 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSR:Achieving 1 Bit Key-Value Cache via Sparse Representation
Dec 16, 2024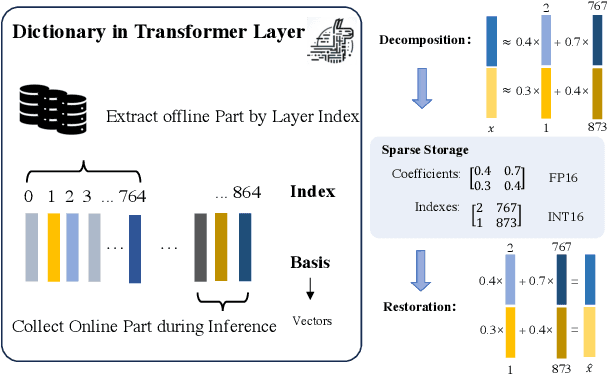

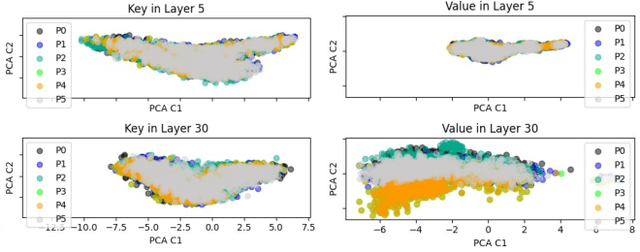
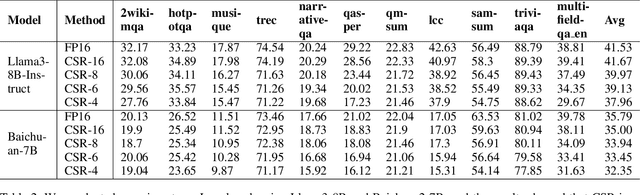
The emergence of long-context text applications utilizing large language models (LLMs) has presented significant scalability challenges, particularly in memory footprint. The linear growth of the Key-Value (KV) cache responsible for storing attention keys and values to minimize redundant computations can lead to substantial increases in memory consumption, potentially causing models to fail to serve with limited memory resources. To address this issue, we propose a novel approach called Cache Sparse Representation (CSR), which converts the KV cache by transforming the dense Key-Value cache tensor into sparse indexes and weights, offering a more memory-efficient representation during LLM inference. Furthermore, we introduce NeuralDict, a novel neural network-based method for automatically generating the dictionary used in our sparse representation. Our extensive experiments demonstrate that CSR achieves performance comparable to state-of-the-art KV cache quantization algorithms while maintaining robust functionality in memory-constrained environments.
GreenFlow: A Computation Allocation Framework for Building Environmentally Sound Recommendation System
Dec 15, 2023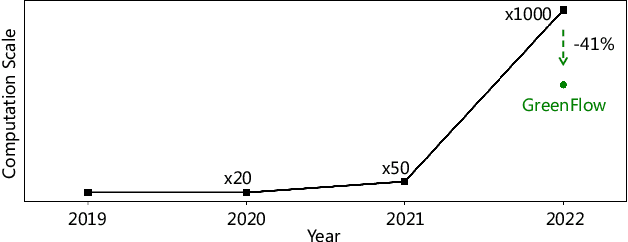
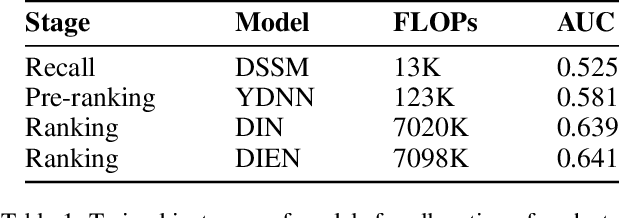
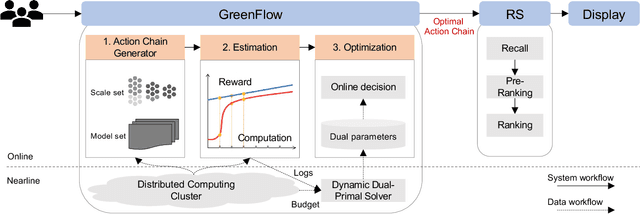
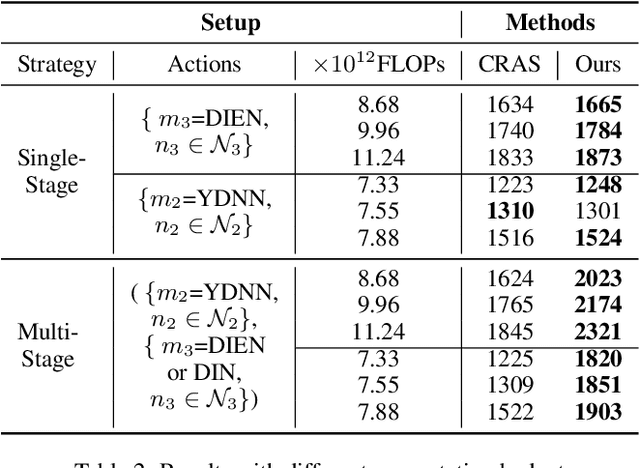
Given the enormous number of users and items, industrial cascade recommendation systems (RS) are continuously expanded in size and complexity to deliver relevant items, such as news, services, and commodities, to the appropriate users. In a real-world scenario with hundreds of thousands requests per second, significant computation is required to infer personalized results for each request, resulting in a massive energy consumption and carbon emission that raises concern. This paper proposes GreenFlow, a practical computation allocation framework for RS, that considers both accuracy and carbon emission during inference. For each stage (e.g., recall, pre-ranking, ranking, etc.) of a cascade RS, when a user triggers a request, we define two actions that determine the computation: (1) the trained instances of models with different computational complexity; and (2) the number of items to be inferred in the stage. We refer to the combinations of actions in all stages as action chains. A reward score is estimated for each action chain, followed by dynamic primal-dual optimization considering both the reward and computation budget. Extensive experiments verify the effectiveness of the framework, reducing computation consumption by 41% in an industrial mobile application while maintaining commercial revenue. Moreover, the proposed framework saves approximately 5000kWh of electricity and reduces 3 tons of carbon emissions per day.
Fast Chain-of-Thought: A Glance of Future from Parallel Decoding Leads to Answers Faster
Nov 14, 2023



In this work, we propose FastCoT, a model-agnostic framework based on parallel decoding without any further training of an auxiliary model or modification to the LLM itself. FastCoT uses a size-varying context window whose size changes with position to conduct parallel decoding and auto-regressive decoding simultaneously, thus fully utilizing GPU computation resources. In FastCoT, the parallel decoding part provides the LLM with a quick glance of the future composed of approximate tokens, which could lead to faster answers compared to regular autoregressive decoding used by causal transformers. We also provide an implementation of parallel decoding within LLM, which supports KV-cache generation and batch processing. Through extensive experiments, we demonstrate that FastCoT saves inference time by nearly 20% with only a negligible performance drop compared to the regular approach. Additionally, we show that the context window size exhibits considerable robustness for different tasks.
On the Opportunities of Green Computing: A Survey
Nov 09, 2023



Artificial Intelligence (AI) has achieved significant advancements in technology and research with the development over several decades, and is widely used in many areas including computing vision, natural language processing, time-series analysis, speech synthesis, etc. During the age of deep learning, especially with the arise of Large Language Models, a large majority of researchers' attention is paid on pursuing new state-of-the-art (SOTA) results, resulting in ever increasing of model size and computational complexity. The needs for high computing power brings higher carbon emission and undermines research fairness by preventing small or medium-sized research institutions and companies with limited funding in participating in research. To tackle the challenges of computing resources and environmental impact of AI, Green Computing has become a hot research topic. In this survey, we give a systematic overview of the technologies used in Green Computing. We propose the framework of Green Computing and devide it into four key components: (1) Measures of Greenness, (2) Energy-Efficient AI, (3) Energy-Efficient Computing Systems and (4) AI Use Cases for Sustainability. For each components, we discuss the research progress made and the commonly used techniques to optimize the AI efficiency. We conclude that this new research direction has the potential to address the conflicts between resource constraints and AI development. We encourage more researchers to put attention on this direction and make AI more environmental friendly.
Dynamic DNN Decomposition for Lossless Synergistic Inference
Jan 15, 2021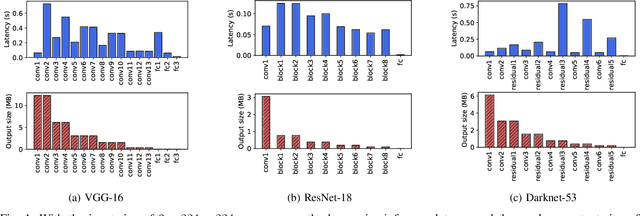


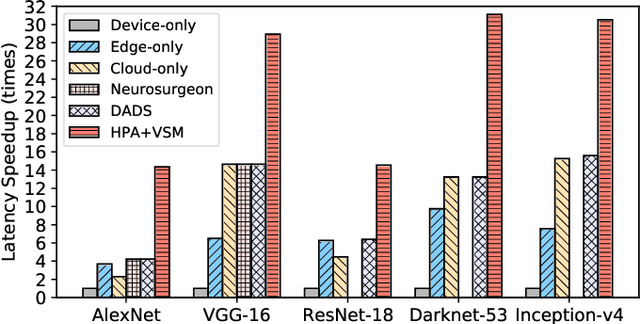
Deep neural networks (DNNs) sustain high performance in today's data processing applications. DNN inference is resource-intensive thus is difficult to fit into a mobile device. An alternative is to offload the DNN inference to a cloud server. However, such an approach requires heavy raw data transmission between the mobile device and the cloud server, which is not suitable for mission-critical and privacy-sensitive applications such as autopilot. To solve this problem, recent advances unleash DNN services using the edge computing paradigm. The existing approaches split a DNN into two parts and deploy the two partitions to computation nodes at two edge computing tiers. Nonetheless, these methods overlook collaborative device-edge-cloud computation resources. Besides, previous algorithms demand the whole DNN re-partitioning to adapt to computation resource changes and network dynamics. Moreover, for resource-demanding convolutional layers, prior works do not give a parallel processing strategy without loss of accuracy at the edge side. To tackle these issues, we propose D3, a dynamic DNN decomposition system for synergistic inference without precision loss. The proposed system introduces a heuristic algorithm named horizontal partition algorithm to split a DNN into three parts. The algorithm can partially adjust the partitions at run time according to processing time and network conditions. At the edge side, a vertical separation module separates feature maps into tiles that can be independently run on different edge nodes in parallel. Extensive quantitative evaluation of five popular DNNs illustrates that D3 outperforms the state-of-the-art counterparts up to 3.4 times in end-to-end DNN inference time and reduces backbone network communication overhead up to 3.68 times.