 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAir-to-Ground Cooperative OAM Communications
Jul 31, 2024For users in hotspot region, orbital angular momentum (OAM) can realize multifold increase of spectrum efficiency (SE), and the flying base station (FBS) can rapidly support the real-time communication demand. However, the hollow divergence and alignment requirement impose crucial challenges for users to achieve air-to-ground OAM communications, where there exists the line-of-sight path. Therefore, we propose the air-to-ground cooperative OAM communication (ACOC) scheme, which can realize OAM communications for users with size-limited devices. The waist radius is adjusted to guarantee the maximum intensity at the cooperative users (CUs). We derive the closed-form expression of the optimal FBS position, which satisfies the antenna alignment for two cooperative user groups (CUGs). Furthermore, the selection constraint is given to choose two CUGs composed of four CUs. Simulation results are provided to validate the optimal FBS position and the SE superiority of the proposed ACOC scheme.
Precoding Based Downlink OAM-MIMO Communications with Rate Splitting
Jul 31, 2024



Orbital angular momentum (OAM) and rate splitting (RS) are the potential key techniques for the future wireless communications. As a new orthogonal resource, OAM can achieve the multifold increase of spectrum efficiency to relieve the scarcity of the spectrum resource, but how to enhance the privacy performance imposes crucial challenge for OAM communications. RS technique divides the information into private and common parts, which can guarantee the privacies for all users. In this paper, we integrate the RS technique into downlink OAM-MIMO communications, and study the precoding optimization to maximize the sum capacity. First, the concentric uniform circular arrays (UCAs) are utilized to construct the downlink transmission framework of OAM-MIMO communications with RS. Particularly, users in the same user pair utilize RS technique to obtain the information and different user pairs use different OAM modes. Then, we derive the OAM-MIMO channel model, and formulate the sum capacity maximization problem. Finally, based on the fractional programming, the optimal precoding matrix is obtained to maximize the sum capacity by using quadratic transformation. Extensive simulation results show that by using the proposed precoding optimization algorithm, OAM-MIMO communications with RS can achieve higher sum capacity than the traditional communication schemes.
Do As I Do: Pose Guided Human Motion Copy
Jun 24, 2024



Human motion copy is an intriguing yet challenging task in artificial intelligence and computer vision, which strives to generate a fake video of a target person performing the motion of a source person. The problem is inherently challenging due to the subtle human-body texture details to be generated and the temporal consistency to be considered. Existing approaches typically adopt a conventional GAN with an L1 or L2 loss to produce the target fake video, which intrinsically necessitates a large number of training samples that are challenging to acquire. Meanwhile, current methods still have difficulties in attaining realistic image details and temporal consistency, which unfortunately can be easily perceived by human observers. Motivated by this, we try to tackle the issues from three aspects: (1) We constrain pose-to-appearance generation with a perceptual loss and a theoretically motivated Gromov-Wasserstein loss to bridge the gap between pose and appearance. (2) We present an episodic memory module in the pose-to-appearance generation to propel continuous learning that helps the model learn from its past poor generations. We also utilize geometrical cues of the face to optimize facial details and refine each key body part with a dedicated local GAN. (3) We advocate generating the foreground in a sequence-to-sequence manner rather than a single-frame manner, explicitly enforcing temporal inconsistency. Empirical results on five datasets, iPER, ComplexMotion, SoloDance, Fish, and Mouse datasets, demonstrate that our method is capable of generating realistic target videos while precisely copying motion from a source video. Our method significantly outperforms state-of-the-art approaches and gains 7.2% and 12.4% improvements in PSNR and FID respectively.
Multi-Objective Trajectory Planning with Dual-Encoder
Mar 26, 2024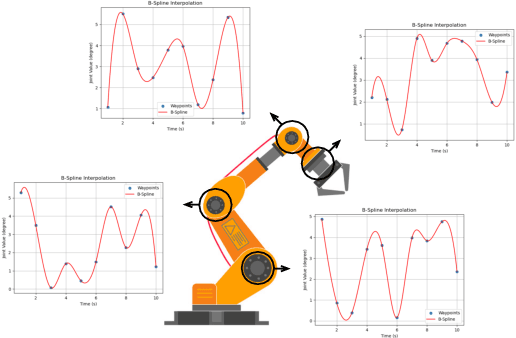



Time-jerk optimal trajectory planning is crucial in advancing robotic arms' performance in dynamic tasks. Traditional methods rely on solving complex nonlinear programming problems, bringing significant delays in generating optimized trajectories. In this paper, we propose a two-stage approach to accelerate time-jerk optimal trajectory planning. Firstly, we introduce a dual-encoder based transformer model to establish a good preliminary trajectory. This trajectory is subsequently refined through sequential quadratic programming to improve its optimality and robustness. Our approach outperforms the state-of-the-art by up to 79.72\% in reducing trajectory planning time. Compared with existing methods, our method shrinks the optimality gap with the objective function value decreasing by up to 29.9\%.
Moirai: Towards Optimal Placement for Distributed Inference on Heterogeneous Devices
Dec 26, 2023



The escalating size of Deep Neural Networks (DNNs) has spurred a growing research interest in hosting and serving DNN models across multiple devices. A number of studies have been reported to partition a DNN model across devices, providing device placement solutions. The methods appeared in the literature, however, either suffer from poor placement performance due to the exponential search space or miss an optimal placement as a consequence of the reduced search space with limited heuristics. Moreover, these methods have ignored the runtime inter-operator optimization of a computation graph when coarsening the graph, which degrades the end-to-end inference performance. This paper presents Moirai that better exploits runtime inter-operator fusion in a model to render a coarsened computation graph, reducing the search space while maintaining the inter-operator optimization provided by inference backends. Moirai also generalizes the device placement algorithm from multiple perspectives by considering inference constraints and device heterogeneity.Extensive experimental evaluation with 11 large DNNs demonstrates that Moirai outperforms the state-of-the-art counterparts, i.e., Placeto, m-SCT, and GETF, up to 4.28$\times$ in reduction of the end-to-end inference latency. Moirai code is anonymously released at \url{https://github.com/moirai-placement/moirai}.
Semantics-Driven Cloud-Edge Collaborative Inference
Sep 27, 2023
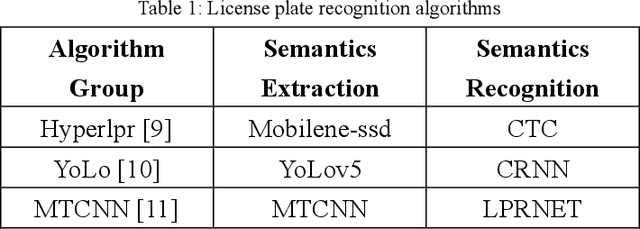
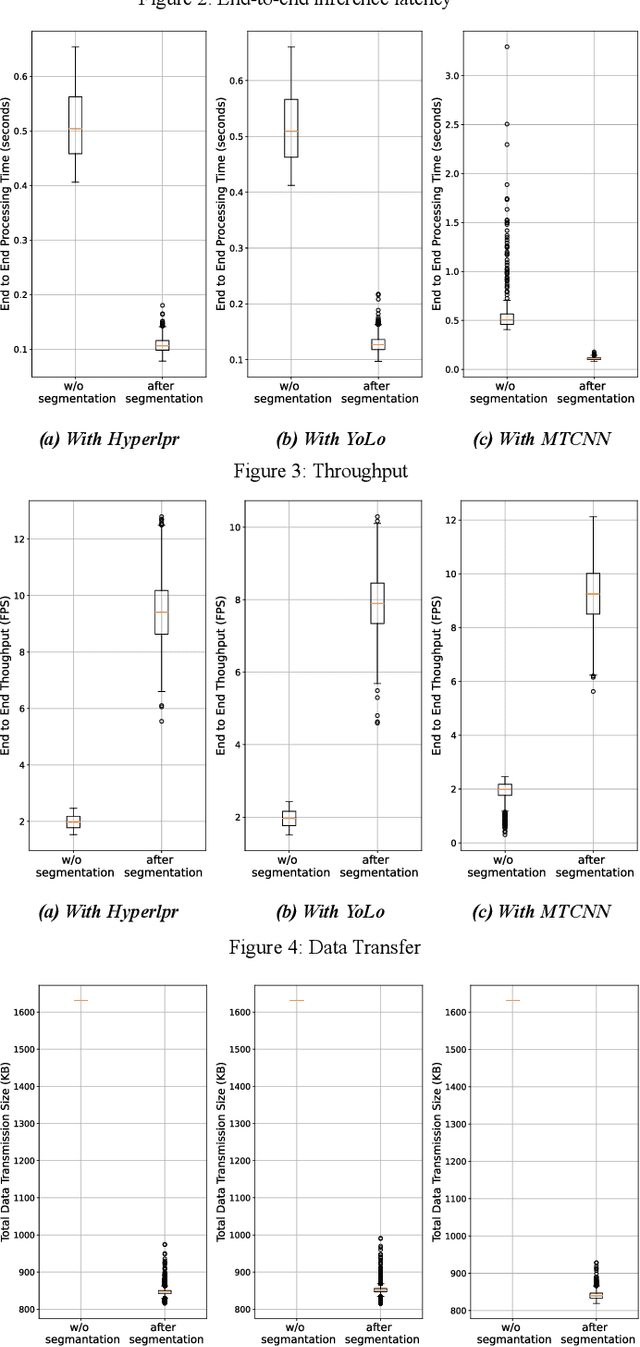
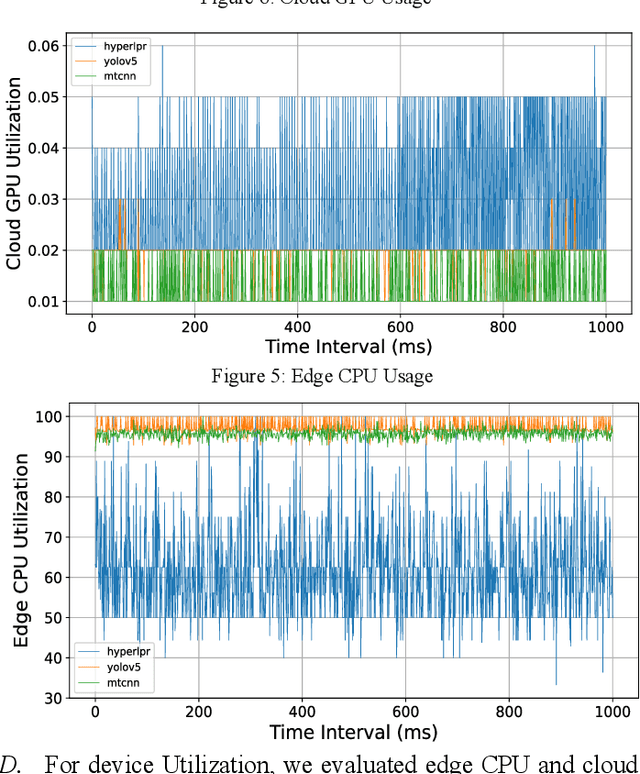
With the proliferation of video data in smart city applications like intelligent transportation, efficient video analytics has become crucial but also challenging. This paper proposes a semantics-driven cloud-edge collaborative approach for accelerating video inference, using license plate recognition as a case study. The method separates semantics extraction and recognition, allowing edge servers to only extract visual semantics (license plate patches) from video frames and offload computation-intensive recognition to the cloud or neighboring edges based on load. This segmented processing coupled with a load-aware work distribution strategy aims to reduce end-to-end latency and improve throughput. Experiments demonstrate significant improvements in end-to-end inference speed (up to 5x faster), throughput (up to 9 FPS), and reduced traffic volumes (50% less) compared to cloud-only or edge-only processing, validating the efficiency of the proposed approach. The cloud-edge collaborative framework with semantics-driven work partitioning provides a promising solution for scaling video analytics in smart cities.
Action Recognition with Multi-stream Motion Modeling and Mutual Information Maximization
Jun 13, 2023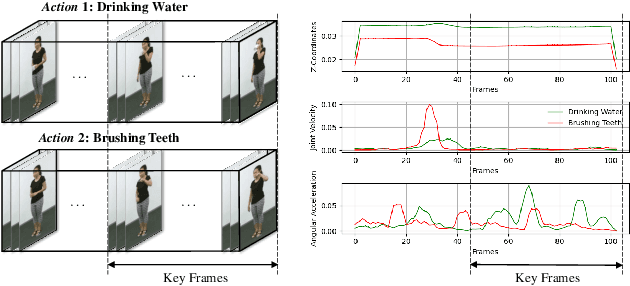
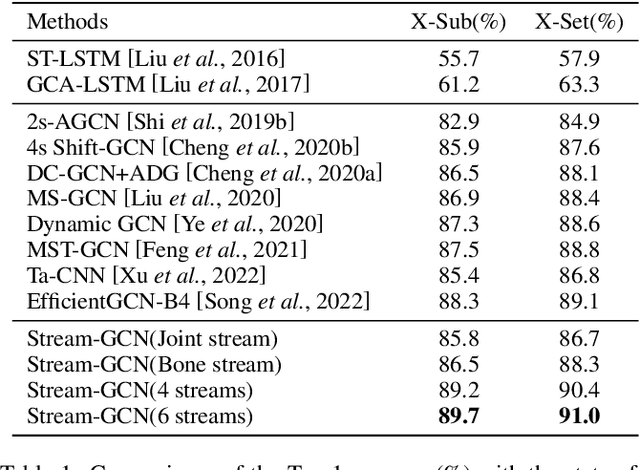
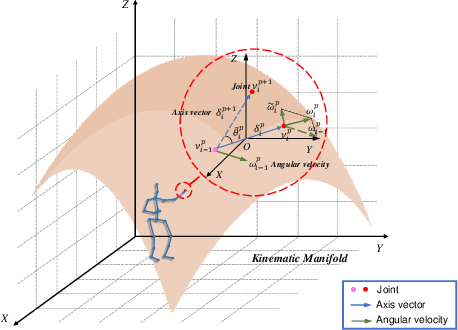
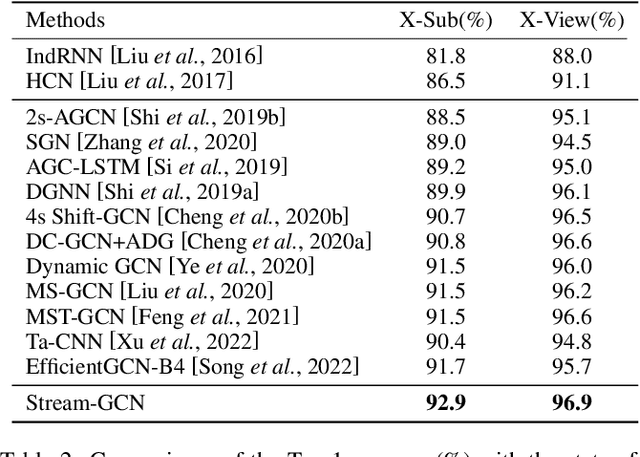
Action recognition has long been a fundamental and intriguing problem in artificial intelligence. The task is challenging due to the high dimensionality nature of an action, as well as the subtle motion details to be considered. Current state-of-the-art approaches typically learn from articulated motion sequences in the straightforward 3D Euclidean space. However, the vanilla Euclidean space is not efficient for modeling important motion characteristics such as the joint-wise angular acceleration, which reveals the driving force behind the motion. Moreover, current methods typically attend to each channel equally and lack theoretical constrains on extracting task-relevant features from the input. In this paper, we seek to tackle these challenges from three aspects: (1) We propose to incorporate an acceleration representation, explicitly modeling the higher-order variations in motion. (2) We introduce a novel Stream-GCN network equipped with multi-stream components and channel attention, where different representations (i.e., streams) supplement each other towards a more precise action recognition while attention capitalizes on those important channels. (3) We explore feature-level supervision for maximizing the extraction of task-relevant information and formulate this into a mutual information loss. Empirically, our approach sets the new state-of-the-art performance on three benchmark datasets, NTU RGB+D, NTU RGB+D 120, and NW-UCLA. Our code is anonymously released at https://github.com/ActionR-Group/Stream-GCN, hoping to inspire the community.
Dynamic DNN Decomposition for Lossless Synergistic Inference
Jan 15, 2021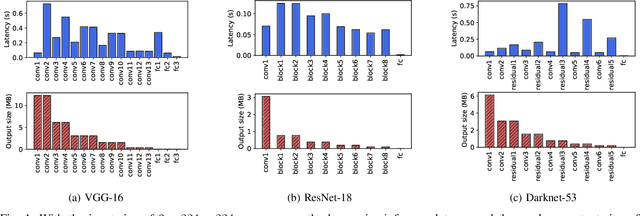


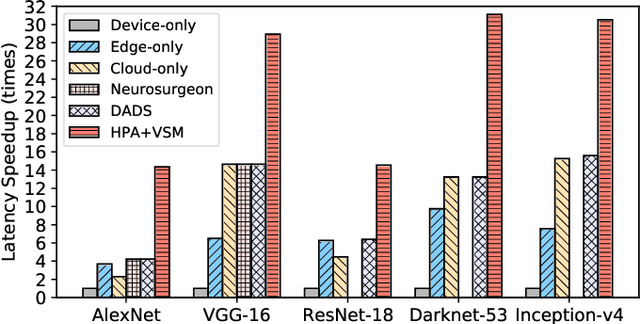
Deep neural networks (DNNs) sustain high performance in today's data processing applications. DNN inference is resource-intensive thus is difficult to fit into a mobile device. An alternative is to offload the DNN inference to a cloud server. However, such an approach requires heavy raw data transmission between the mobile device and the cloud server, which is not suitable for mission-critical and privacy-sensitive applications such as autopilot. To solve this problem, recent advances unleash DNN services using the edge computing paradigm. The existing approaches split a DNN into two parts and deploy the two partitions to computation nodes at two edge computing tiers. Nonetheless, these methods overlook collaborative device-edge-cloud computation resources. Besides, previous algorithms demand the whole DNN re-partitioning to adapt to computation resource changes and network dynamics. Moreover, for resource-demanding convolutional layers, prior works do not give a parallel processing strategy without loss of accuracy at the edge side. To tackle these issues, we propose D3, a dynamic DNN decomposition system for synergistic inference without precision loss. The proposed system introduces a heuristic algorithm named horizontal partition algorithm to split a DNN into three parts. The algorithm can partially adjust the partitions at run time according to processing time and network conditions. At the edge side, a vertical separation module separates feature maps into tiles that can be independently run on different edge nodes in parallel. Extensive quantitative evaluation of five popular DNNs illustrates that D3 outperforms the state-of-the-art counterparts up to 3.4 times in end-to-end DNN inference time and reduces backbone network communication overhead up to 3.68 times.