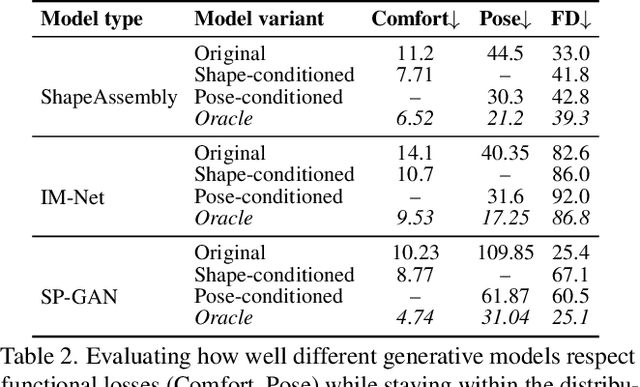
The shape of many objects in the built environment is dictated by their relationships to the human body: how will a person interact with this object? Existing data-driven generative models of 3D shapes produce plausible objects but do not reason about the relationship of those objects to the human body. In this paper, we learn body-aware generative models of 3D shapes. Specifically, we train generative models of chairs, an ubiquitous shape category, which can be conditioned on a given body shape or sitting pose. The body-shape-conditioned models produce chairs which will be comfortable for a person with the given body shape; the pose-conditioned models produce chairs which accommodate the given sitting pose. To train these models, we define a "sitting pose matching" metric and a novel "sitting comfort" metric. Calculating these metrics requires an expensive optimization to sit the body into the chair, which is too slow to be used as a loss function for training a generative model. Thus, we train neural networks to efficiently approximate these metrics. We use our approach to train three body-aware generative shape models: a structured part-based generator, a point cloud generator, and an implicit surface generator. In all cases, our approach produces models which adapt their output chair shapes to input human body specifications.
Retinopathy of Prematurity Stage Diagnosis Using Object Segmentation and Convolutional Neural Networks
Apr 03, 2020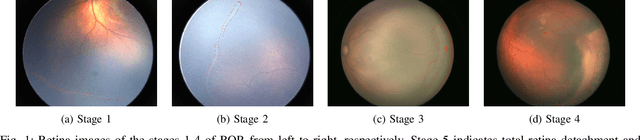
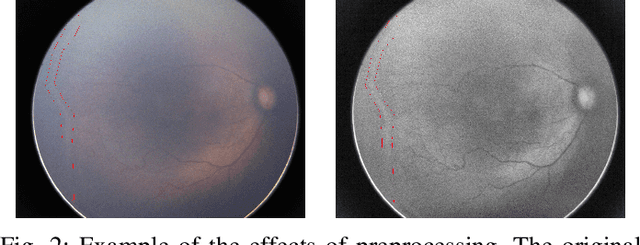
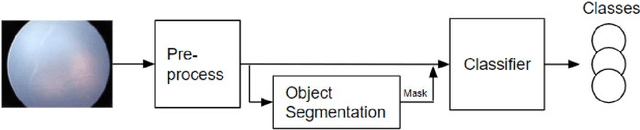
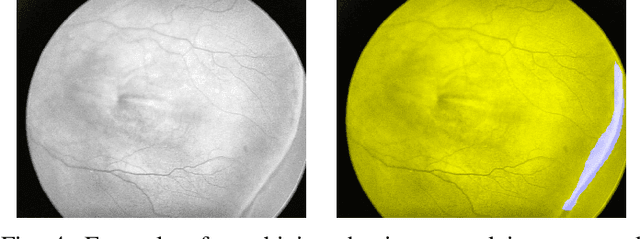
Retinopathy of Prematurity (ROP) is an eye disorder primarily affecting premature infants with lower weights. It causes proliferation of vessels in the retina and could result in vision loss and, eventually, retinal detachment, leading to blindness. While human experts can easily identify severe stages of ROP, the diagnosis of earlier stages, which are the most relevant to determining treatment choice, are much more affected by variability in subjective interpretations of human experts. In recent years, there has been a significant effort to automate the diagnosis using deep learning. This paper builds upon the success of previous models and develops a novel architecture, which combines object segmentation and convolutional neural networks (CNN) to construct an effective classifier of ROP stages 1-3 based on neonatal retinal images. Motivated by the fact that the formation and shape of a demarcation line in the retina is the distinguishing feature between earlier ROP stages, our proposed system first trains an object segmentation model to identify the demarcation line at a pixel level and adds the resulting mask as an additional "color" channel in the original image. Then, the system trains a CNN classifier based on the processed images to leverage information from both the original image and the mask, which helps direct the model's attention to the demarcation line. In a number of careful experiments comparing its performance to previous object segmentation systems and CNN-only systems trained on our dataset, our novel architecture significantly outperforms previous systems in accuracy, demonstrating the effectiveness of our proposed pipeline.