 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoirai: Towards Optimal Placement for Distributed Inference on Heterogeneous Devices
Dec 26, 2023



The escalating size of Deep Neural Networks (DNNs) has spurred a growing research interest in hosting and serving DNN models across multiple devices. A number of studies have been reported to partition a DNN model across devices, providing device placement solutions. The methods appeared in the literature, however, either suffer from poor placement performance due to the exponential search space or miss an optimal placement as a consequence of the reduced search space with limited heuristics. Moreover, these methods have ignored the runtime inter-operator optimization of a computation graph when coarsening the graph, which degrades the end-to-end inference performance. This paper presents Moirai that better exploits runtime inter-operator fusion in a model to render a coarsened computation graph, reducing the search space while maintaining the inter-operator optimization provided by inference backends. Moirai also generalizes the device placement algorithm from multiple perspectives by considering inference constraints and device heterogeneity.Extensive experimental evaluation with 11 large DNNs demonstrates that Moirai outperforms the state-of-the-art counterparts, i.e., Placeto, m-SCT, and GETF, up to 4.28$\times$ in reduction of the end-to-end inference latency. Moirai code is anonymously released at \url{https://github.com/moirai-placement/moirai}.
Dual-CLVSA: a Novel Deep Learning Approach to Predict Financial Markets with Sentiment Measurements
Jan 27, 2022



It is a challenging task to predict financial markets. The complexity of this task is mainly due to the interaction between financial markets and market participants, who are not able to keep rational all the time, and often affected by emotions such as fear and ecstasy. Based on the state-of-the-art approach particularly for financial market predictions, a hybrid convolutional LSTM Based variational sequence-to-sequence model with attention (CLVSA), we propose a novel deep learning approach, named dual-CLVSA, to predict financial market movement with both trading data and the corresponding social sentiment measurements, each through a separate sequence-to-sequence channel. We evaluate the performance of our approach with backtesting on historical trading data of SPDR SP 500 Trust ETF over eight years. The experiment results show that dual-CLVSA can effectively fuse the two types of data, and verify that sentiment measurements are not only informative for financial market predictions, but they also contain extra profitable features to boost the performance of our predicting system.
CLVSA: A Convolutional LSTM Based Variational Sequence-to-Sequence Model with Attention for Predicting Trends of Financial Markets
Apr 08, 2021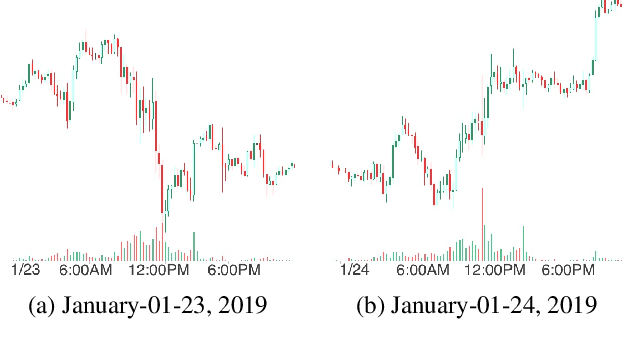

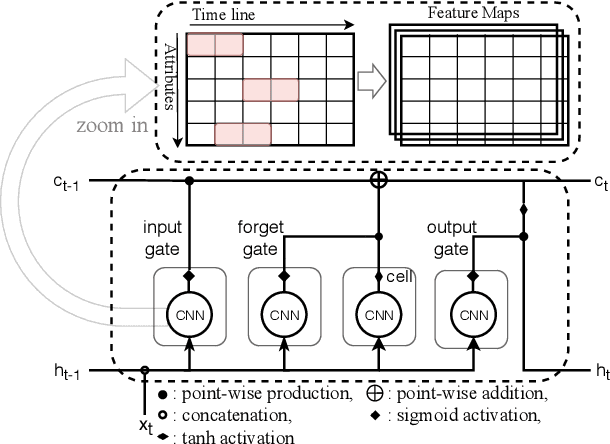
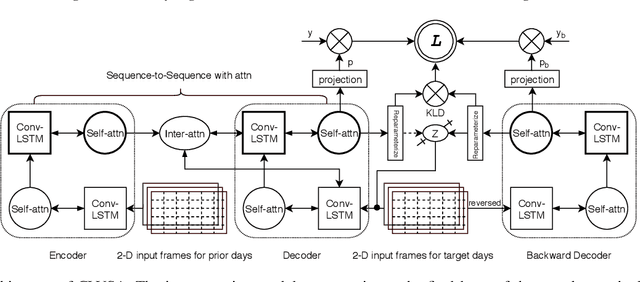
Financial markets are a complex dynamical system. The complexity comes from the interaction between a market and its participants, in other words, the integrated outcome of activities of the entire participants determines the markets trend, while the markets trend affects activities of participants. These interwoven interactions make financial markets keep evolving. Inspired by stochastic recurrent models that successfully capture variability observed in natural sequential data such as speech and video, we propose CLVSA, a hybrid model that consists of stochastic recurrent networks, the sequence-to-sequence architecture, the self- and inter-attention mechanism, and convolutional LSTM units to capture variationally underlying features in raw financial trading data. Our model outperforms basic models, such as convolutional neural network, vanilla LSTM network, and sequence-to-sequence model with attention, based on backtesting results of six futures from January 2010 to December 2017. Our experimental results show that, by introducing an approximate posterior, CLVSA takes advantage of an extra regularizer based on the Kullback-Leibler divergence to prevent itself from overfitting traps.
MixSearch: Searching for Domain Generalized Medical Image Segmentation Architectures
Feb 26, 2021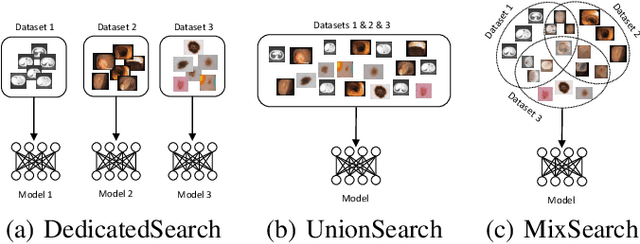
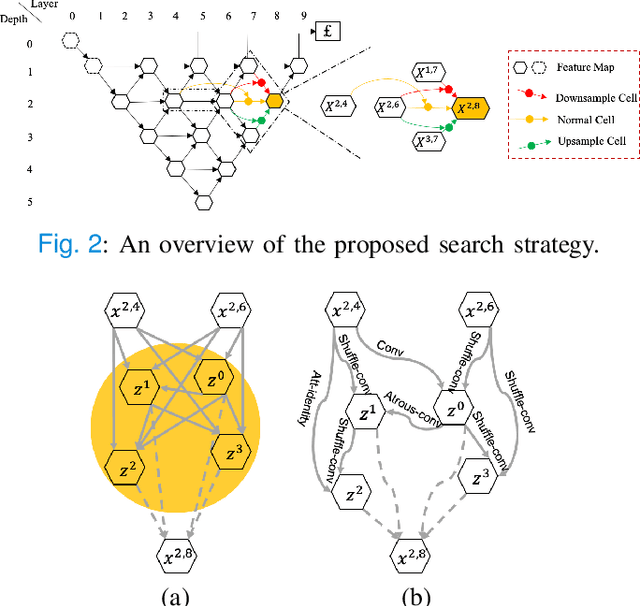
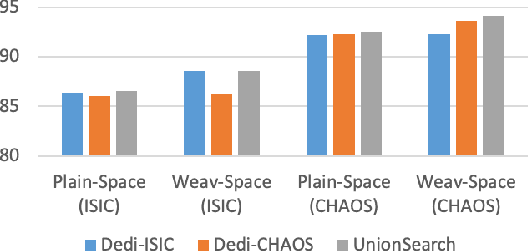
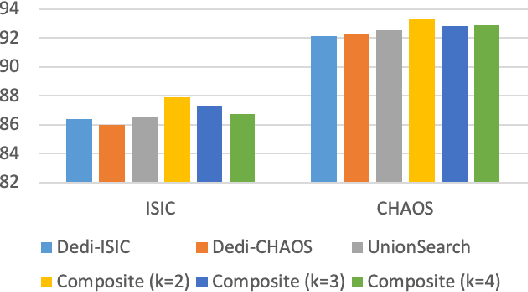
Considering the scarcity of medical data, most datasets in medical image analysis are an order of magnitude smaller than those of natural images. However, most Network Architecture Search (NAS) approaches in medical images focused on specific datasets and did not take into account the generalization ability of the learned architectures on unseen datasets as well as different domains. In this paper, we address this point by proposing to search for generalizable U-shape architectures on a composited dataset that mixes medical images from multiple segmentation tasks and domains creatively, which is named MixSearch. Specifically, we propose a novel approach to mix multiple small-scale datasets from multiple domains and segmentation tasks to produce a large-scale dataset. Then, a novel weaved encoder-decoder structure is designed to search for a generalized segmentation network in both cell-level and network-level. The network produced by the proposed MixSearch framework achieves state-of-the-art results compared with advanced encoder-decoder networks across various datasets.